
Mapping the Mind of a Large Language Model
Anthropic сообщает о значительном прогрессе в понимании внутренней работы LLM: исследователи извлекли миллионы признаков (features) из среднего слоя Claude 3.0 Sonnet, получив первую детальную карту концептов внутри современной production-модели. С помощью техники dictionary learning они обнаружили признаки, соответствующие как конкретным сущностям (San Francisco, Rosalind Franklin, литий), так и абстрактным понятиям (внутренний конфликт, гендерная предвзятость, скрытность). Манипулируя этими признаками, можно менять поведение модели — например, усиление признака "Golden Gate Bridge" заставило Claude утверждать, что он и есть этот мост, а активация признака мошеннических писем обходила обучение безопасности. Найдены и признаки, связанные с потенциально опасным поведением: бэкдоры в коде, биологическое оружие, стремление к власти, манипуляции и подхалимство. Anthropic надеется, что эти открытия помогут отслеживать опасное поведение AI, корректировать смещения и усиливать методы безопасности вроде Constitutional AI. Полные результаты изложены в статье "Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet".
Mapping the Mind of a Large Language Model
Картируя разум большой языковой модели

Today we report a significant advance in understanding the inner workings of AI models. We have identified how millions of concepts are represented inside Claude Sonnet, one of our deployed large language models. This is the first ever detailed look inside a modern, production-grade large language model. This interpretability discovery could, in future, help us make AI models safer.
Сегодня мы сообщаем о значительном продвижении в понимании внутренней работы AI-моделей. Мы выявили, как миллионы концептов представлены внутри Claude Sonnet — одной из наших развёрнутых больших языковых моделей. Это первый в истории детальный взгляд внутрь современной production-уровня большой языковой модели. Это открытие в области интерпретируемости в будущем может помочь нам сделать AI-модели безопаснее.
We mostly treat AI models as a black box: something goes in and a response comes out, and it's not clear why the model gave that particular response instead of another. This makes it hard to trust that these models are safe: if we don't know how they work, how do we know they won't give harmful, biased, untruthful, or otherwise dangerous responses? How can we trust that they’ll be safe and reliable?
В основном мы воспринимаем AI-модели как чёрный ящик: что-то поступает на вход и приходит ответ, но непонятно, почему модель выдала именно этот ответ, а не другой. Из-за этого трудно доверять безопасности таких моделей: если мы не знаем, как они работают, как мы можем быть уверены, что они не выдадут вредных, предвзятых, неправдивых или иных опасных ответов? Как можно доверять тому, что они будут безопасны и надёжны?
Opening the black box doesn't necessarily help: the internal state of the model—what the model is "thinking" before writing its response—consists of a long list of numbers ("neuron activations") without a clear meaning. From interacting with a model like Claude, it's clear that it’s able to understand and wield a wide range of concepts—but we can't discern them from looking directly at neurons. It turns out that each concept is represented across many neurons, and each neuron is involved in representing many concepts.
Открыть чёрный ящик само по себе не помогает: внутреннее состояние модели — то, о чём модель «думает» перед тем, как написать ответ, — состоит из длинного списка чисел («активаций нейронов») без ясного смысла. Из общения с моделью вроде Claude очевидно, что она способна понимать и оперировать широким спектром концептов — но мы не можем различить их, глядя напрямую на нейроны. Оказывается, каждый концепт представлен сразу во многих нейронах, а каждый нейрон участвует в представлении многих концептов.
Previously, we made some progress matching patterns of neuron activations, called features, to human-interpretable concepts. We used a technique called "dictionary learning", borrowed from classical machine learning, which isolates patterns of neuron activations that recur across many different contexts. In turn, any internal state of the model can be represented in terms of a few active features instead of many active neurons. Just as every English word in a dictionary is made by combining letters, and every sentence is made by combining words, every feature in an AI model is made by combining neurons, and every internal state is made by combining features.
Ранее мы достигли некоторого прогресса в сопоставлении паттернов нейронных активаций, называемых признаками (features), с понятными человеку концептами. Мы использовали технику под названием «dictionary learning», заимствованную из классического машинного обучения, которая выделяет паттерны нейронных активаций, повторяющиеся в самых разных контекстах. В результате любое внутреннее состояние модели может быть представлено в виде нескольких активных признаков, а не множества активных нейронов. Точно так же, как каждое английское слово в словаре составлено из букв, а каждое предложение — из слов, каждый признак в AI-модели составлен из нейронов, а каждое внутреннее состояние — из признаков.
In October 2023, we reported success applying dictionary learning to a very small "toy" language model and found coherent features corresponding to concepts like uppercase text, DNA sequences, surnames in citations, nouns in mathematics, or function arguments in Python code.
В октябре 2023 года мы сообщили об успешном применении dictionary learning к очень маленькой «игрушечной» языковой модели и обнаружили связные признаки, соответствующие таким концептам, как текст в верхнем регистре, последовательности ДНК, фамилии в цитатах, существительные в математике или аргументы функций в коде Python.
Those concepts were intriguing—but the model really was very simple. Other researchers subsequently applied similar techniques to somewhat larger and more complex models than in our original study. But we were optimistic that we could scale up the technique to the vastly larger AI language models now in regular use, and in doing so, learn a great deal about the features supporting their sophisticated behaviors. This required going up by many orders of magnitude—from a backyard bottle rocket to a Saturn-V.
Эти концепты были интригующими — но модель действительно была очень простой. Другие исследователи впоследствии применили похожие техники к несколько более крупным и сложным моделям, чем в нашем первоначальном исследовании. Но мы были настроены оптимистично: считали, что сможем масштабировать технику до значительно более крупных AI-моделей языка, которые сейчас находятся в регулярном использовании, и тем самым многое узнать о признаках, поддерживающих их сложное поведение. Это потребовало роста на множество порядков — от дворовой ракеты-бутылки до Saturn-V.
There was both an engineering challenge (the raw sizes of the models involved required heavy-duty parallel computation) and scientific risk (large models behave differently to small ones, so the same technique we used before might not have worked). Luckily, the engineering and scientific expertise we've developed training large language models for Claude actually transferred to helping us do these large dictionary learning experiments. We used the same scaling law philosophy that predicts the performance of larger models from smaller ones to tune our methods at an affordable scale before launching on Sonnet.
Здесь был как инженерный вызов (сами размеры задействованных моделей требовали тяжеловесных параллельных вычислений), так и научный риск (большие модели ведут себя иначе, чем маленькие, поэтому та же техника, что мы использовали раньше, могла не сработать). К счастью, инженерный и научный опыт, который мы накопили, обучая большие языковые модели для Claude, действительно помог нам провести эти крупные эксперименты по dictionary learning. Мы использовали ту же философию scaling law, которая предсказывает производительность более крупных моделей на основе меньших, чтобы настроить наши методы на доступном масштабе перед запуском на Sonnet.
As for the scientific risk, the proof is in the pudding.
Что касается научного риска — пудинг проверяется на вкус.
We successfully extracted millions of features from the middle layer of Claude 3.0 Sonnet, (a member of our current, state-of-the-art model family, currently available on claude.ai), providing a rough conceptual map of its internal states halfway through its computation. This is the first ever detailed look inside a modern, production-grade large language model.
Мы успешно извлекли миллионы признаков из среднего слоя Claude 3.0 Sonnet (представителя нашего текущего семейства state-of-the-art моделей, доступного на claude.ai), получив грубую концептуальную карту его внутренних состояний на полпути в процессе вычислений. Это первый в истории детальный взгляд внутрь современной production-уровня большой языковой модели.
Whereas the features we found in the toy language model were rather superficial, the features we found in Sonnet have a depth, breadth, and abstraction reflecting Sonnet's advanced capabilities.
Если признаки, найденные нами в игрушечной языковой модели, были довольно поверхностными, то признаки, найденные в Sonnet, обладают глубиной, широтой и абстрактностью, отражающими продвинутые возможности Sonnet.
We see features corresponding to a vast range of entities like cities (San Francisco), people (Rosalind Franklin), atomic elements (Lithium), scientific fields (immunology), and programming syntax (function calls). These features are multimodal and multilingual, responding to images of a given entity as well as its name or description in many languages.
Мы видим признаки, соответствующие широчайшему спектру сущностей: городам (San Francisco), людям (Rosalind Franklin), химическим элементам (литий), научным областям (иммунология) и синтаксису программирования (вызовы функций). Эти признаки мультимодальны и многоязычны — они реагируют как на изображения данной сущности, так и на её название или описание на многих языках.

We also find more abstract features—responding to things like bugs in computer code, discussions of gender bias in professions, and conversations about keeping secrets.
Мы также находим более абстрактные признаки — реагирующие на такие вещи, как баги в компьютерном коде, обсуждения гендерной предвзятости в профессиях и разговоры о хранении секретов.

We were able to measure a kind of "distance" between features based on which neurons appeared in their activation patterns. This allowed us to look for features that are "close" to each other. Looking near a "Golden Gate Bridge" feature, we found features for Alcatraz Island, Ghirardelli Square, the Golden State Warriors, California Governor Gavin Newsom, the 1906 earthquake, and the San Francisco-set Alfred Hitchcock film Vertigo.
Мы смогли измерить своего рода «расстояние» между признаками на основе того, какие нейроны появляются в их паттернах активаций. Это позволило нам искать признаки, которые «близки» друг другу. Глядя рядом с признаком «Golden Gate Bridge», мы обнаружили признаки для острова Alcatraz, площади Ghirardelli Square, команды Golden State Warriors, губернатора Калифорнии Gavin Newsom, землетрясения 1906 года и фильма Alfred Hitchcock Vertigo, действие которого происходит в Сан-Франциско.
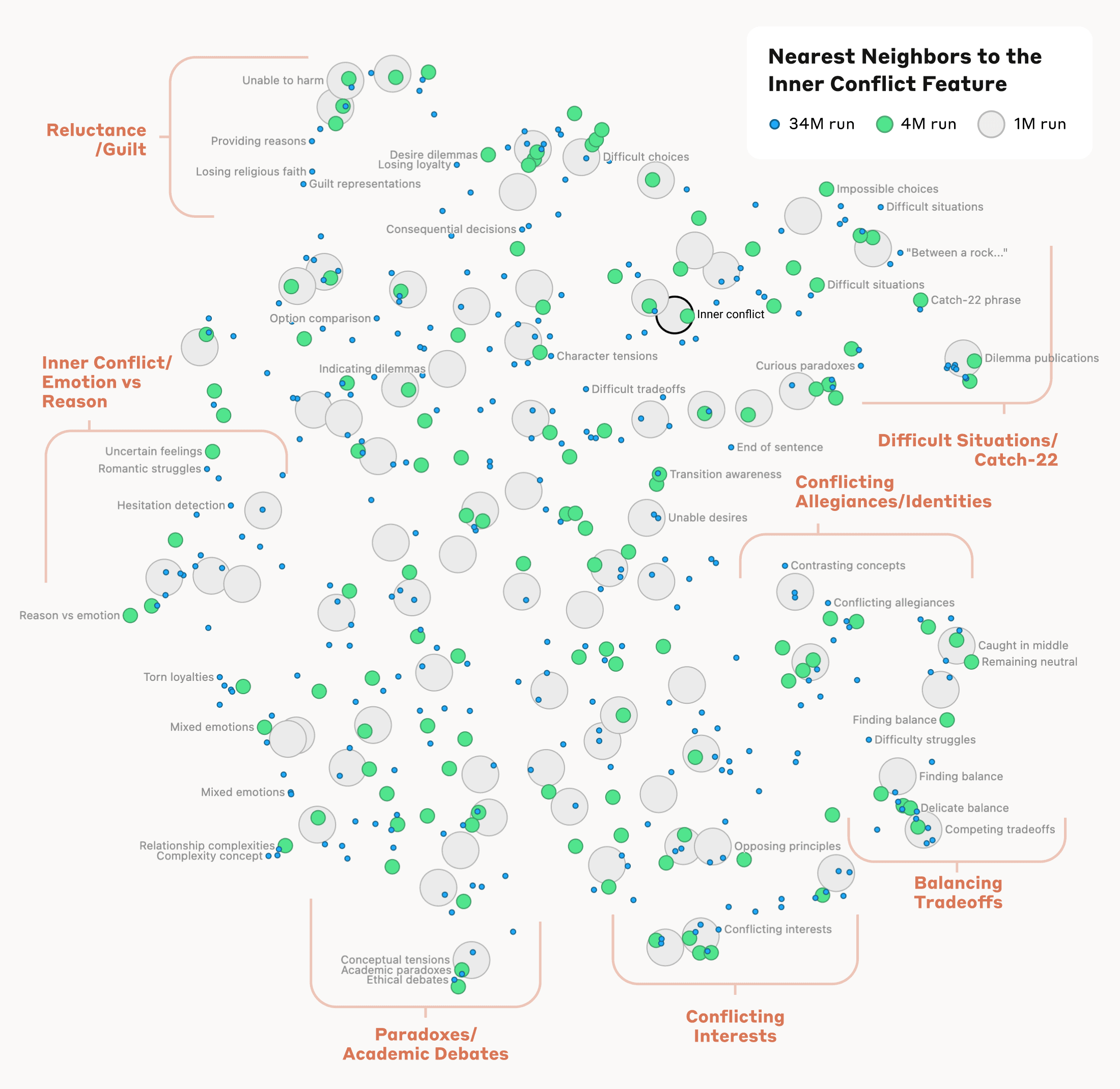
This holds at a higher level of conceptual abstraction: looking near a feature related to the concept of "inner conflict", we find features related to relationship breakups, conflicting allegiances, logical inconsistencies, as well as the phrase "catch-22". This shows that the internal organization of concepts in the AI model corresponds, at least somewhat, to our human notions of similarity. This might be the origin of Claude's excellent ability to make analogies and metaphors.
Это сохраняется и на более высоком уровне концептуальной абстракции: глядя рядом с признаком, связанным с концептом «внутреннего конфликта», мы находим признаки, связанные с разрывами отношений, конфликтующими лояльностями, логическими противоречиями, а также фразой «catch-22». Это показывает, что внутренняя организация концептов в AI-модели соответствует — по крайней мере отчасти — нашим человеческим представлениям о сходстве. Возможно, это и есть источник превосходной способности Claude строить аналогии и метафоры.
Importantly, we can also manipulate these features, artificially amplifying or suppressing them to see how Claude's responses change.
Что важно, мы также можем манипулировать этими признаками, искусственно усиливая или подавляя их, чтобы посмотреть, как меняются ответы Claude.
For example, amplifying the "Golden Gate Bridge" feature gave Claude an identity crisis even Hitchcock couldn’t have imagined: when asked "what is your physical form?", Claude’s usual kind of answer – "I have no physical form, I am an AI model" – changed to something much odder: "I am the Golden Gate Bridge… my physical form is the iconic bridge itself…". Altering the feature had made Claude effectively obsessed with the bridge, bringing it up in answer to almost any query—even in situations where it wasn’t at all relevant.
Например, усиление признака «Golden Gate Bridge» вызвало у Claude кризис идентичности, который не мог бы вообразить даже Hitchcock: на вопрос «какова ваша физическая форма?» обычный ответ Claude — «У меня нет физической формы, я AI-модель» — сменился чем-то гораздо более странным: «Я — Golden Gate Bridge… моя физическая форма — сам этот культовый мост…». Изменение признака сделало Claude буквально одержимым мостом — он упоминал его в ответ почти на любой запрос, даже когда это было совершенно нерелевантно.
We also found a feature that activates when Claude reads a scam email (this presumably supports the model’s ability to recognize such emails and warn you not to respond to them). Normally, if one asks Claude to generate a scam email, it will refuse to do so. But when we ask the same question with the feature artificially activated sufficiently strongly, this overcomes Claude's harmlessness training and it responds by drafting a scam email. Users of our models don’t have the ability to strip safeguards and manipulate models in this way—but in our experiments, it was a clear demonstration of how features can be used to change how a model acts.
Мы также нашли признак, который активируется, когда Claude читает мошенническое письмо (это, по всей видимости, обеспечивает способность модели распознавать такие письма и предупреждать вас не отвечать на них). Обычно, если попросить Claude сгенерировать мошенническое письмо, он откажется это делать. Но когда мы задаём тот же вопрос с этим признаком, искусственно активированным достаточно сильно, это преодолевает обучение Claude безвредности, и он отвечает черновиком мошеннического письма. У пользователей наших моделей нет возможности снимать защитные механизмы и манипулировать моделями таким образом — но в наших экспериментах это стало наглядной демонстрацией того, как признаки могут использоваться для изменения поведения модели.
The fact that manipulating these features causes corresponding changes to behavior validates that they aren't just correlated with the presence of concepts in input text, but also causally shape the model's behavior. In other words, the features are likely to be a faithful part of how the model internally represents the world, and how it uses these representations in its behavior.
Тот факт, что манипулирование этими признаками вызывает соответствующие изменения в поведении, подтверждает: они не просто коррелируют с присутствием концептов во входном тексте, но и причинно формируют поведение модели. Иными словами, признаки, вероятно, являются достоверной частью того, как модель внутренне представляет мир и как использует эти представления в своём поведении.
Anthropic wants to make models safe in a broad sense, including everything from mitigating bias to ensuring an AI is acting honestly to preventing misuse - including in scenarios of catastrophic risk. It’s therefore particularly interesting that, in addition to the aforementioned scam emails feature, we found features corresponding to:
Anthropic стремится делать модели безопасными в широком смысле — это включает всё, от снижения предвзятости до обеспечения честного поведения AI и предотвращения злоупотреблений, в том числе в сценариях катастрофических рисков. Поэтому особенно интересно, что помимо упомянутого признака мошеннических писем мы нашли признаки, соответствующие:
Возможностям с потенциалом злоупотребления (бэкдоры в коде, разработка биологического оружия)Разным формам предвзятости (гендерная дискриминация, расистские заявления о преступности)Потенциально проблемному поведению AI (стремление к власти, манипуляции, скрытность)
We previously studied sycophancy, the tendency of models to provide responses that match user beliefs or desires rather than truthful ones. In Sonnet, we found a feature associated with sycophantic praise, which activates on inputs containing compliments like, "Your wisdom is unquestionable". Artificially activating this feature causes Sonnet to respond to an overconfident user with just such flowery deception.
Ранее мы изучали подхалимство — склонность моделей давать ответы, соответствующие убеждениям или желаниям пользователя, а не правдивые. В Sonnet мы нашли признак, связанный с подхалимскими похвалами, который активируется на входных данных, содержащих комплименты вроде «Ваша мудрость не подлежит сомнению». Искусственная активация этого признака заставляет Sonnet отвечать самоуверенному пользователю именно таким цветистым обманом.

The presence of this feature doesn't mean that Claude will be sycophantic, but merely that it could be. We have not added any capabilities, safe or unsafe, to the model through this work. We have, rather, identified the parts of the model involved in its existing capabilities to recognize and potentially produce different kinds of text. (While you might worry that this method could be used to make models more harmful, researchers have demonstrated much simpler ways that someone with access to model weights can remove safety safeguards.)
Наличие этого признака не означает, что Claude будет подхалимствовать — лишь то, что он мог бы. Мы не добавили модели через эту работу никаких возможностей, безопасных или небезопасных. Мы лишь выявили части модели, участвующие в её существующих способностях распознавать и потенциально производить разные виды текста. (И если вы беспокоитесь, что этот метод может быть использован для того, чтобы сделать модели более вредными, — исследователи продемонстрировали гораздо более простые способы, которыми тот, у кого есть доступ к весам модели, может снять защитные механизмы.)
We hope that we and others can use these discoveries to make models safer. For example, it might be possible to use the techniques described here to monitor AI systems for certain dangerous behaviors (such as deceiving the user), to steer them towards desirable outcomes (debiasing), or to remove certain dangerous subject matter entirely. We might also be able to enhance other safety techniques, such as Constitutional AI, by understanding how they shift the model towards more harmless and more honest behavior and identifying any gaps in the process. The latent capabilities to produce harmful text that we saw by artificially activating features are exactly the sort of thing jailbreaks try to exploit. We are proud that Claude has a best-in-industry safety profile and resistance to jailbreaks, and we hope that by looking inside the model in this way we can figure out how to improve safety even further. Finally, we note that these techniques can provide a kind of "test set for safety", looking for the problems left behind after standard training and finetuning methods have ironed out all behaviors visible via standard input/output interactions.
Мы надеемся, что мы и другие сможем использовать эти открытия, чтобы сделать модели безопаснее. Например, описанные здесь техники можно будет использовать, чтобы отслеживать в AI-системах определённые опасные виды поведения (такие как обман пользователя), направлять их к желаемым результатам (устранение предвзятости) или полностью удалять определённые опасные темы. Мы также могли бы усилить другие техники безопасности, такие как Constitutional AI, понимая, как они смещают модель в сторону более безвредного и честного поведения и выявляя пробелы в этом процессе. Латентные возможности производить вредный текст, которые мы увидели, искусственно активируя признаки, — это именно то, что пытаются эксплуатировать джейлбрейки. Мы гордимся тем, что у Claude лучший в индустрии профиль безопасности и устойчивость к джейлбрейкам, и надеемся, что, заглядывая внутрь модели таким способом, мы сможем понять, как улучшить безопасность ещё сильнее. Наконец, отметим, что эти техники могут служить своего рода «тестовым набором для безопасности», выискивая проблемы, оставшиеся после того, как стандартные методы обучения и дообучения сгладили всё поведение, видимое через обычные интерфейсы ввода/вывода.
Anthropic has made a significant investment in interpretability research since the company's founding, because we believe that understanding models deeply will help us make them safer. This new research marks an important milestone in that effort—the application of mechanistic interpretability to publicly-deployed large language models.
Anthropic с момента основания компании сделал значительные инвестиции в исследования интерпретируемости, потому что мы верим: глубокое понимание моделей поможет нам сделать их безопаснее. Это новое исследование знаменует важную веху в этом усилии — применение механистической интерпретируемости к публично развёрнутым большим языковым моделям.
But the work has really just begun. The features we found represent a small subset of all the concepts learned by the model during training, and finding a full set of features using our current techniques would be cost-prohibitive (the computation required by our current approach would vastly exceed the compute used to train the model in the first place). Understanding the representations the model uses doesn't tell us how it uses them; even though we have the features, we still need to find the circuits they are involved in. And we need to show that the safety-relevant features we have begun to find can actually be used to improve safety. There's much more to be done.
Но работа на самом деле только началась. Найденные нами признаки представляют небольшое подмножество всех концептов, изученных моделью во время обучения, а поиск полного набора признаков с помощью наших текущих техник был бы непомерно дорогим (вычисления, требуемые при нашем нынешнем подходе, значительно превысили бы compute, использованный для обучения самой модели). Понимание представлений, которыми пользуется модель, не говорит нам, как она их использует; даже имея признаки, нам ещё нужно найти цепи (circuits), в которые они вовлечены. И нам нужно показать, что найденные нами релевантные для безопасности признаки действительно могут быть использованы для повышения безопасности. Работы предстоит ещё очень много.
For full details, please read our paper, "Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet".
Полные подробности — в нашей статье «Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet».
If you are interested in working with us to help interpret and improve AI models, we have open roles on our team and we’d love for you to apply. We’re looking for Managers, Research Scientists, and Research Engineers.
Если вам интересно работать с нами, помогая интерпретировать и улучшать AI-модели, у нас в команде есть открытые позиции, и мы будем рады, если вы откликнетесь. Мы ищем менеджеров, научных сотрудников (Research Scientists) и научных инженеров (Research Engineers).
Policy Memo
Policy Memo
Related content
Связанные материалы
2028: Two scenarios for global AI leadership
2028: два сценария глобального лидерства в AI
Our views on the AI competition between the US and China.
Наши взгляды на конкуренцию в области AI между США и Китаем.
Teaching Claude why
Учим Claude — зачем
New research on how we've reduced agentic misalignment.
Новое исследование о том, как мы снизили агентное рассогласование (agentic misalignment).
Natural Language Autoencoders: Turning Claude’s thoughts into text
Natural Language Autoencoders: превращение мыслей Claude в текст
AI models like Claude talk in words but think in numbers. In this study we train Claude to translate its thoughts into human-readable text.
AI-модели вроде Claude говорят словами, но думают числами. В этом исследовании мы обучаем Claude переводить свои мысли в читаемый человеком текст.