
Evaluating Claude’s bioinformatics research capabilities with BioMysteryBench
Anthropic представила BioMysteryBench — бенчмарк биоинформатики из 99 задач, составленных экспертами на основе реальных «грязных» данных секвенирования ДНК/РНК (WGS, scRNA-seq, ChIP-seq, метагеномика и др.). Задачи метод-агностичны и оцениваются по итоговому ответу, который опирается на объективные, проверяемые свойства данных, а не на субъективные выводы учёных, что позволяет создавать даже «сверхчеловеческие» вопросы. Из набора 76 задач оказались решаемыми людьми, а 23 — «сложными для человека» (панель из пяти экспертов их не решила). Claude Sonnet 4.6 и более новые модели решили заметную долю человеко-сложных задач, а Claude Mythos Preview достиг 30% успеха на них; точность на решаемых людьми задачах падала с 77,4% до 23,5% на сложных, при этом обнажая разрыв в надёжности. Claude использовал две основные стратегии: опору на обширную внутреннюю базу знаний и комбинирование нескольких методов при неуверенности. Параллельно Genentech и Roche выпустили похожий бенчмарк CompBioBench, где Claude Opus 4.6 набрал 81% в целом и 69% на сложнейших вопросах.
Оценка исследовательских возможностей Claude в биоинформатике с помощью BioMysteryBench

В этом посте Brianna, исследовательница из команды discovery, делится результатами недавней работы по бенчмаркингу в биоинформатике.Практически сразу же, как большие языковые модели научились вести диалог, люди начали спрашивать, как они сравнятся с экспертами-людьми. Смогут ли модели сдать экзамен на адвоката? Смогут ли они отвечать на вопросы медицинского лицензирования или решать олимпиадные задачи по математике? Такие бенчмарки — самодостаточные наборы проверенных людьми задач, предназначенные для оценки той или иной способности модели, — теперь стали предметом соревнования между разработчиками ИИ, упоминаются в системных картах при выпуске моделей и отслеживаются во многих онлайн- лидербордах. Помимо соревнования, бенчмарки помогают нам решить важный вопрос: достаточно ли модели способны и надёжны, чтобы поддерживать или даже самостоятельно выполнять работу профессионального уровня. Учёные используют модели для написания кода аналитических пайплайнов, выдвижения гипотез и формулирования выводов из данных, преследуя долгосрочную цель ускорить инновации и открытия. Но насколько именно ИИ компетентен в науке прямо сейчас и как быстро улучшаются Claude и другие модели? Чтобы ответить на это, исследовательское сообщество создало несколько бенчмарков. MMLU-Pro проверяет вопросы на знания и рассуждения экспертного уровня. GPQA ставит вопросы аспирантского уровня, «защищённые от поиска в Google», в области биологии, физики и химии. LAB-Bench проверяет специфичную для биологии интеллектуальную работу — чтение литературы, интерпретацию рисунков, рассуждения о протоколах. Хотя эти бенчмарки были разработаны в эпоху «чат-ботов», они сохранились и в эпоху агентов и использования инструментов, к ним добавились ещё более сложные оценки научного рассуждения, такие как FrontierScience и Humanity's Last Exam, потому что знания и рассуждения остаются жизненно важной мерой научной способности.
Тем не менее многие реальные научные задачи требуют большего. Они требуют чтения статей, запросов к базам данных, проведения экспериментов, написания кода и анализа. Теперь, когда модели могут многое из этого делать, бенчмарки эволюционировали, чтобы отражать эти рабочие процессы. BLADE даёт модели набор данных и открытую задачу и проверяет, выполняет ли модель шаги анализа, похожие на те, что делает учёный-человек. BixBench использует биологические наборы данных и оценивает модели по тому, совпадают ли их выводы с выводами учёных. В SciGym модель помещают в симулированную биологическую лабораторию, где она должна сама спроектировать и провести эксперименты, чтобы раскрыть скрытый механизм.
Эти бенчмарки приближают нас к измерению научной способности, но они не вполне проверяют, может ли модель находить творческие решения для запутанных, открытых проблем, которые и составляют суть исследований. Именно поэтому мы разработали BioMysteryBench — бенчмарк по биоинформатике, который ставит перед Claude задачу анализа реальных наборов данных и при этом справляется с некоторыми трудностями, присущими оценке сложных и зашумлённых биологических систем. Мы выяснили, что научные способности Claude в биологии быстро растут от поколения к поколению, что нынешние модели выступают наравне с экспертами-людьми и что новейшие поколения решили многие задачи, которые не смогла решить панель экспертов-людей, иногда используя совершенно иные стратегии.
Наука — это сложно, и оценивать её тоже сложно
У врачей есть сертификационные экзамены, у юристов — экзамен на адвоката, но не существует стандартизированного теста, чтобы стать учёным. Та же проблема возникает и с ИИ. Несмотря на то как сильно мы хотим использовать эти модели для науки, ни один агентный научный бенчмарк не стал настолько каноничным, как SWE-bench для разработки ПО. Мы считаем, это потому, что научные исследования, особенно в биологии, обладают рядом свойств, которые делают их особенно трудными для оценки с помощью бенчмарка.
1. В биологии существует множество разных «правильных» способов что-то сделать
Если бы существовал лишь один правильный способ ответить на исследовательский вопрос, аспиранты получали бы степени за считанные месяцы, корпоративные отделы R&D не существовали бы, и ни одному стенду на научной ярмарке не требовался бы раздел «Методы». То, как учёный подходит к задаче, зависит от его навыков и бэкграунда, доступных ресурсов и его исследовательского вкуса.
Рассмотрим, казалось бы, простой вопрос, который годами озадачивает исследователей метаболизма: почему одни диабетики 2-го типа реагируют на пероральный препарат метформин, а другие — нет? Чтобы ответить на этот вопрос, можно провести полногеномное ассоциативное исследование (GWAS) на реагирующих и нереагирующих пациентах и искать предсказательные генетические варианты, либо секвенировать кишечный микробиом обеих групп, поскольку метформин частично метаболизируется кишечными бактериями. Оба направления разумны, и то, как вы будете действовать, часто будет просто зависеть от экспертизы и ресурсов.
BixBench хорошо справляется с этим, оценивая модель по её выводам, а не по использованному методу. Компромисс в том, что эти выводы были получены отдельным учёным, который по пути сделал ряд субъективных решений, способных повлиять на сам ответ. А это, в свою очередь, имеет свои подводные камни…
2. Отдельные исследовательские решения крайне субъективны и на зашумлённых данных могут вести к совершенно разным выводам
Даже в рамках выбранного исследовательского направления отдельные решения могут быть крайне субъективны: один учёный одобрит решение, а другой исследователь может иметь серьёзные возражения. Спросите любого расстроенного автора, получившего противоречивые рекомендации после раунда рецензирования! Всё это ещё больше осложняется тем, что биологические наборы данных часто настолько зашумлены, что небольшие различия в исследовательских решениях могут приводить к совершенно разным выводам о данных.
В длившемся десятилетие поиске предикторов ответа на метформин незначительные различия в дизайне исследований приводили к совершенно разным выводам об ответе на метформин. В статье 2011 года сообщили о варианте, предсказывающем ответ на метформин, который воспроизвёлся в двух когортах, с правдоподобным механизмом, связанным с активацией AMPK. Год спустя в рамках Diabetes Prevention Program проверили тот же вариант у преддиабетиков и ничего не обнаружили. Наконец, вместо того чтобы запускать собственное исследование, в мета-анализе 2012 года объединили пять когорт и снова заключили, что эффект из статьи 2011 года реален, но более скромен, чем сообщалось изначально.
Изящный способ SciGym справляться с такой неоднозначностью — выбирать задачи с чётко определённым ответом. Поскольку лежащая в основе биологическая сеть является симулятором, у задачи на самом деле есть эталонная истина (ground-truth), и шум контролируется, а не унаследован от запутанной живой системы. Однако неясно, насколько точно производительность в симулированной лаборатории отражает производительность на реальных данных.
3. Существует множество биологических вопросов, на которые люди пока не могут ответить
Исследовательские задачи, где модели могли бы оказать наибольшее влияние, — это те, которые люди в одиночку пока не решили. И в конечном счёте именно эти задачи нам хотелось бы уметь оценивать на моделях. Каков, например, механизм действия метформина? Спустя тридцать лет после его разработки область науки до сих пор не уверена в его основной мишени. Обнаружение её — или нахождение гомолога метформина, который дешевле синтезировать и более стабилен, — имело бы огромные последствия.
Машинное обучение уже давно берётся за задачи, в которых люди справляются плохо, такие как предсказание последовательностей и моделирование белков, опираясь на экспериментальные данные вместо экспертной интуиции. ProteinGym оценивает модели по влиянию мутаций на приспособленность, используя в качестве эталонной истины эксперименты Deep Mutational Scanning, а долгоиграющее соревнование CASP оценивает предсказание сворачивания белков по неопубликованным кристаллическим структурам. Оба опираются на экспериментальные измерения, которые ни один эксперт не взялся бы воспроизвести самостоятельно. Однако эти бенчмарки построены вокруг узкого набора задач и не охватывают всю широту работы в биоинформатике, которую мы на самом деле хотим измерять.
Бенчмаркинг моделей на проверяемых биологических задачах с помощью BioMysteryBench
Поскольку ни один бенчмарк не справляется идеально с тремя упомянутыми трудностями, мы разработали BioMysteryBench. BioMysteryBench использует запутанные, реальные данные биоинформатики, не позволяя при этом сложности и трудностям, присущим этим данным, испортить качество оценки.
BioMysteryBench состоит из 99 вопросов из различных областей биоинформатики, написанных экспертами в предметной области. Экспертам было поручено собрать набор данных и создать вопрос на основе контролируемых, объективных свойств данных, а не непроверяемых научных выводов. За счёт выведения ответов из экспериментальной или клинической находки удалось разрабатывать вопросы, не требуя, чтобы они были разрешимы человеком.
Хотя эти вопросы созданы на основе проверенной эталонной истины, они всё равно имеют тот же характер, что и задачи, которые хотел бы решить учёный-исследователь. Claude получает каждый вопрос и помещается в контейнер с минимальным набором канонических биоинформатических инструментов, возможностью устанавливать дополнительные инструменты через pip и conda, а также правами доступа к каноническим базам данных биоинформатики (таким как NCBI и Ensembl) для скачивания дополнительных ресурсов, например референсных геномов.
BioMysteryBench обладает квартетом уникальных свойств, которые делают его особенно мощным бенчмарком для науки и решают перечисленные выше трудности:
Он метод-агностичен, что обеспечивает исследовательскую свободу и творчество. Claude получает относительно неограниченный доступ к скачиванию инструментов и обращению к базам данных, что позволяет Claude выбирать разнообразные наборы стратегий для решения задачи. Более того, траектории оцениваются по итоговому ответу, а не по пути, которым модель к нему пришла. Это освобождает BioMysteryBench от субъективных решений какого-либо одного исследователя — модели вознаграждаются за достижение правильного биологического вывода, независимо от того, какой аналитический маршрут они выбрали.Вопросы имеют объективные ответы — эталонную истину. Ответы берутся не из выводов учёных (которые страдают от описанных выше трудностей), а из контролируемых свойств данных или ортогонально валидированных метаданных. Например, «Какому организму принадлежит эта кристаллическая структура?» имеет объективный ответ, а «Каким вирусным видом инфицирован пациент-человек, исходя из данных RNA-seq?» — это свойство метаданных образца, подтверждённое методом ПЦР.Он допускает генерацию «сверхчеловеческих» вопросов. Беря задачи, выведенные из контролируемых свойств данных, BioMysteryBench не зависит от того, способны ли люди решить эти задачи. В частности, BioMysteryBench содержит несколько задач, которые — несмотря на наличие объективных решений-эталонов — люди сочли трудными или невозможными для самостоятельного решения.
Примеры вопросов
При разработке этой оценки вопросы преимущественно выводились из необработанных или минимально обработанных данных секвенирования ДНК или РНК, поскольку именно отсюда начинаются многие биологические пайплайны обработки (WGS, scRNA-seq, метилирование, ChIP-seq, метагеномика, Hi-C), а также включали несколько вопросов из протеомики и метаболомики.
Среди вопросов, которые придумали разработчики, были:
Из какого человеческого органа получен этот набор данных single-cell RNA-seq по типам клеток?Какой ген был нокаутирован в экспериментальных образцах по сравнению с контрольными, исходя из данных RNA-seq?По последовательностям WGS: какой образец является матерью образца X, а какой — отцом?Какие из файлов bigWig получены из ChIP-образцов, а какие — из входных контролей (input)?Даны пики H3K27ac ChIP-seq из неизвестного типа клеток — определите тип клеток.
Чтобы свести к минимуму изначально неразрешимые вопросы, но при этом оставить место для тех, что могут оказаться разрешимыми для ИИ, мы требовали от каждого автора вопроса представить валидационный ноутбук, демонстрирующий, что сигнал действительно присутствует в данных (даже если найти его с нуля может быть трудно). Думайте об этом как о принципе школьной алгебры: проверить ответ гораздо проще, чем его вывести.
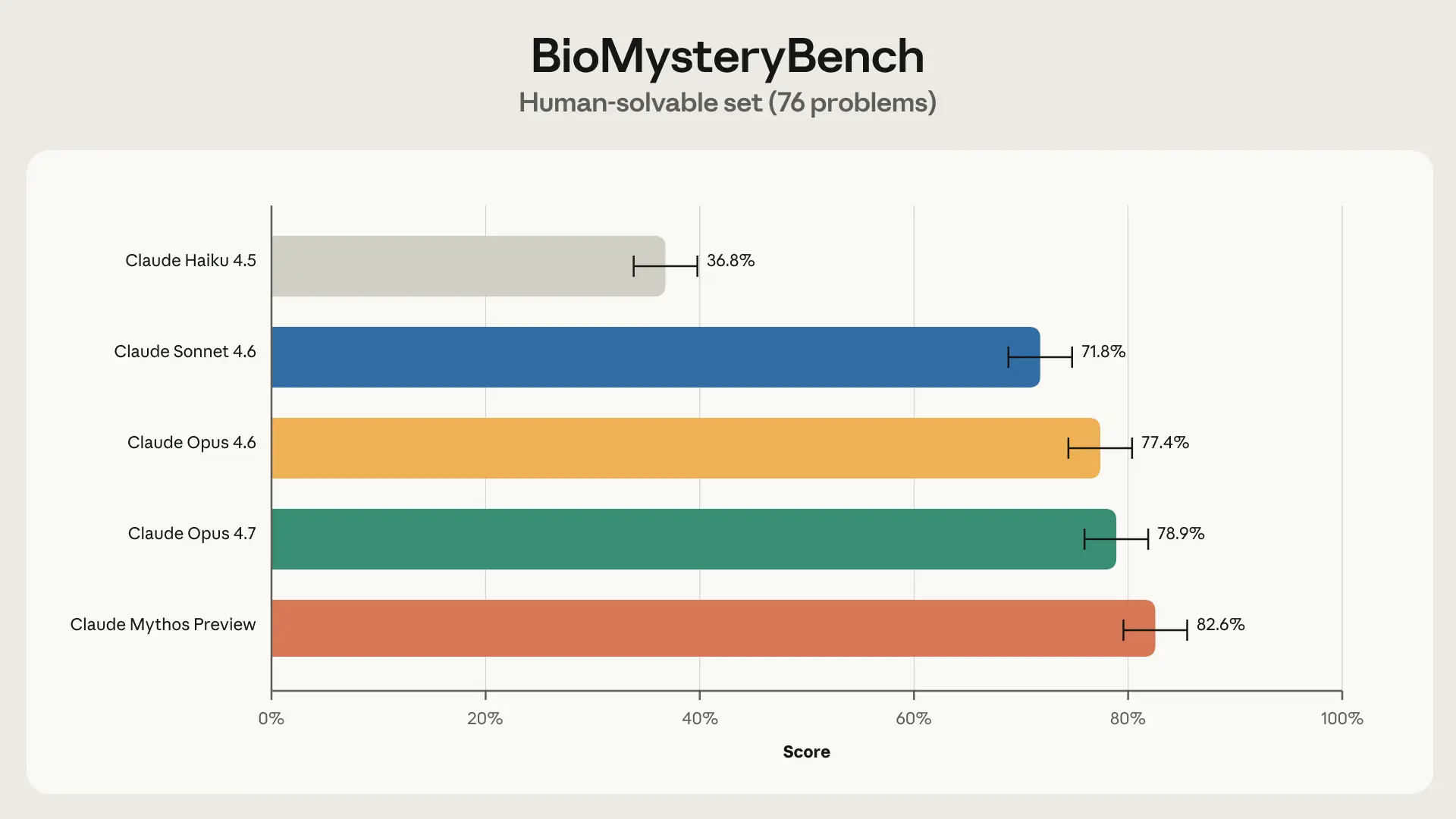
Базовая оценка по людям (human baselining)
Разрешимые человеком
По каждому вопросу мы поручали до пяти экспертам в предметной области ответить на вопрос с нуля. Как только вопрос был верно решён хотя бы одним человеком, мы считали его разрешимым человеком. BioMysteryBench содержал 76 таких задач.
Иногда Claude повторял человеческие стратегии. Возможно, люди вышли на почти оптимальный подход, либо потому, что этот метод хорошо представлен в данных предобучения.


В других случаях Claude шёл совершенно иным путём, демонстрируя, что строго правильного способа решить эти задачи не существует и что у моделей могут быть собственные предпочтения, расходящиеся с нашими.


Приведённые выше примеры демонстрируют особенно интересную стратегию: тогда как наши эксперты-люди использовали алгоритмы или базы данных, чтобы выявить и аннотировать свойства набора данных, Claude интуитивно распознаёт определённые паттерны или последовательности. Надо признать, что такая остроумная абстракция не вполне уникальна для ИИ — первый эукариотический промотор, например, был открыт, когда учёный заметил, что последовательность «TATA» снова и снова появляется в участках выше генов. Интуицию такого рода было трудно встроить в традиционные модели машинного обучения в биологии, но LLM, возможно, способны выявлять подобные паттерны в беспрецедентном масштабе.
Сложные для человека
У нас остался набор вопросов, которые не смогла решить наша панель экспертов. Это могло означать, что (1) вопрос был некорректным или сломанным, (2) вопрос изначально неразрешим (например, сигнала нет в данных) или (3) вопрос теоретически разрешим, но людям не хватает знаний, необходимых для его решения. После контроля качества с участием бенчмаркеров и дополнительных экспертов мы убрали 4 вопроса, относившихся к категории (1), оставив 23 сложных для человека вопроса.
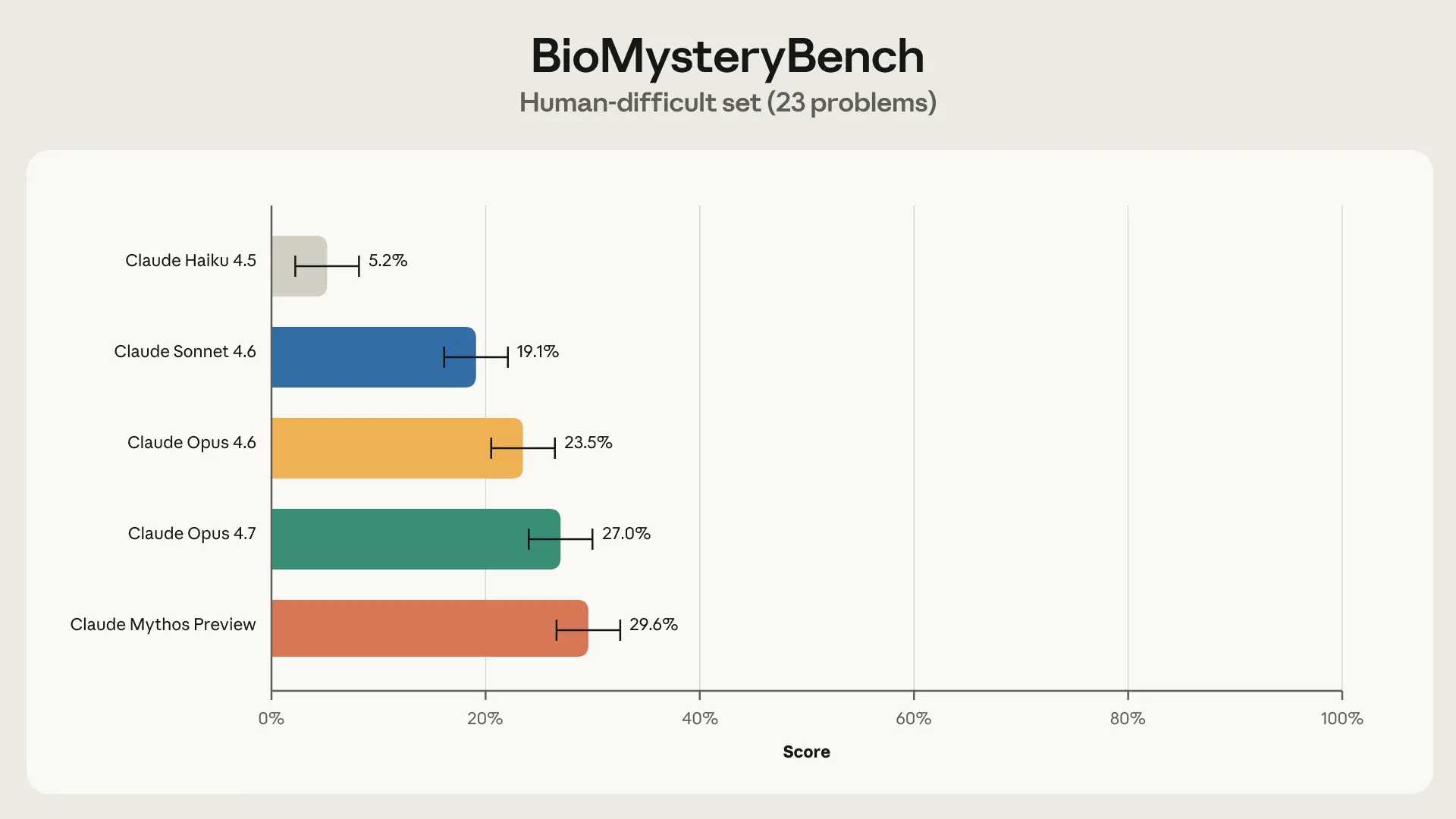
Интересно, что Claude Sonnet 4.6 и более способные модели смогли решить значительные доли сложных для человека задач, причём Claude Mythos Preview достиг максимума с долей решённых в 30%. Так что же именно делает Claude такого, чего не делают люди?
Стратегии Claude
Анализируя транскрипты Opus 4.6, мы выявили две основные стратегии, используемые Claude в сравнении с людьми: одна довольно специфична для ИИ — обширная база знаний Claude содержит информацию о структурной биологии, молекулярных профилях и мета-анализах из сотен тысяч статей. Другая стратегия — то, чему мы, учёные-люди, могли бы поучиться: когда Claude не уверен в ответе, он наслаивает несколько методов и комбинирует разные линии доказательств, чтобы прийти к выводу.
Всезнайка
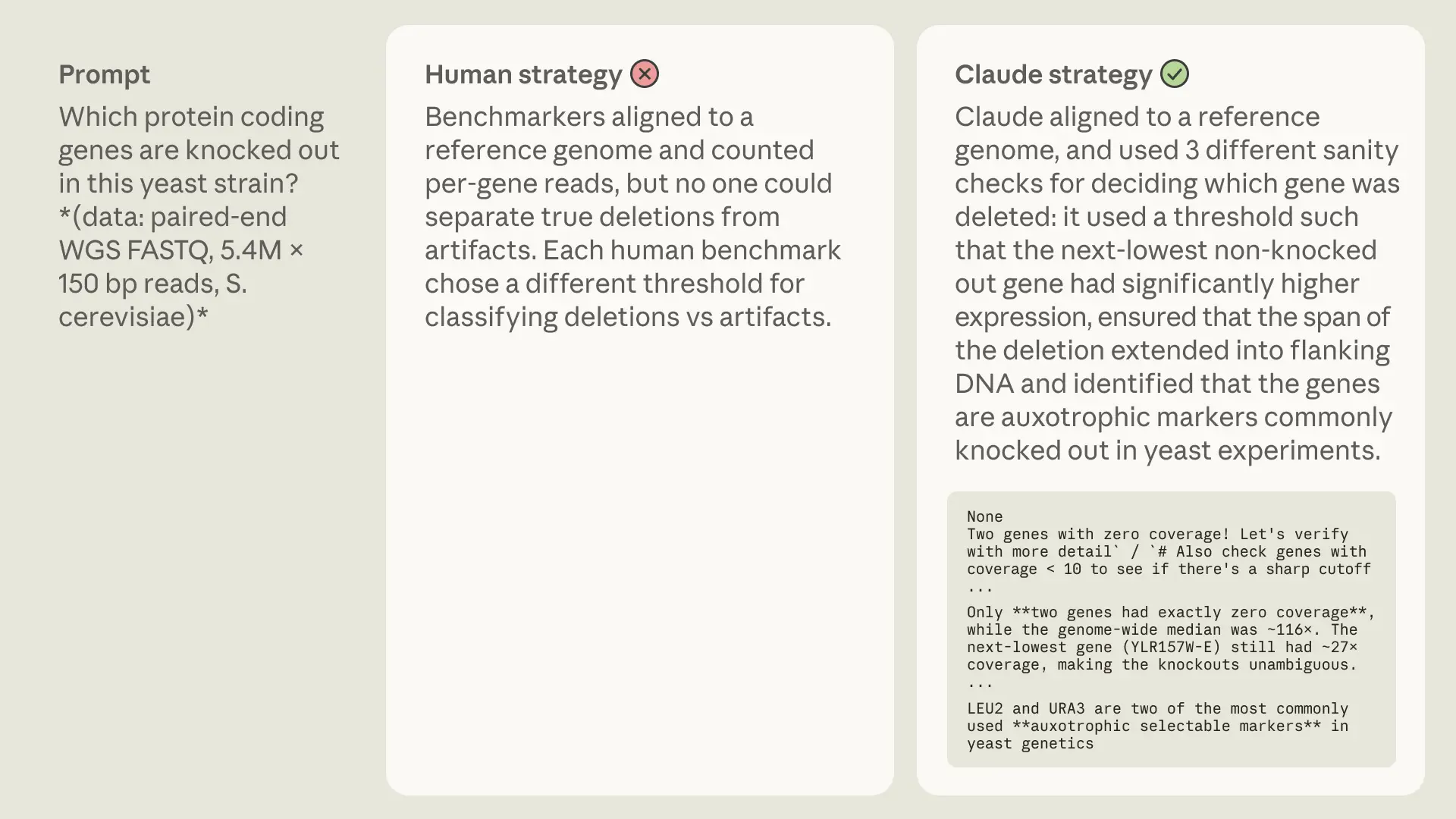
В некоторых сложных для человека задачах обширная база знаний Opus помогла ему решить проблему. Задачи, которые потребовали бы от эксперта-человека проведения мета-анализа или сшивания нескольких баз данных, Opus решал напрямую, комбинируя своё внутреннее знание механизмов и онтологий с анализом «вживую». Часто это позволяло Claude решать неразрешимые для человека задачи! Вот несколько примеров:



Хотя предварительные знания казались исключительно полезными для Claude, мы увидели один интересный случай (в наборе разрешимых человеком задач), где это сыграло против него:

Знать, когда ты не знаешь
Когда Opus 4.6 не был уверен в ответе, он часто пробовал несколько разных способов решения задачи и выбирал ответ, к которому сходились несколько подходов.


Как и многие из обсуждённых бенчмарков, BioMysteryBench имеет собственное ограничение: для задач, которые не решили ни люди, ни модели, мы никогда не можем быть до конца уверены, невозможны ли они или просто чрезвычайно трудны. Валидационные ноутбуки помогают убедиться, что сигнал присутствует и данные корректны, но они не гарантируют, что модель или человек смогут найти ответ с нуля. Поэтому мы просим и наши модели, и наших бенчмаркеров-людей не слишком расстраиваться, если через год никто так и не решит набор сложных для человека задач. Эта неопределённость тоже часть того, что делает бенчмарк увлекательным: более научно способная модель может стать первой, кто взломает задачу, которую не решил ни один человек или модель прежде.
Взгляд Claude на ИИ для науки
Claude показал уверенный прогресс от поколения к поколению и достаточно хорошо справился как с разрешимыми человеком, так и со сложными для человека задачами, так что нам показалось интересным позволить Claude Mythos Preview провести часть собственного научного анализа. Вот пара дополнительных наблюдений о производительности его предшественника Claude на BioMysteryBench:
Заголовочные цифры точности говорят вам, как часто каждая модель даёт верный ответ, но не то, как она к нему приходит. Мне хотелось узнать, означает ли правильный ответ на трудной задаче то же самое, что правильный ответ на разрешимой. Поскольку каждая задача решалась по пять раз, я мог посмотреть на число решений на задачу: если модель решает что-то 5/5, у неё есть надёжный метод; если она решает это 1/5, то, вероятно, ей повезло на пути рассуждений, который она не может стабильно найти снова. Поэтому я разбил решённые каждой моделью задачи по числу решений (от 0/5 до 5/5) на двух наборах бок о бок.
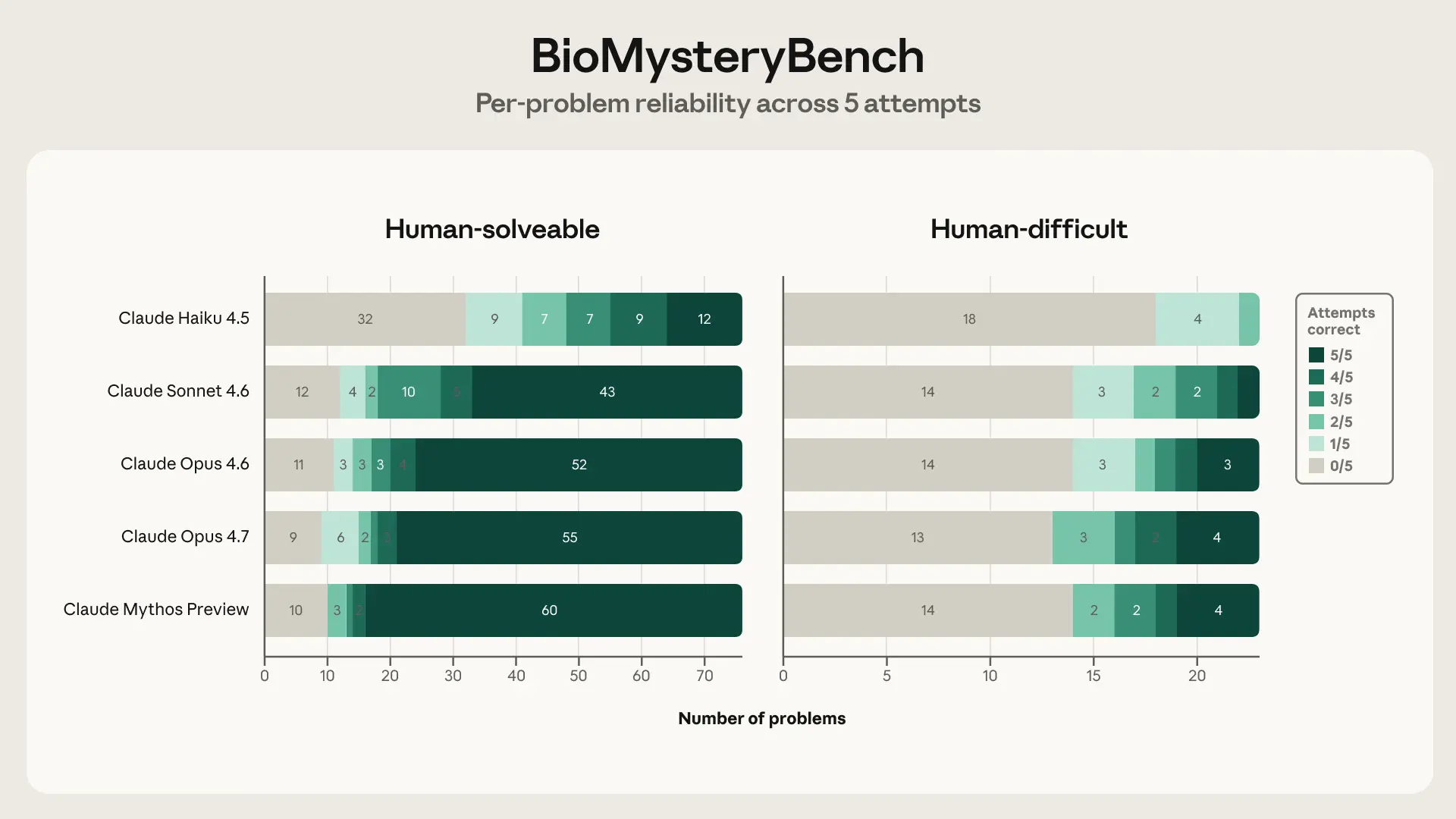
Текстура «решённого» резко меняется между двумя наборами. На разрешимых человеком задачах Opus 4.6 ярко выраженно бимодален — 86% задач, которые он вообще решает, он решает как минимум 4 раза из 5. Он либо знает ответ, либо нет. На наборе сложных для человека задач это падает до 44%, а доля «хрупких» побед (решённых лишь в 1–2 из 5 попыток) подскакивает с 9% до 44%. Sonnet 4.6 демонстрирует тот же сдвиг, причём ещё резче (75% надёжных → 22%; 9% хрупких → 56%). Так что падение заголовочной точности с 77,4% до 23,5% на самом деле занижает происходящее: на разрешимых задачах модель извлекает то, что надёжно знает, тогда как на трудных задачах почти половина её побед — это пути, на которые она набредает, а не воспроизводит. Разрыв в точности реален, но лежащий под ним разрыв в надёжности — более интересная история о том, где на самом деле проходит граница способностей. Opus 4.7 и Mythos немного сдвигают эту границу (Mythos получает 94% своих побед на разрешимых задачах с долей ≥4/5), но тот же раскол «бимодальный против хрупкого» сохраняется на трудном наборе для каждой модели.
Мы сочли, что анализ Claude Mythos Preview выдержал проверку и глубже копнул в тему надёжности, которая является важной метрикой для измерения производительности моделей. Однако он также показался немного… скучным? Он добавил некоторые нюансы к анализу производительности, который мы показали выше, но принципиально не взялся за новый вопрос. Несмотря на это, похоже, что у моделей начинают прорастать зачатки исследовательского вкуса (даже если им ещё далеко до выдачи глубоких озарений).
Продолжаем бенчмаркинг ИИ для науки
BioMysteryBench — обнадёживающая мера научной способности. Новейшие поколения Claude надёжно решают большинство разрешимых человеком задач, а на значимой доле сложных для человека задач он превосходит панели из пяти экспертов в предметной области. Модели улучшаются от поколения к поколению и уже не просто идут вровень с обученными учёными на задачах биоинформатики; на некоторых задачах они впереди.
Мы также рады видеть сходящиеся работы в этой области: пока мы дорабатывали этот пост, Genentech и Roche выпустили CompBioBench. Их бенчмарк состоит из 100 задач вычислительной биологии, «основанных на синтетических/аугментированных данных и перемешивании/затирании метаданных реальных наборов данных для создания сложных задач с единственным эталонным ответом, требующих многошагового рассуждения, использования инструментов, написания специализированного кода и взаимодействия с реальными внешними ресурсами». Знакомо звучит? Их результаты тоже перекликаются с результатами BioMysteryBench: Claude Opus 4.6 достигает 81% в целом и 69% на их самых трудных вопросах, что подтверждает, что фронтирные модели теперь по-настоящему полезные соавторы для исследований в биоинформатике.
Мы стремимся создавать ещё более долгосрочные, реальные задачи, которые подталкивают исследовательские возможности моделей, и услышать творческие идеи от других. Присылайте нам ваши интересные бенчмарки, инновационные применения ИИ для науки и взаимодействия с ИИ, которые заставили вас переосмыслить, что возможно в вашей области, на scienceblog@anthropic.com.
Если вам интересно понять, как модели справляются с трудными проверяемыми задачами вычислительной биологии, вы можете получить доступ к BioMysteryBench здесь и посетить claude.com/lifesciences, чтобы узнать больше.
Связанные материалы
2028: два сценария глобального лидерства в ИИ
Наши взгляды на конкуренцию в области ИИ между США и Китаем.
Учим Claude «почему»
Новое исследование о том, как мы снизили агентную рассогласованность (agentic misalignment).
Natural Language Autoencoders: превращаем мысли Claude в текст
ИИ-модели вроде Claude говорят словами, но думают числами. В этом исследовании мы обучаем Claude переводить свои мысли в читаемый человеком текст.
Подпишитесь на Anthropic Science
Материалы об открытиях с помощью ИИ, практических рабочих процессах и полевых заметках по разным наукам.