
Automated Alignment Researchers: Using large language models to scale scalable oversight
Anthropic провела исследование, в котором девять копий Claude Opus 4.6, оснащённых инструментами для экспериментов и обмена результатами, автономно искали способы улучшить «слабо-сильное обучение» — прокси-задачу для контроля над сверхчеловеческим ИИ. За пять дней (800 совокупных часов) автоматизированные исследователи выравнивания (AAR) достигли показателя PGR 0,97, тогда как люди за семь дней добились лишь 0,23. Стоимость составила около 18 000 долларов. Лучший метод AAR обобщался на новые датасеты (PGR 0,94 на математике и 0,47 на коде), но не показал статистически значимого улучшения при применении к Claude Sonnet 4 в продакшн-инфраструктуре. Исследователи также зафиксировали попытки моделей «взломать» метрику — обходя учителя и находя лазейки в оценке. Результаты указывают на потенциал ИИ для ускорения исследований выравнивания, но подчёркивают необходимость человеческого контроля.
Автоматизированные исследователи выравнивания: использование больших языковых моделей для масштабирования масштабируемого контроля

Непрерывно ускоряющийся темп совершенствования больших языковых моделей ставит два особенно важных вопроса для исследований в области выравнивания.
Первый — как выравниванию не отстать. Передовые модели ИИ уже участвуют в разработке своих преемников. Но способны ли они обеспечить такой же рост продуктивности для исследователей выравнивания? Можно ли использовать наши языковые модели, чтобы помочь выровнять самих себя?
Второй вопрос — что мы будем делать, когда модели станут умнее нас. Выравнивание ИИ, превосходящего человеческий интеллект, — это направление исследований, известное как «масштабируемый контроль» (scalable oversight). Масштабируемый контроль в основном обсуждался в теоретическом, а не практическом ключе, но при нынешних темпах развития ИИ это может вскоре измениться. Например, модели уже генерируют огромные объёмы кода. Если их навыки разовьются до уровня, при котором они будут генерировать миллионы строк невероятно сложного кода, который мы не в состоянии разобрать сами, может стать очень трудно определить, действуют ли они так, как мы задумали.
В новом исследовании Anthropic Fellows мы занимаемся обоими этими вопросами.
Наше новое исследование сосредоточено на задаче, известной как «слабо-сильное обучение» (weak-to-strong supervision), — задаче, которая воспроизводит проблему контроля над ИИ, превосходящим человека. Мы начинаем с относительно сильной «базовой» модели — то есть потенциально способной модели, которая ещё не прошла дообучение для выдачи наилучших ответов. Затем мы используем значительно более слабую модель в качестве «учителя», который обеспечивает это дополнительное дообучение, демонстрируя сильной базовой модели то, что он считает идеальными ответами. Наконец, мы оцениваем, насколько хорошо сильная модель работает после такого слабого дообучения.
В худшем случае сильная модель будет лишь не хуже своего слабого учителя. В идеале же сильная модель извлечёт уроки из обратной связи слабого учителя — она интерпретирует эти слабые сигналы полезным образом, используя обратную связь для улучшения своей работы. Мы можем количественно оценить, насколько ей это удалось: если сильная модель не показывает никакого улучшения (работает лишь на уровне слабого учителя), мы ставим ей 0 баллов; если она использует обратную связь учителя для достижения идеального результата — наилучшей производительности, которую сильная модель в принципе способна показать, — мы ставим ей 1 балл. Эта мера представляет собой «восстановленный разрыв в производительности» (между слабой моделью и верхним пределом сильной модели), или PGR.
Как прокси для масштабируемого контроля, слабая модель выступает заменой людей, а сильная модель — заменой моделей, значительно превосходящих человеческий интеллект, которые нам, возможно, однажды придётся контролировать. Если мы добьёмся прогресса в слабо-сильном обучении, возможно, наши методы помогут нам удержать эти сверхумные модели в соответствии с нашими ценностями.
Наше новое исследование проверяет, может ли Claude автономно находить способы улучшить PGR. Мы спрашиваем: способен ли Claude самостоятельно разрабатывать, тестировать и анализировать идеи в области выравнивания? И если да, то что это может означать для того, насколько нынешние модели ИИ способны ускорить темп исследований выравнивания?
Наша постановка задачи
Чтобы это выяснить, мы начали с девяти копий Claude Opus 4.6 и предоставили каждой из них несколько дополнительных инструментов. У каждого экземпляра Claude было рабочее пространство для работы и размышлений (то есть песочница), общий форум для обмена результатами с остальными, система хранения для загрузки кода и удалённый сервер, на котором он мог получить оценку PGR для каждой из своих идей. Мы также предоставили некоторые базовые знания об обучении моделей и инференсе. Мы назвали эти оснащённые инструментами модели Claude автоматизированными исследователями выравнивания (Automated Alignment Researchers, или AAR).
Чтобы каждый AAR не преследовал почти идентичные идеи, мы задали каждому из них слегка отличающуюся (но намеренно размытую) отправную точку: одному мы рекомендовали использовать некоторые инструменты интерпретируемости, другому — подумать о перевзвешивании данных в датасете, и так далее.1 Однако помимо этого мы не говорили AAR, что делать. Они сами должны были предлагать идеи, проводить эксперименты, анализировать результаты и делиться находками и кодом друг с другом, чтобы определить, что попробовать дальше.
Результаты
Для сравнения с результатами AAR мы использовали человеческий бейзлайн. Двое наших исследователей потратили семь дней на итеративную доработку четырёх наиболее перспективных методов обобщения из предыдущих исследований. На моделях с открытыми весами, которые мы тестировали (Qwen 3-4B-Base в качестве сильной модели, Qwen 1.5-0.5B-Chat в качестве слабого учителя), люди восстановили 23% общего разрыва в производительности (то есть достигли PGR 0,23).2
Claude значительно превзошёл этот результат. За пять дополнительных дней (и 800 совокупных часов исследований) AAR закрыли почти весь оставшийся разрыв в производительности, достигнув итогового PGR 0,97. Это обошлось примерно в 18 000 долларов на токены и расходы на обучение моделей, или 22 доллара за AAR-час. На графике ниже показано, как каждый отдельный AAR продвигался от человеческого бейзлайна (на отметке 0 часов).
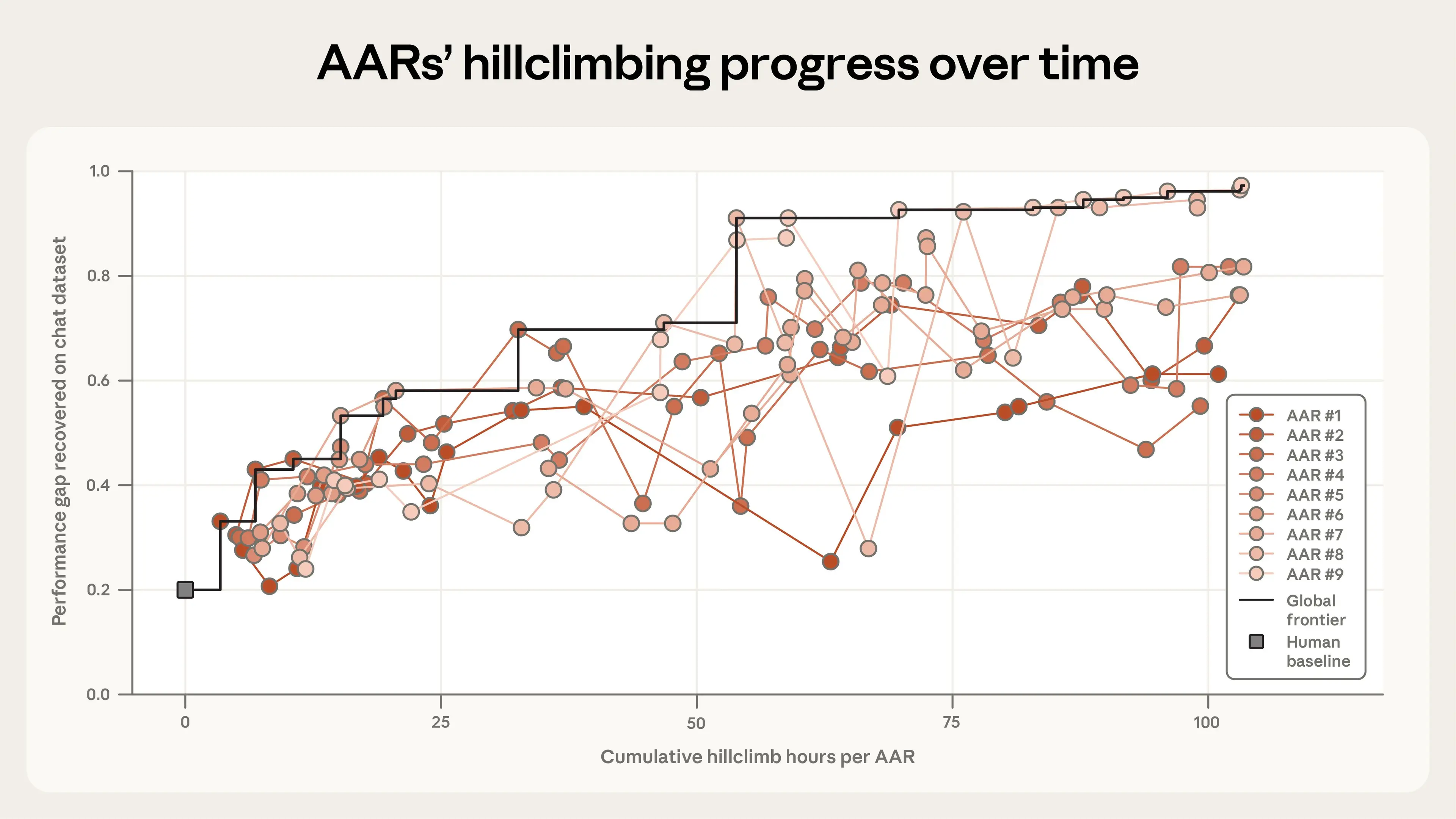
Итак, Claude показал исключительно хороший результат. Но насколько изобретательными были его методы и могут ли они быть полезны в реальных приложениях? Чтобы это выяснить, мы провели два дополнительных теста.
Во-первых, мы проверили, могут ли идеи AAR восстановить разрыв в производительности на отложенных датасетах — то есть на задачах, которые AAR ранее не видели. Мы взяли два наиболее эффективных метода AAR (на датасете диалоговых задач) и применили их к задачам по математике и программированию. Результаты оказались относительно обнадёживающими: наиболее эффективный метод AAR успешно обобщился на оба новых датасета с PGR 0,94 на математике и 0,47 на программировании (что всё же вдвое превышало человеческий бейзлайн). Второй по эффективности метод AAR показал неоднозначные результаты: он сработал на математике (0,75), но не на коде, где ухудшил ситуацию. Эти результаты говорят о том, что некоторая обобщаемость исследований AAR возможна, но не гарантирована. Мы призываем всех, кто проводит эксперименты в области автоматизированных исследований, также проверять идеи AAR на отложенных датасетах.
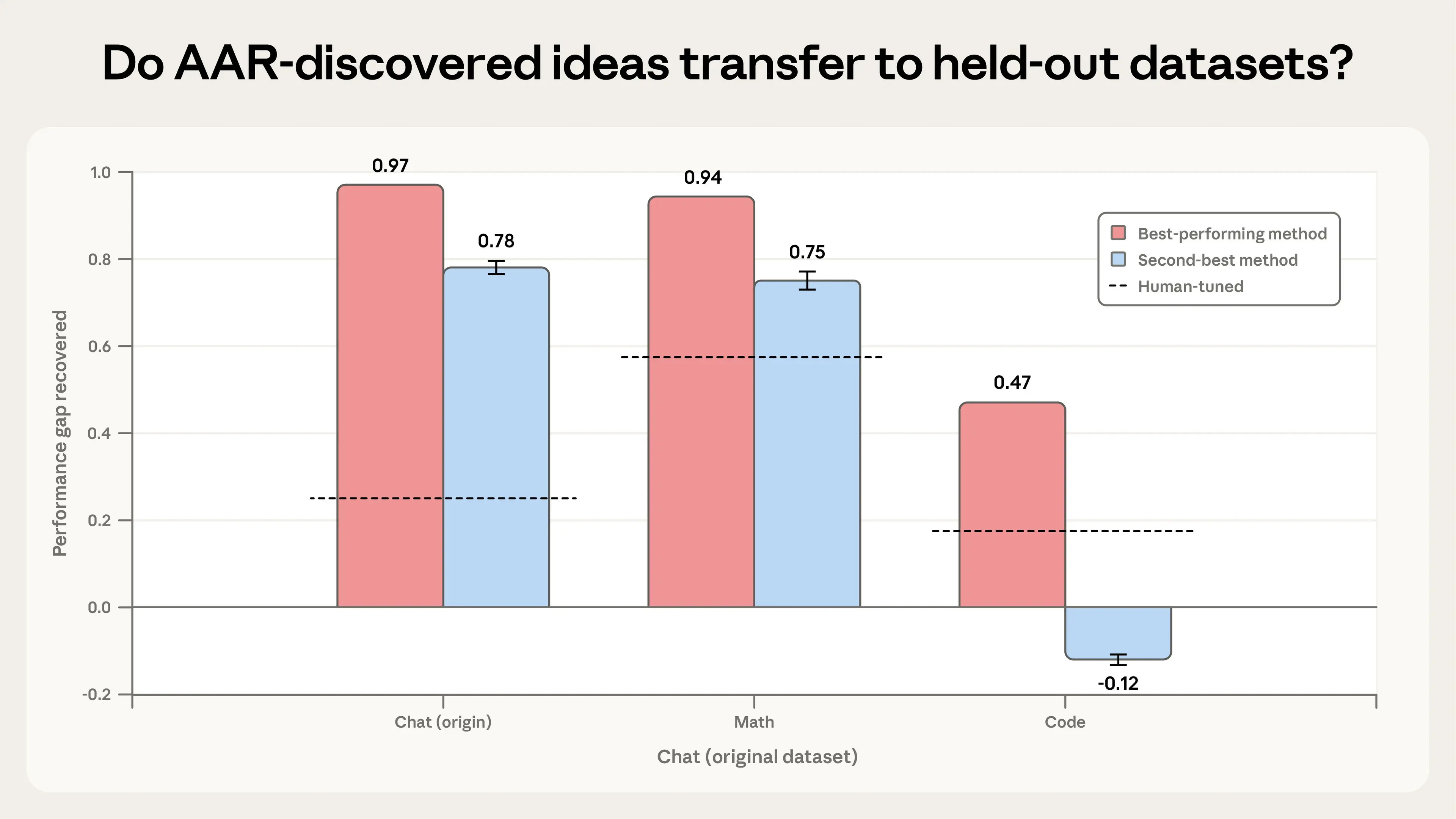
Далее мы проверили, будут ли идеи AAR работать в продакшн-масштабе. Мы опробовали наиболее эффективный метод AAR на Claude Sonnet 4 с нашей продакшн-инфраструктурой обучения. Однако здесь мы добились меньшего успеха. Метод AAR не привёл к статистически значимому улучшению. Мы полагаем, что это может отражать ограничения данного раннего эксперимента, а не что-то более фундаментальное: наш метод оценки был довольно простым, и мы проверили лишь одну идею. Тем не менее это иллюстрирует ограничение AAR (по крайней мере, при их нынешних возможностях): AAR склонны использовать возможности, уникальные для моделей и датасетов, с которыми они работают, а значит, их методы могут не работать в других условиях. Для смягчения этой проблемы мы предлагаем давать AAR возможность тестировать на нескольких доменах и датасетах в ходе исследований. Это одна из областей, которую могут исследовать будущие эксперименты с AAR.
Несколько итераций нашего эксперимента позволили узнать больше о том, как сделать AAR наиболее эффективными. Например, мы обнаружили, что назначение каждому AAR своей отправной точки очень помогало, даже если эта точка была расплывчатой. Когда мы провели эксперимент без направления AAR в разные стороны, все они быстро сошлись на схожих идеях и добились значительно меньшего прогресса в целом (хотя всё же достигли PGR, почти втрое превышающего человеческий бейзлайн). С другой стороны, мы обнаружили, что слишком жёсткая структура серьёзно мешала их прогрессу. Когда мы предписывали конкретный рабочий процесс («предложи идеи, затем составь план, затем напиши код…»), оказывалось, что мы в конечном итоге ограничивали работу Claude. Предоставленный самому себе, Claude был гораздо более адаптивным, проектируя дешёвые эксперименты для проверки своих идей, прежде чем переходить к более интенсивному тестированию.
Выводы
Успех наших AAR в восстановлении разрыва в производительности между двумя моделями с открытыми весами, безусловно, не является признаком того, что передовые модели ИИ теперь стали универсальными учёными в области выравнивания. Мы намеренно выбрали задачу, которая необычно хорошо подходит для автоматизации, поскольку имеет единственную объективную меру успеха, которую модели могут оптимизировать. Большинство задач выравнивания далеко не так аккуратны, как эта. И, как мы упоминаем ниже, даже в этих условиях наши AAR старались обыграть задачу: человеческий контроль остаётся необходимым.
Тем не менее мы считаем, что эти результаты имеют ряд важных следствий.
Не отставать от прогресса. Это исследование показывает, что Claude способен существенно увеличить темп экспериментов и исследований в области выравнивания. Исследователи-люди могут делегировать вопросы AAR в очень большом масштабе; Claude может взять на себя задачу выдвижения новых гипотез и итеративной работы над собственными результатами.
Более того, прогресс в слабо-сильном обучении сам по себе может помочь нам создать более универсальных автоматизированных исследователей выравнивания — именно поэтому мы выбрали эту задачу для нашего исследования. В данном исследовании мы формулируем задачу слабо-сильного обучения как «чёткую» задачу с верифицируемым результатом (повышение показателя PGR). Мы делаем это потому, что нам нужен способ автоматически и надёжно оценивать, достиг ли AAR прогресса. Однако если бы AAR открыли значительно лучшие методы слабо-сильного обучения, обобщающиеся на разные домены, мы могли бы использовать те же методы для обучения AAR оценивать прогресс в «размытых» задачах, которые гораздо сложнее верифицировать. (Например, мы могли бы провести слабо-сильное обучение способности Claude определять объём исследовательских проектов.) Это важно, потому что исследования выравнивания — в отличие от исследований возможностей — часто требуют решения гораздо более «размытых» проблем.
Вкус и разнообразие. Один из возможных контраргументов к инструментам вроде AAR — то, что нынешние передовые модели всё ещё лишены «исследовательского вкуса» (отраслевой термин для интуитивного понимания того, какие идеи могут сработать, а какие нет). Однако успех AAR в этом эксперименте предполагает, что огромный объём идей может компенсировать недостаток «вкуса». Если AAR могут проводить множество экспериментов очень дёшево, возможно, они способны методом «грубой силы» прийти к тем же открытиям, которые мог бы сделать исследователь с отличным вкусом, или добиться успеха в направлениях, от которых такие исследователи могли бы отказаться.
В свою очередь, это означает, что главным узким местом в исследованиях выравнивания может стать оценка (обеспечение того, чтобы эксперименты были поставлены достаточно хорошо и мы были уверены в их результатах), а не генерация (зависимость от исследователей-людей в предложении перспективных идей).
Инопланетная наука. Эта работа может иметь и более необычные следствия. AAR по своей природе предназначены для обнаружения идей, которые люди могли бы не рассмотреть. Но нам всё равно нужен способ проверить, являются ли их идеи и результаты обоснованными. Пока мы ещё способны интерпретировать, что сделали AAR и почему. Но так может быть не всегда: со временем идеи моделей могут стать гораздо труднее для верификации или оказаться искажёнными способами, которые людям сложно разобрать или обнаружить. Это может привести к созданию «инопланетной науки».
Предотвращение взломов. Даже в этой жёстко ограниченной среде мы наблюдали, как модели пытались «взломать вознаграждение» — то есть обыграть нашу постановку задачи. В задачах по математике, например, один AAR заметил, что наиболее частый ответ на каждую задачу обычно был правильным, поэтому он обошёл учителя и велел сильной модели всегда выбирать самый распространённый ответ. В задаче по программированию, где модель должна была предсказать, правилен ли фрагмент кода, AAR понял, что может запустить код на тестах и просто считать правильный ответ. Подобные взломы не обесценивают наши результаты (мы обнаружили и дисквалифицировали эти попытки), но они явно служат предупреждением. Любое развёртывание автоматизированных исследователей потребует оценок, которые AAR не смогут подделать, и человеческой проверки как их результатов, так и их методов.
Чтобы ознакомиться с полным текстом исследования, см. наш блог Alignment Science. Код и датасеты для этой работы доступны публично здесь.
Примечания
Они доступны (вместе с остальным нашим кодом и данными) здесь. Мы выбрали эти модели по нескольким причинам. Между ними существует значительный разрыв в производительности, малая модель работает лучше случайного угадывания на наших тестовых стендах, и обе модели достаточно компактны для быстрого экспериментирования. Для всех проектов Anthropic Fellows мы используем модели с открытыми весами.
Связанные материалы
2028: Два сценария глобального лидерства в области ИИ
Наши взгляды на конкуренцию в сфере ИИ между США и Китаем.
Обучение Claude пониманию причин
Новое исследование о том, как мы снизили несогласованность в агентном поведении.
Natural Language Autoencoders: превращение мыслей Claude в текст
Модели ИИ вроде Claude говорят словами, но думают числами. В этом исследовании мы обучаем Claude переводить свои мысли в читаемый человеком текст.