Advancing Claude in healthcare and the life sciences
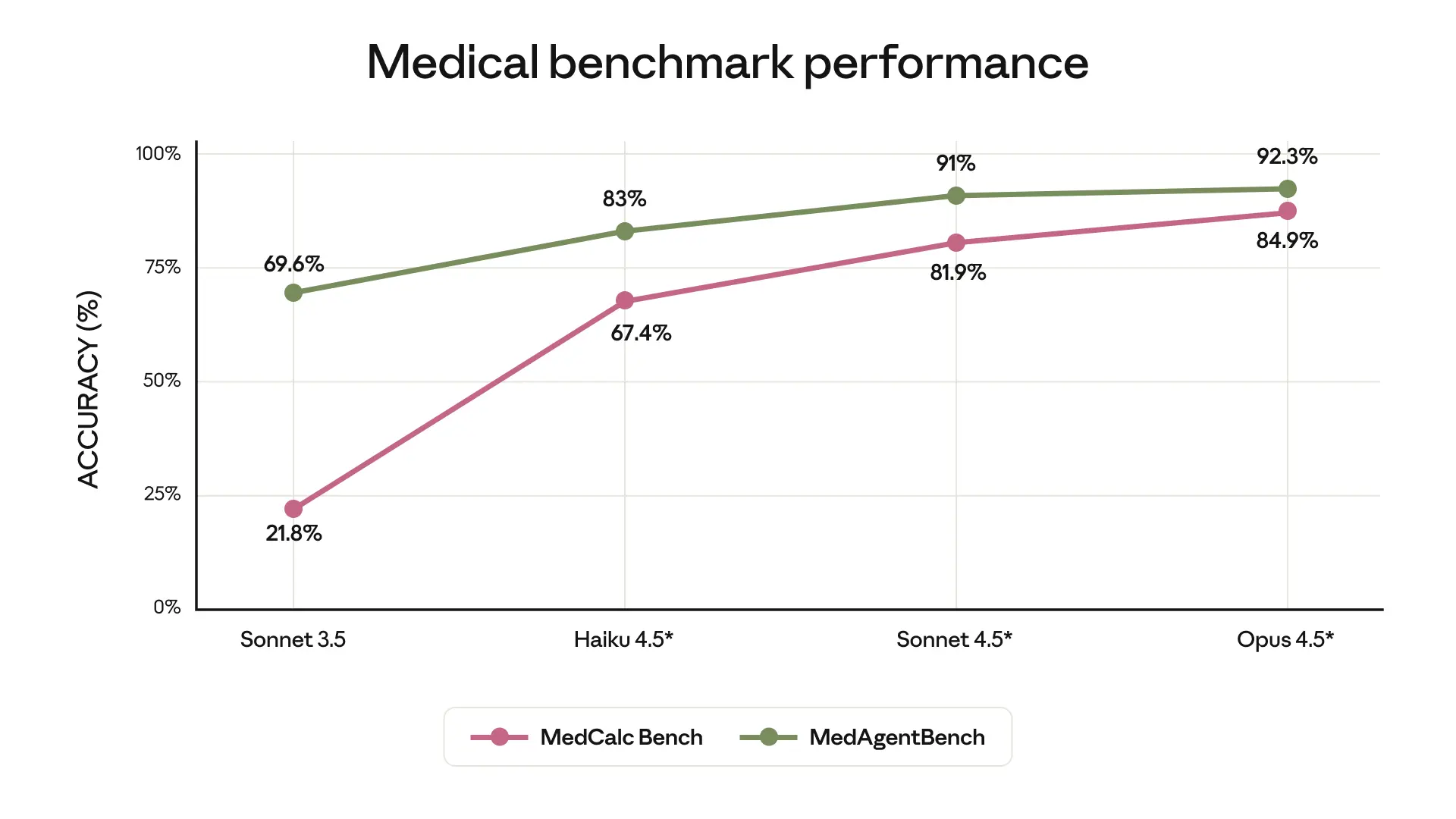
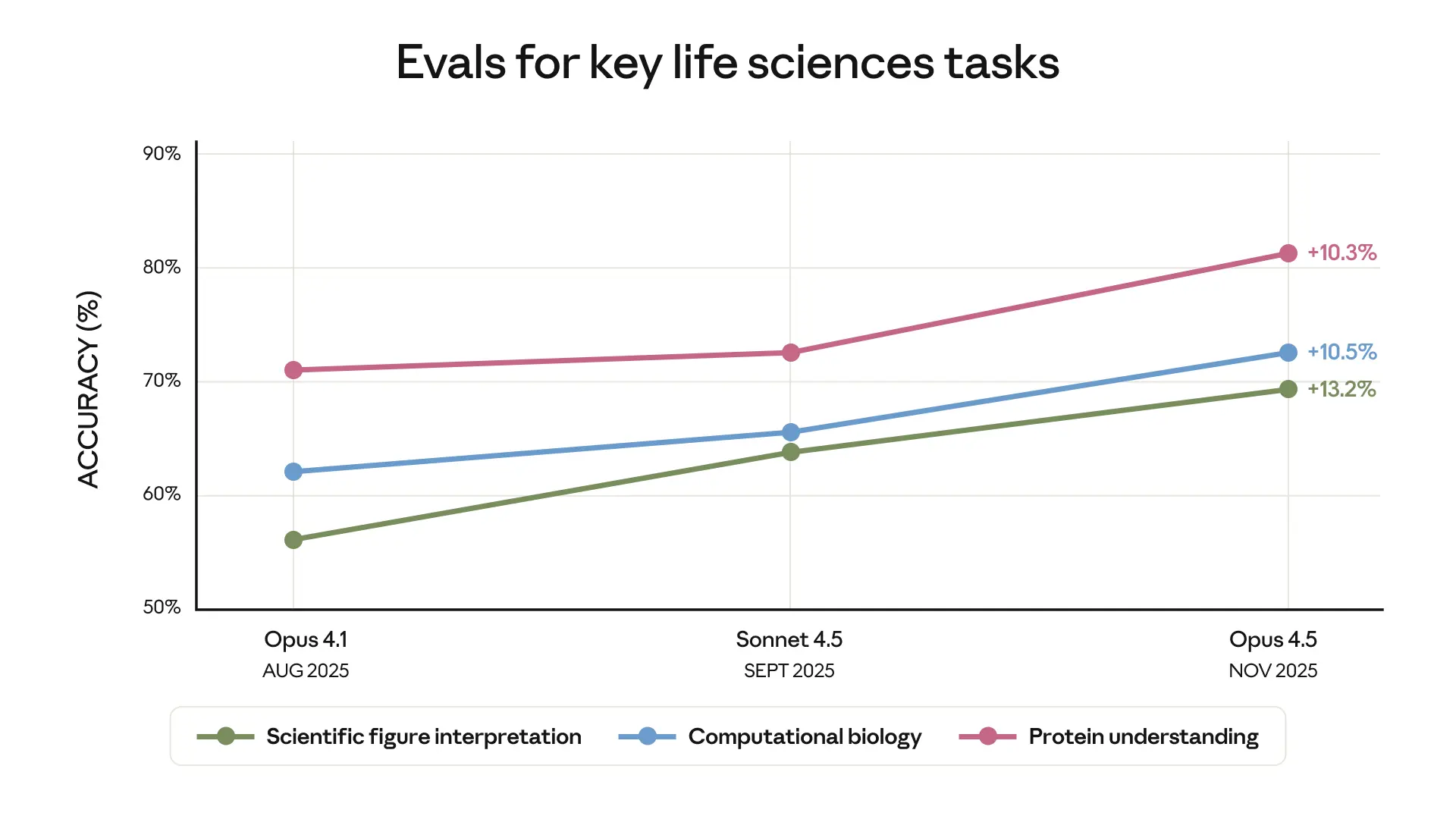
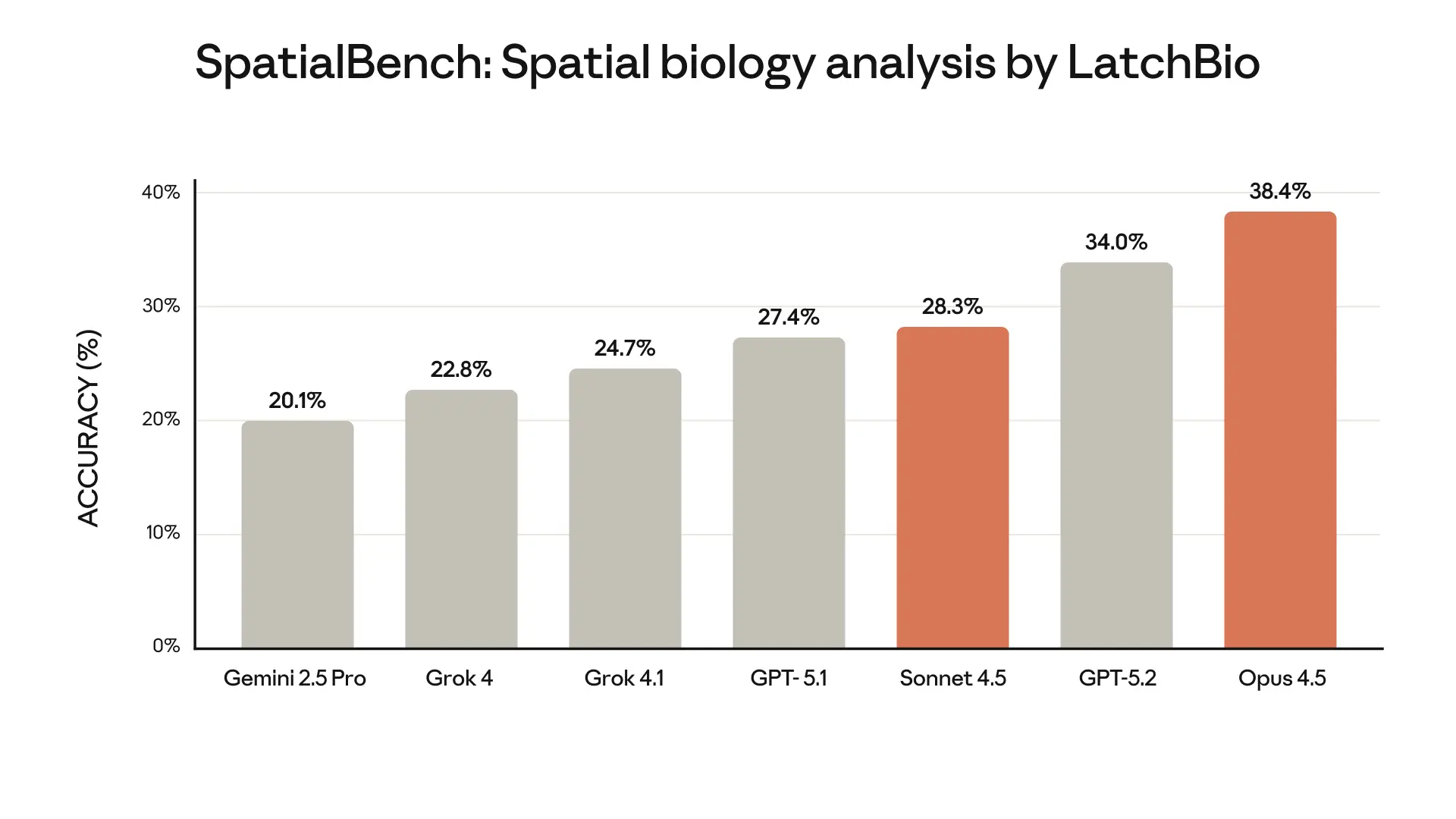
*Claude 4.5 models evaluated with extended thinking (64k tokens) and native tool useMedCalc: Medical calculation accuracy (with Python code execution)MedAgentBench: Medical agent task completion (Stanford)Opus 4.5 model shows improvement in accuracy against our internal evaluation of key life sciences tasks (scientific figure interpretation, computational biology, and protein understanding)Source: LatchBio SpatialBench (Dec 2025) - 146 verifiable problems across 5 spatial problems and 7 task categories