[AINews] Is Harness Engineering real?
Автор размышляет о центральной дискуссии в AI-инженерии — споре между сторонниками «Big Model» (мощь сосредоточена в самой модели) и «Big Harness» (ценность создаёт обвязка вокруг модели). Команды Claude Code (Boris Cherny, Cat Wu) и OpenAI Codex настаивают на минималистичной обвязке, а Noam Brown прогнозирует, что reasoning-модели вытеснят сложные scaffolds и роутеры; METR и Scale AI SWE-Atlas показывают, что выбор harness почти не влияет на результат. Противоположный лагерь (Jerry Liu, статья «The Harness Problem») доказывает, что вся продакшен-архитектура агентов сводится к одному циклу tool-calls и что оптимизация harness резко улучшает 15 LLM. На фоне оценки Cursor в $50B Latent Space признаёт реальную ценность Harness Engineering и анонсирует первый в мире трек по этой теме на AIE Europe. В Twitter-дайджесте обсуждаются Gemini 3.1 Flash-Lite, слухи о GPT-5.4 с контекстом ~1M токенов и «extreme reasoning mode», а также лидерство Claude в поведении агентов.
[AINews] Is Harness Engineering real?
[AINews] Существует ли Harness Engineering на самом деле?
a quiet day lets us reflect on a central debate in AI engineering
тихий день даёт повод поразмышлять о центральной дискуссии в AI-инженерии
A common debate in my finance days was about the value of the human vs the value of the seat: if a trader made $3m in profits, how much of it was because of her skills, and how much was because of the position/institution/brand she is in, and any generally competent human could have made the same results?
Распространённая дискуссия в мои финансовые годы касалась ценности самого человека против ценности его позиции: если трейдер заработал $3 млн прибыли, какая часть этого результата — заслуга её навыков, а какая — следствие позиции/института/бренда, в котором она работает, и любой ли в целом компетентный человек добился бы того же?
The same debate is currently raging in “Harness Engineering”, the systems subset of Agent Engineering, and the main job of Agent Labs. The central tension is between Big Model and Big Harness. [An AI framework founder you all know] once confided in me at an OpenAI event: “I’m not even sure these guys want me to exist.”
Та же дискуссия сейчас бушует вокруг «Harness Engineering» — системного подмножества Agent Engineering и основной задачи Agent Labs. Центральное противоречие — между Big Model и Big Harness. [Основатель одного AI-фреймворка, которого вы все знаете] однажды признался мне на мероприятии OpenAI: «Я даже не уверен, что эти ребята хотят, чтобы я существовал».
Aside: let’s define Harness — “In every engineering discipline, a harness is the same thing: the layer that connects, protects, and orchestrates components — without doing the work itself.“
Отступление: давайте определим Harness — «В любой инженерной дисциплине harness — это одно и то же: слой, который соединяет, защищает и оркестрирует компоненты, сам не выполняя их работы».
And, talking with the Big Model guys, you really see it:
И, разговаривая с ребятами из Big Model, это действительно ощущается:
Every podcast with Boris Cherny and Cat Wu emphasizes how minimal the harness of Claude Code is, meaning their job is mostly letting the model express its full power in the way that only the model maker knows best:
Boris: “I would say like there’s nothing that secret in the source. And obviously it’s all JavaScript, so you can just decompile it. Compilation’s out there. It’s very interesting. Yeah. And generally our approach is, you know, all the secret sauce, it’s all in the model. And this is the thinnest possible wrapper over the model. We literally could not build anything more minimal. This is the most minimal thing.
Cat [01:09:21]: It is very much the simplest thing I think by design.
Boris [01:09:25]: So it’s got simpler. It got simpler. It doesn’t go more complex. We’ve rewritten it from scratch probably every three weeks, four weeks or something. And it just like all the, it’s like a ship of Theseus, right? Like every piece keeps getting swapped out and just cause quad is so good at writing its own code.”
OpenAI’s own piece on Harness Engineering (with upcoming guest Ryan Lopopolo on the Codex team) emphasizes how simple it is to start. Of course, with the “execuhire” of OpenClaw, OpenAI are now big investors of the world’s most successful open source harness.
Noam Brown: “before the reasoning models emerged, there was like all of this work that went into engineering agentic systems that like made a lot of calls to GPT-4o or like these non-reasoning models to get reasoning behavior. And then it turns out we just created reasoning models and they, you don’t need this complex behavior. In fact, in many ways, it makes it worse. Like you just give the reasoning model the same question without any sort of scaffolding and it just does it. And so people are building scaffolding on top of the reasoning models right now. But I think in many ways, those scaffolds will also just be replaced by the reasoning models and models in general becoming more capable. And similarly, I think things like model routers, we’ve said pretty openly that we want to move to a world where there is a single unified model. And in that world, you shouldn’t need a router on top of the model.”
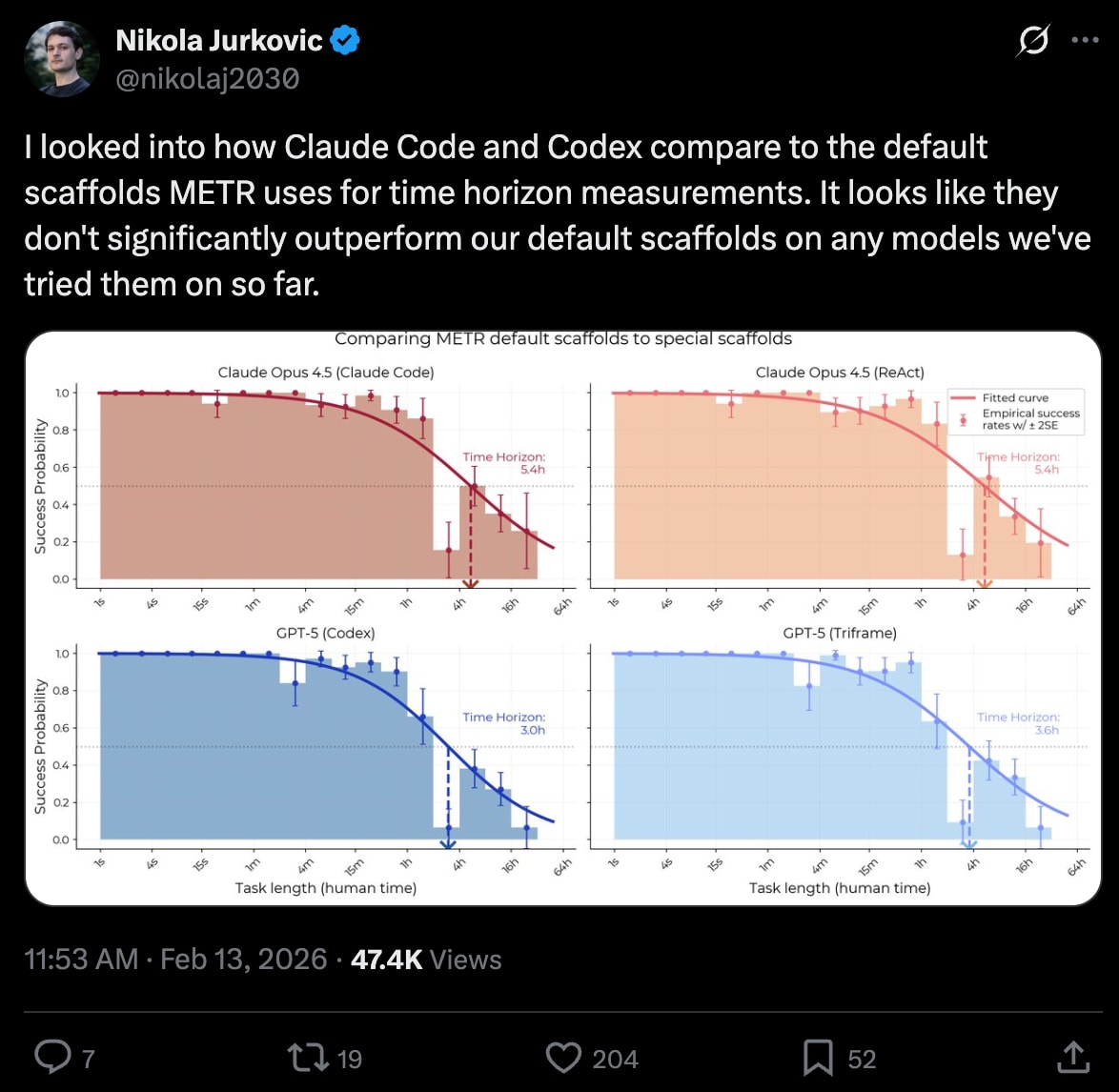
METR saying Claude Code and Codex don’t beat a basic scaffold:
Scale AI’s SWE-Atlas is finds that Opus 4.6 does 2.5 points better in Claude Code than in the generic SWE-Agent, but the reverse for GPT 5.2, making the harness you choose essentially noise within the margin of error:

Каждый подкаст с Boris Cherny и Cat Wu подчёркивает, насколько минимален harness Claude Code: их работа сводится в основном к тому, чтобы дать модели проявить свою полную силу так, как это умеет только сам создатель модели. Boris: «Я бы сказал, что в исходниках нет ничего особо секретного. И, очевидно, это всё JavaScript, так что его можно просто декомпилировать. Декомпиляция уже гуляет в сети. Это очень интересно. Да. И в целом наш подход такой: знаете, весь секретный соус — он весь в модели. А это самая тонкая возможная обёртка над моделью. Мы буквально не могли бы построить ничего более минимального. Это самая минимальная вещь.» Cat [01:09:21]: «Это и правда максимально простая штука — так задумано». Boris [01:09:25]: «Он стал ещё проще. Он становится проще, а не сложнее. Мы переписывали его с нуля примерно каждые три-четыре недели. И это как корабль Тесея — каждая часть постоянно заменяется, потому что Claude так хорош в написании собственного кода». Собственная статья OpenAI о Harness Engineering (с будущим гостем подкаста Ryan Lopopolo из команды Codex) подчёркивает, насколько просто стартовать. Конечно, после «execuhire» OpenClaw OpenAI теперь крупный инвестор в самый успешный в мире open source harness. Noam Brown: «до появления reasoning-моделей была вся эта работа по инженерии агентных систем, которые делали кучу вызовов к GPT-4o или другим non-reasoning моделям, чтобы получить reasoning-поведение. А потом оказалось, что мы просто создали reasoning-модели — и весь этот сложный механизм не нужен. На самом деле во многом он только мешает. Можно просто дать reasoning-модели тот же вопрос без всяких лесов — и она сама с ним справится. Сейчас люди строят леса поверх reasoning-моделей. Но я думаю, что во многом эти леса тоже будут заменены тем, что reasoning-модели и модели в целом станут более способными. И аналогично с такими вещами, как роутеры моделей — мы достаточно открыто говорили, что хотим прийти к миру, где есть одна единая модель. И в этом мире вам не должен быть нужен роутер поверх модели.» METR говорит, что Claude Code и Codex не обыгрывают базовый scaffold: SWE-Atlas от Scale AI показывает, что Opus 4.6 на 2,5 балла лучше в Claude Code, чем в обобщённом SWE-Agent, но для GPT 5.2 всё наоборот — то есть выбор harness фактически попадает в шум в пределах погрешности:
And yet. The Big Harness guys disagree:
И всё же. Сторонники Big Harness с этим не согласны:
Every production agent converges on this core loop:
while (model returns tool calls):
execute tool → capture result → append to context → call model againThat is it. The entire architecture of Claude Code, Cursor’s agent, and Manus fits inside that loop.
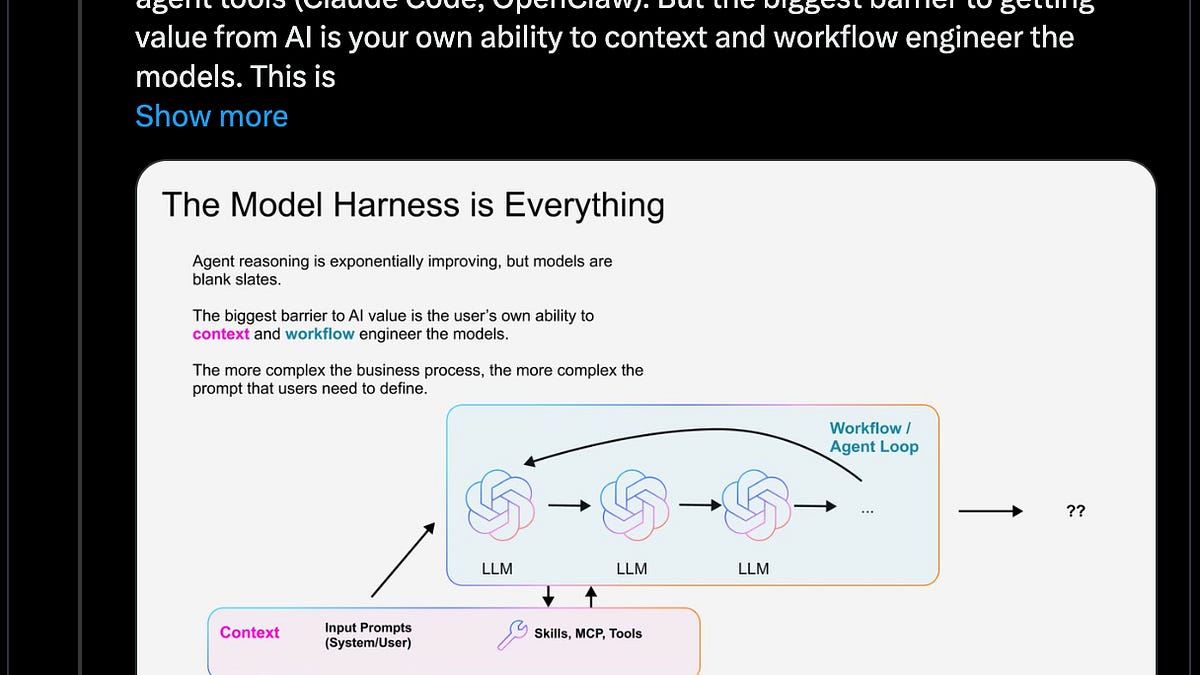
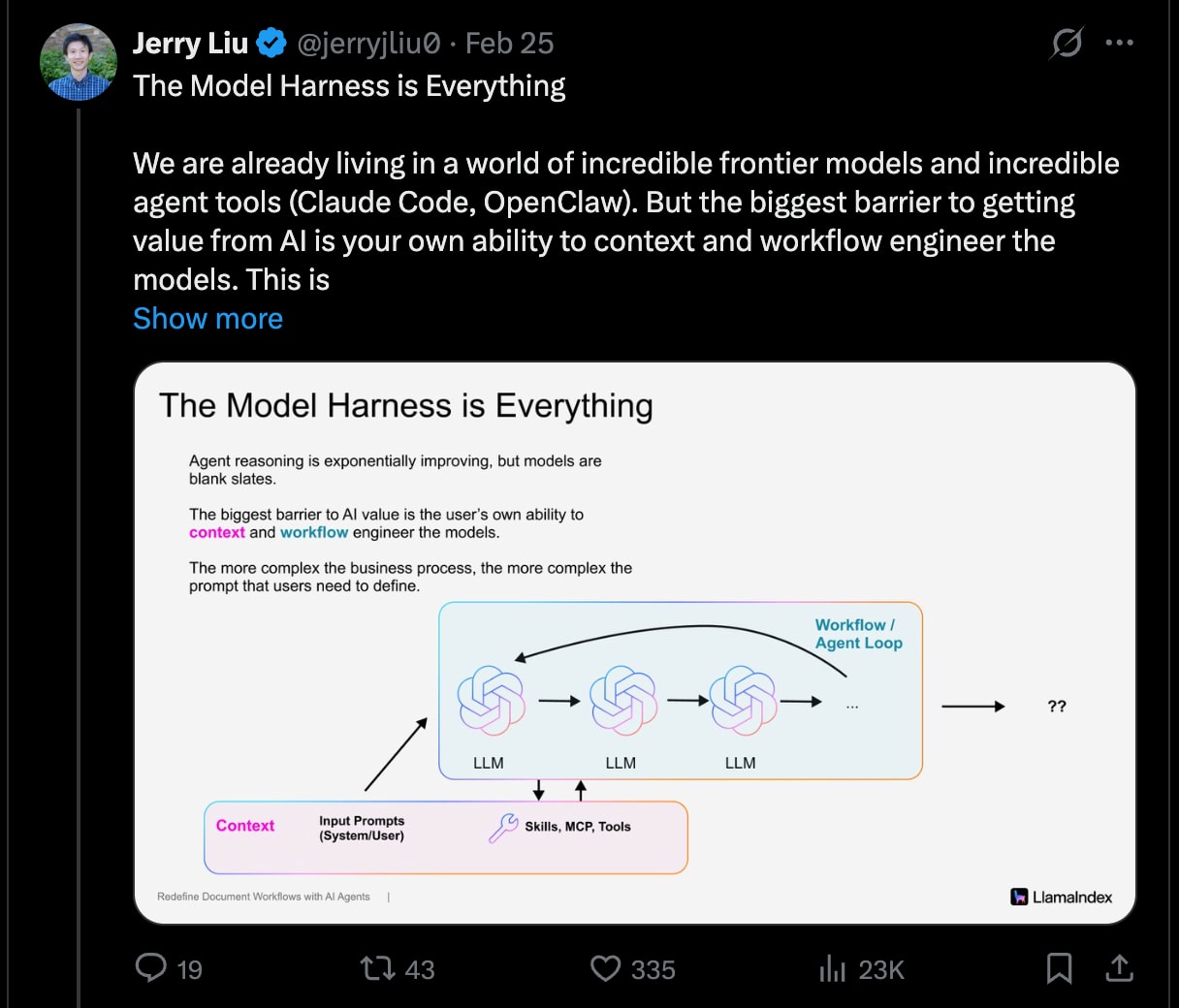
Jerry Liu: “The Model Harness is Everything — the biggest barrier to getting value from AI is your own ability to context and workflow engineer the models. This is *especially* true the more horizontal the tool that you’re using.”
Improving 15 LLMs at Coding in One Afternoon. Only the Harness Changed shows dramatic improvements in every model when you optimize the harness (Pi)
Harness — это и есть продукт: любой продакшен-агент сходится к одному и тому же ядру: while (модель возвращает tool calls): выполнить tool → захватить результат → добавить в контекст → снова вызвать модель. Вот и всё. Вся архитектура Claude Code, агента Cursor и Manus умещается внутри этого цикла. Jerry Liu: «Model Harness — это всё. Главный барьер на пути получения пользы от AI — это ваше умение делать context и workflow engineering для моделей. И это *особенно* верно, чем горизонтальнее инструмент, который вы используете». «Улучшаем 15 LLM в кодинге за один день. Менялся только harness» показывает резкие улучшения у каждой модели при оптимизации harness (Pi).
Obviously Big Harness guys are trying to sell you their Harness, Big Model guys are trying to sell you their Model. The ML/AI industry has always had some form of milquetoast “compound AI” debate that tells you both are valuable. But perhaps the times are changing.
Очевидно, ребята из Big Harness пытаются продать вам свой Harness, а ребята из Big Model — свою модель. ML/AI-индустрия всегда вела какие-то невнятные дискуссии про «compound AI», которые говорят: ценно и то, и другое. Но, возможно, времена меняются.
On Latent Space we’ve been very, very respectful of the Bitter Lesson, but increasingly as the Agent Labs thesis has played out (with Cursor now valued at $50B), we are acknowledging that “Harness Engineering” has real value. AIE Europe now has the world’s first Harness Engineering track, and if you are keen on this debate, you should join.
В Latent Space мы всегда очень, очень уважительно относились к Bitter Lesson, но по мере того как тезис Agent Labs реализуется (а Cursor теперь оценивается в $50B), мы всё больше признаём, что у «Harness Engineering» есть реальная ценность. На AIE Europe теперь есть первый в мире трек по Harness Engineering, и если эта дискуссия вам интересна — стоит присоединиться.
AI News for 3/3/2026-3/4/2026. We checked 12 subreddits, 544 Twitters and 24 Discords (264 channels, and 14242 messages) for you. Estimated reading time saved (at 200wpm): 1397 minutes. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
AI News за 03.03.2026–04.03.2026. Мы проверили для вас 12 сабреддитов, 544 Twitter-аккаунта и 24 Discord-сервера (264 канала и 14242 сообщения). Расчётное сэкономленное время чтения (при 200 слов/мин): 1397 минут. Сайт AINews позволяет искать по всем прошлым выпускам. Напоминаем, что AINews теперь является разделом Latent Space. Вы можете подписаться/отписаться от частоты email-рассылок!
AI Twitter Recap
Подборка из AI Twitter
Frontier model shipping: Gemini 3.1 Flash-Lite, GPT-5.4 rumors, and “agent-first” product positioning
Релизы фронтир-моделей: Gemini 3.1 Flash-Lite, слухи о GPT-5.4 и «agent-first» позиционирование продуктов
Gemini 3.1 Flash-Lite positioning (speed/$): Demis Hassabis teased Gemini 3.1 Flash-Lite as “incredibly fast and cost-efficient” for its performance—clearly framing the model line around latency and cost per capability rather than raw frontier scores (tweet). Related product chatter highlights NotebookLM as a “favorite AI tool” (tweet) and a major new NotebookLM Studio feature: Cinematic Video Overviews that generate bespoke, immersive videos from user sources for Ultra users (tweet).
GPT-5.4 leak narrative (The Information): Multiple tweets amplify a report that GPT-5.4 is coming with a ~1M token context window and a new “extreme reasoning mode” that can “think for hours,” targeting long-horizon agentic workflows and lower complex-task error rates (tweet, tweet, tweet). There’s also speculation that OpenAI is shifting to more frequent (monthly) model updates (tweet). Separately, one arena watcher claims “GPT-5.4 landed in the arena,” implying an imminent release window (tweet). Treat all of this as unconfirmed unless corroborated by OpenAI.
Claude as “agent behavior” leader, not just coding: Nat Lambert argues the discussion should shift from Anthropic “going all-in on code” to their lead on general agent behavior, implying coding capability will commoditize but agent robustness will not (tweet). MathArena evaluation adds a datapoint: Claude Opus 4.6 is strong overall but weak on visual mathematics, and costly to evaluate (claimed ~$8k) (tweet).
Позиционирование Gemini 3.1 Flash-Lite (скорость/$): Demis Hassabis анонсировал Gemini 3.1 Flash-Lite как «невероятно быструю и экономичную» для своего уровня производительности — явно выстраивая линейку моделей вокруг латентности и стоимости за способность, а не вокруг сырых фронтир-метрик (твит). В смежных продуктовых обсуждениях NotebookLM называют «любимым AI-инструментом» (твит) и упоминают крупную новую фичу NotebookLM Studio: Cinematic Video Overviews — генерация авторских иммерсивных видео из источников пользователя для подписчиков Ultra (твит). Утечка про GPT-5.4 (The Information): множество твитов раскручивают репортаж о том, что GPT-5.4 выйдет с контекстным окном ~1M токенов и новым «extreme reasoning mode», способным «думать часами», нацеленным на агентные workflow с длинным горизонтом и снижение ошибок в сложных задачах (твит, твит, твит). Также есть предположения, что OpenAI переходит на более частые (ежемесячные) обновления моделей (твит). Отдельно один наблюдатель за ареной утверждает, что «GPT-5.4 уже появилась на арене», намекая на близкое окно релиза (твит). Относитесь ко всему этому как к неподтверждённому, пока это не подтвердит сама OpenAI. Claude как лидер «поведения агентов», а не только кодинга: Nat Lambert утверждает, что обсуждение должно сместиться с того, что Anthropic «целиком уходит в код», к их лидерству в общем поведении агентов, подразумевая, что способности к кодингу будут коммодитизироваться, а устойчивость агентов — нет (твит). Оценка MathArena добавляет точку данных: Claude Opus 4.6 в целом силён, но слаб на визуальной математике и дорог в оценке (заявлено около $8k) (твит).
Keep reading with a 7-day free trial
Продолжайте читать с 7-дневным бесплатным пробным периодом
Subscribe to Latent.Space to keep reading this post and get 7 days of free access to the full post archives.
Подпишитесь на Latent.Space, чтобы продолжить чтение этого поста и получить 7 дней бесплатного доступа к полному архиву постов.