[AINews] Is Harness Engineering real?
Автор размышляет о центральной дискуссии в AI-инженерии — споре между сторонниками «Big Model» (мощь сосредоточена в самой модели) и «Big Harness» (ценность создаёт обвязка вокруг модели). Команды Claude Code (Boris Cherny, Cat Wu) и OpenAI Codex настаивают на минималистичной обвязке, а Noam Brown прогнозирует, что reasoning-модели вытеснят сложные scaffolds и роутеры; METR и Scale AI SWE-Atlas показывают, что выбор harness почти не влияет на результат. Противоположный лагерь (Jerry Liu, статья «The Harness Problem») доказывает, что вся продакшен-архитектура агентов сводится к одному циклу tool-calls и что оптимизация harness резко улучшает 15 LLM. На фоне оценки Cursor в $50B Latent Space признаёт реальную ценность Harness Engineering и анонсирует первый в мире трек по этой теме на AIE Europe. В Twitter-дайджесте обсуждаются Gemini 3.1 Flash-Lite, слухи о GPT-5.4 с контекстом ~1M токенов и «extreme reasoning mode», а также лидерство Claude в поведении агентов.
[AINews] Существует ли Harness Engineering на самом деле?
тихий день даёт повод поразмышлять о центральной дискуссии в AI-инженерии
Распространённая дискуссия в мои финансовые годы касалась ценности самого человека против ценности его позиции: если трейдер заработал $3 млн прибыли, какая часть этого результата — заслуга её навыков, а какая — следствие позиции/института/бренда, в котором она работает, и любой ли в целом компетентный человек добился бы того же?
Та же дискуссия сейчас бушует вокруг «Harness Engineering» — системного подмножества Agent Engineering и основной задачи Agent Labs. Центральное противоречие — между Big Model и Big Harness. [Основатель одного AI-фреймворка, которого вы все знаете] однажды признался мне на мероприятии OpenAI: «Я даже не уверен, что эти ребята хотят, чтобы я существовал».
Отступление: давайте определим Harness — «В любой инженерной дисциплине harness — это одно и то же: слой, который соединяет, защищает и оркестрирует компоненты, сам не выполняя их работы».
И, разговаривая с ребятами из Big Model, это действительно ощущается:
Каждый подкаст с Boris Cherny и Cat Wu подчёркивает, насколько минимален harness Claude Code: их работа сводится в основном к тому, чтобы дать модели проявить свою полную силу так, как это умеет только сам создатель модели. Boris: «Я бы сказал, что в исходниках нет ничего особо секретного. И, очевидно, это всё JavaScript, так что его можно просто декомпилировать. Декомпиляция уже гуляет в сети. Это очень интересно. Да. И в целом наш подход такой: знаете, весь секретный соус — он весь в модели. А это самая тонкая возможная обёртка над моделью. Мы буквально не могли бы построить ничего более минимального. Это самая минимальная вещь.» Cat [01:09:21]: «Это и правда максимально простая штука — так задумано». Boris [01:09:25]: «Он стал ещё проще. Он становится проще, а не сложнее. Мы переписывали его с нуля примерно каждые три-четыре недели. И это как корабль Тесея — каждая часть постоянно заменяется, потому что Claude так хорош в написании собственного кода». Собственная статья OpenAI о Harness Engineering (с будущим гостем подкаста Ryan Lopopolo из команды Codex) подчёркивает, насколько просто стартовать. Конечно, после «execuhire» OpenClaw OpenAI теперь крупный инвестор в самый успешный в мире open source harness. Noam Brown: «до появления reasoning-моделей была вся эта работа по инженерии агентных систем, которые делали кучу вызовов к GPT-4o или другим non-reasoning моделям, чтобы получить reasoning-поведение. А потом оказалось, что мы просто создали reasoning-модели — и весь этот сложный механизм не нужен. На самом деле во многом он только мешает. Можно просто дать reasoning-модели тот же вопрос без всяких лесов — и она сама с ним справится. Сейчас люди строят леса поверх reasoning-моделей. Но я думаю, что во многом эти леса тоже будут заменены тем, что reasoning-модели и модели в целом станут более способными. И аналогично с такими вещами, как роутеры моделей — мы достаточно открыто говорили, что хотим прийти к миру, где есть одна единая модель. И в этом мире вам не должен быть нужен роутер поверх модели.» METR говорит, что Claude Code и Codex не обыгрывают базовый scaffold: SWE-Atlas от Scale AI показывает, что Opus 4.6 на 2,5 балла лучше в Claude Code, чем в обобщённом SWE-Agent, но для GPT 5.2 всё наоборот — то есть выбор harness фактически попадает в шум в пределах погрешности:
И всё же. Сторонники Big Harness с этим не согласны:
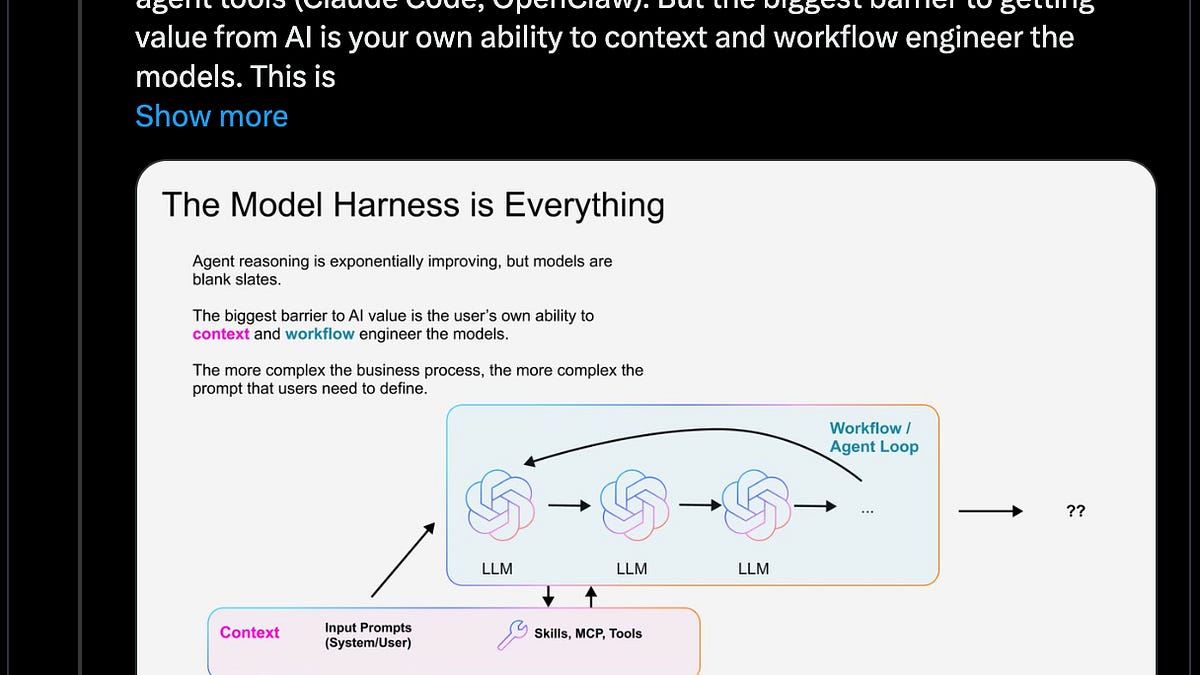
Harness — это и есть продукт: любой продакшен-агент сходится к одному и тому же ядру: while (модель возвращает tool calls): выполнить tool → захватить результат → добавить в контекст → снова вызвать модель. Вот и всё. Вся архитектура Claude Code, агента Cursor и Manus умещается внутри этого цикла. Jerry Liu: «Model Harness — это всё. Главный барьер на пути получения пользы от AI — это ваше умение делать context и workflow engineering для моделей. И это *особенно* верно, чем горизонтальнее инструмент, который вы используете». «Улучшаем 15 LLM в кодинге за один день. Менялся только harness» показывает резкие улучшения у каждой модели при оптимизации harness (Pi).
Очевидно, ребята из Big Harness пытаются продать вам свой Harness, а ребята из Big Model — свою модель. ML/AI-индустрия всегда вела какие-то невнятные дискуссии про «compound AI», которые говорят: ценно и то, и другое. Но, возможно, времена меняются.
В Latent Space мы всегда очень, очень уважительно относились к Bitter Lesson, но по мере того как тезис Agent Labs реализуется (а Cursor теперь оценивается в $50B), мы всё больше признаём, что у «Harness Engineering» есть реальная ценность. На AIE Europe теперь есть первый в мире трек по Harness Engineering, и если эта дискуссия вам интересна — стоит присоединиться.
AI News за 03.03.2026–04.03.2026. Мы проверили для вас 12 сабреддитов, 544 Twitter-аккаунта и 24 Discord-сервера (264 канала и 14242 сообщения). Расчётное сэкономленное время чтения (при 200 слов/мин): 1397 минут. Сайт AINews позволяет искать по всем прошлым выпускам. Напоминаем, что AINews теперь является разделом Latent Space. Вы можете подписаться/отписаться от частоты email-рассылок!
Подборка из AI Twitter
Релизы фронтир-моделей: Gemini 3.1 Flash-Lite, слухи о GPT-5.4 и «agent-first» позиционирование продуктов
Позиционирование Gemini 3.1 Flash-Lite (скорость/$): Demis Hassabis анонсировал Gemini 3.1 Flash-Lite как «невероятно быструю и экономичную» для своего уровня производительности — явно выстраивая линейку моделей вокруг латентности и стоимости за способность, а не вокруг сырых фронтир-метрик (твит). В смежных продуктовых обсуждениях NotebookLM называют «любимым AI-инструментом» (твит) и упоминают крупную новую фичу NotebookLM Studio: Cinematic Video Overviews — генерация авторских иммерсивных видео из источников пользователя для подписчиков Ultra (твит). Утечка про GPT-5.4 (The Information): множество твитов раскручивают репортаж о том, что GPT-5.4 выйдет с контекстным окном ~1M токенов и новым «extreme reasoning mode», способным «думать часами», нацеленным на агентные workflow с длинным горизонтом и снижение ошибок в сложных задачах (твит, твит, твит). Также есть предположения, что OpenAI переходит на более частые (ежемесячные) обновления моделей (твит). Отдельно один наблюдатель за ареной утверждает, что «GPT-5.4 уже появилась на арене», намекая на близкое окно релиза (твит). Относитесь ко всему этому как к неподтверждённому, пока это не подтвердит сама OpenAI. Claude как лидер «поведения агентов», а не только кодинга: Nat Lambert утверждает, что обсуждение должно сместиться с того, что Anthropic «целиком уходит в код», к их лидерству в общем поведении агентов, подразумевая, что способности к кодингу будут коммодитизироваться, а устойчивость агентов — нет (твит). Оценка MathArena добавляет точку данных: Claude Opus 4.6 в целом силён, но слаб на визуальной математике и дорог в оценке (заявлено около $8k) (твит).
Продолжайте читать с 7-дневным бесплатным пробным периодом
Подпишитесь на Latent.Space, чтобы продолжить чтение этого поста и получить 7 дней бесплатного доступа к полному архиву постов.