
Demystifying evals for AI agents
Статья Anthropic описывает методологию создания оценок (evals) для AI-агентов — систем, которые работают в несколько шагов, вызывают инструменты и модифицируют состояние среды. Рассматриваются три типа грейдеров: детерминистические (на основе кода), модельные (LLM-судьи) и человеческие, а также метрики pass@k и pass^k для учёта недетерминированности агентов. Приводятся практические примеры оценки кодовых, разговорных, исследовательских агентов и агентов компьютерного управления, включая бенчмарки SWE-bench Verified, Terminal-Bench, τ-Bench и WebArena. Авторы предлагают пошаговый план: начинать с 20–50 задач из реальных сбоев, писать однозначные спецификации с эталонными решениями, строить сбалансированные наборы задач и регулярно читать транскрипты. Подчёркивается, что команды без оценок застревают в реактивных циклах, тогда как раннее внедрение evals ускоряет разработку, позволяет быстрее переходить на новые модели и превращает жалобы пользователей в конкретные метрики.
Введение
Качественные оценки помогают командам выпускать AI-агентов с большей уверенностью. Без них легко попасть в реактивный цикл — обнаруживать проблемы только в продакшене, где исправление одного сбоя порождает другие. Оценки делают проблемы и изменения в поведении видимыми до того, как они затронут пользователей, а их ценность накапливается на протяжении всего жизненного цикла агента.
Как мы описали в статье Building effective agents, агенты работают на протяжении множества шагов: вызывают инструменты, изменяют состояние и адаптируются на основе промежуточных результатов. Те же возможности, которые делают AI-агентов полезными — автономность, интеллект и гибкость — одновременно усложняют их оценку.
Благодаря нашей внутренней работе и сотрудничеству с клиентами на передовой разработки агентов мы научились проектировать более строгие и полезные оценки. Вот что сработало для различных архитектур агентов и сценариев использования в реальных внедрениях.
Структура оценки
Оценка (eval) — это тест для AI-системы: дать ИИ вход, а затем применить логику оценивания к его выходу для измерения успешности. В этой статье мы сосредоточимся на автоматических оценках, которые можно запускать в процессе разработки без участия реальных пользователей.
Одношаговые оценки устроены просто: промпт, ответ и логика оценивания. Для ранних LLM одношаговые, неагентные оценки были основным методом. По мере роста возможностей ИИ многошаговые оценки становятся всё более распространёнными.
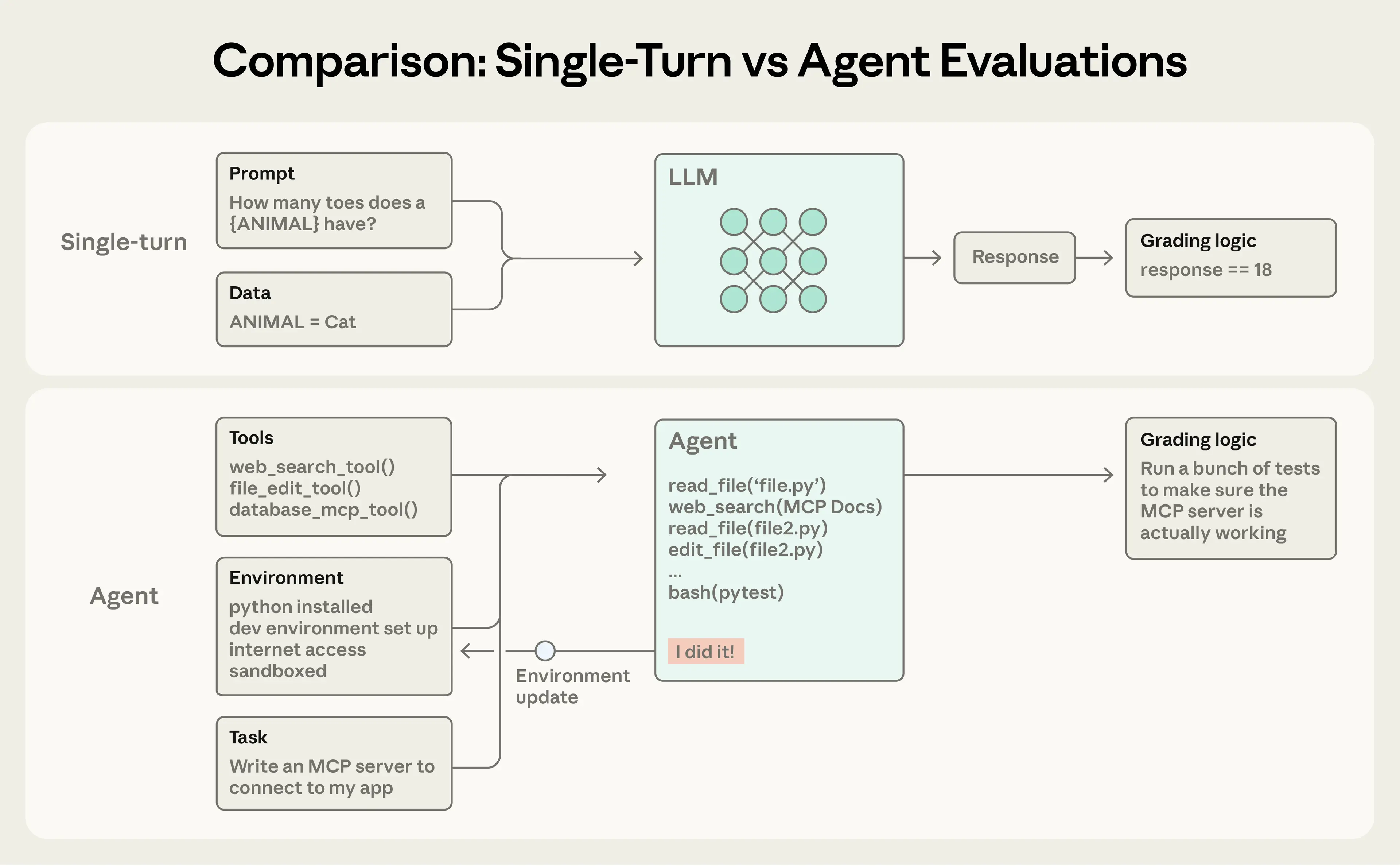
Оценки агентов ещё сложнее. Агенты используют инструменты на протяжении множества шагов, изменяя состояние среды и адаптируясь по ходу — а значит, ошибки могут распространяться и накапливаться. Передовые модели также способны находить креативные решения, выходящие за рамки статических оценок. Например, Opus 4.5 решил задачу бронирования авиабилета в 𝜏2-bench, обнаружив лазейку в политике. Формально он «провалил» оценку, но на деле нашёл лучшее решение для пользователя.
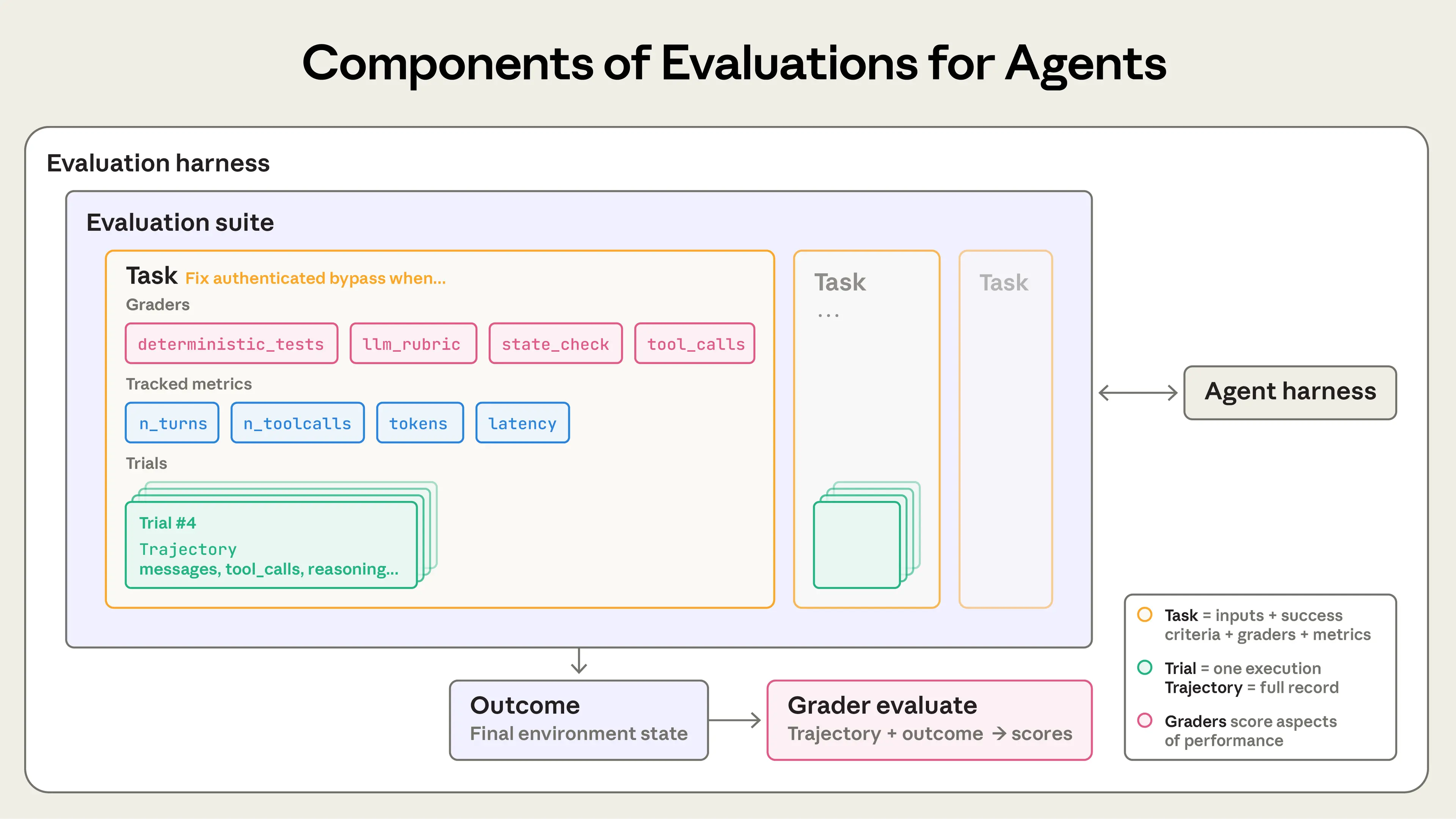
При создании оценок агентов мы используем следующие определения:
Задача (она же проблема или тестовый случай) — это отдельный тест с определёнными входами и критериями успеха.Каждая попытка выполнения задачи — это проба (trial). Поскольку выходы модели варьируются между запусками, мы проводим несколько проб для получения более стабильных результатов.Грейдер — это логика, которая оценивает определённый аспект работы агента. У задачи может быть несколько грейдеров, каждый из которых содержит несколько утверждений (иногда называемых проверками).Транскрипт (также называемый трассой или траекторией) — это полная запись пробы, включающая выходы, вызовы инструментов, рассуждения, промежуточные результаты и любые другие взаимодействия. Для Anthropic API это полный массив messages в конце запуска оценки, содержащий все вызовы к API и все полученные ответы во время оценки.Исход — это финальное состояние среды по окончании пробы. Агент бронирования авиабилетов может написать «Ваш рейс забронирован» в конце транскрипта, но исход — это наличие записи о бронировании в SQL-базе данных среды.Среда оценки (evaluation harness) — это инфраструктура, которая запускает оценки от начала до конца. Она предоставляет инструкции и инструменты, параллельно запускает задачи, записывает все шаги, оценивает выходы и агрегирует результаты.Среда агента (agent harness, или scaffold) — это система, которая позволяет модели действовать как агент: она обрабатывает входы, оркестрирует вызовы инструментов и возвращает результаты. Когда мы оцениваем «агента», мы оцениваем среду и модель, работающие вместе. Например, Claude Code — это гибкая среда для агента, и мы использовали её основные примитивы через Agent SDK для создания нашей среды для долгоживущих агентов.Набор оценок (evaluation suite) — это коллекция задач, предназначенных для измерения конкретных возможностей или поведения. Задачи в наборе обычно объединены общей целью. Например, набор оценок клиентской поддержки может тестировать возвраты, отмены и эскалации.
Зачем создавать оценки?
Когда команды только начинают создавать агентов, они могут удивительно далеко продвинуться за счёт ручного тестирования, использования собственного продукта и интуиции. Более строгая оценка может даже показаться лишней нагрузкой, замедляющей выпуск. Однако после ранних стадий прототипирования, когда агент уже в продакшене и начинает масштабироваться, разработка без оценок начинает давать сбои.
Переломный момент часто наступает, когда пользователи сообщают, что агент стал хуже после изменений, а команда «летит вслепую» без возможности проверить это иначе, чем наугад. Без оценок отладка реактивна: ждать жалоб, воспроизводить вручную, исправлять баг и надеяться, что ничего другого не сломалось. Команды не могут отличить реальные регрессии от шума, автоматически проверять изменения на сотнях сценариев перед релизом или измерять улучшения.
Мы наблюдали эту эволюцию множество раз. Например, Claude Code начинался с быстрых итераций на основе обратной связи от сотрудников Anthropic и внешних пользователей. Позже мы добавили оценки — сначала для узких областей вроде лаконичности и редактирования файлов, а затем для более сложного поведения, например, избыточного усложнения кода. Эти оценки помогли выявить проблемы, направить улучшения и сфокусировать сотрудничество между исследованиями и продуктом. В сочетании с мониторингом в продакшене, A/B-тестами, исследованиями пользователей и другими методами оценки дают сигналы для дальнейшего улучшения Claude Code по мере масштабирования.
Написание оценок полезно на любом этапе жизненного цикла агента. На ранних стадиях оценки заставляют продуктовые команды сформулировать, что означает успех для агента, а позже помогают поддерживать стабильную планку качества.
Агент Descript помогает пользователям редактировать видео, поэтому они построили оценки вокруг трёх измерений успешного рабочего процесса редактирования: не ломай то, что есть; делай то, что попросили; делай это хорошо. Они эволюционировали от ручной оценки к LLM-грейдерам с критериями, определёнными продуктовой командой, и периодической человеческой калибровкой, и теперь регулярно запускают два отдельных набора для бенчмаркинга качества и регрессионного тестирования. Команда Bolt AI начала строить оценки позже, когда у них уже был широко используемый агент. За 3 месяца они создали систему оценки, которая запускает их агента и оценивает результаты с помощью статического анализа, использует браузерных агентов для тестирования приложений и применяет LLM-судей для оценки поведения, например, следования инструкциям.
Некоторые команды создают оценки в начале разработки; другие добавляют их, уже работая в масштабе, когда оценки становятся узким местом для улучшения агента. Оценки особенно полезны в начале разработки агента для явного кодирования ожидаемого поведения. Два инженера, прочитавшие одну и ту же начальную спецификацию, могут по-разному интерпретировать, как ИИ должен обрабатывать граничные случаи. Набор оценок устраняет эту двусмысленность. Независимо от того, когда они созданы, оценки помогают ускорить разработку.
Оценки также влияют на скорость перехода на новые модели. Когда выходят более мощные модели, команды без оценок тратят недели на тестирование, тогда как конкуренты с оценками могут быстро определить сильные стороны модели, настроить свои промпты и обновиться за считаные дни.
Когда оценки созданы, базовые показатели и регрессионные тесты достаются бесплатно: задержку, расход токенов, стоимость за задачу и частоту ошибок можно отслеживать на фиксированном наборе задач. Оценки также могут стать каналом коммуникации с наибольшей пропускной способностью между продуктовой командой и исследователями, определяя метрики, которые исследователи могут оптимизировать. Очевидно, что преимущества оценок выходят далеко за пределы отслеживания регрессий и улучшений. Их кумулятивную ценность легко упустить, поскольку затраты видны сразу, а выгоды накапливаются позже.
Как оценивать AI-агентов
Сегодня мы видим несколько распространённых типов агентов, развёрнутых в масштабе: кодовые агенты, исследовательские агенты, агенты компьютерного управления и разговорные агенты. Каждый тип может быть развёрнут в самых разных отраслях, но оценивать их можно схожими методами. Не нужно изобретать оценку с нуля. В разделах ниже описаны проверенные методы для нескольких типов агентов. Используйте эти подходы как основу, а затем расширяйте их для своей предметной области.
Типы грейдеров для агентов
Оценки агентов обычно сочетают три типа грейдеров: на основе кода, на основе модели и человеческие. Каждый грейдер оценивает определённую часть транскрипта или исхода. Существенная составляющая эффективного дизайна оценки — выбрать правильные грейдеры для задачи.
Грейдеры на основе кода
Грейдеры на основе модели
Оценка по рубрикеУтверждения на естественном языкеПопарное сравнениеОценка по эталонуКонсенсус нескольких судей
ГибкиеМасштабируемыеУлавливают нюансыПодходят для открытых задачПодходят для свободного формата вывода
НедетерминированныеДороже кодовых грейдеровТребуют калибровки с человеческими оценщиками для точности
Человеческие грейдеры
Экспертная рецензияКраудсорсинговая оценкаВыборочная проверкаA/B-тестированиеСогласованность между оценщиками
Золотой стандарт качестваСоответствует суждению экспертного пользователяИспользуется для калибровки модельных грейдеров
ДорогоМедленноЧасто требует доступа к экспертам в масштабе
Для каждой задачи оценка может быть взвешенной (суммарные баллы грейдеров должны достичь порога), бинарной (все грейдеры должны пройти) или гибридной.
Оценки возможностей и регрессионные оценки
Оценки возможностей, или оценки «качества», задают вопрос: «Что этот агент делает хорошо?» Они должны начинаться с низкой доли успеха, нацеливаясь на задачи, с которыми агент справляется плохо, давая командам цель для улучшения.
Регрессионные оценки задают вопрос: «Справляется ли агент по-прежнему со всеми задачами, которые он решал раньше?» — и должны иметь долю успеха, близкую к 100%. Они защищают от деградации: снижение результата сигнализирует, что что-то сломалось и требует исправления. По мере того как команды улучшают показатели оценок возможностей, важно также запускать регрессионные оценки, чтобы изменения не вызывали проблем в других местах.
После запуска и оптимизации агента оценки возможностей с высокой долей успеха могут «выпуститься» в регрессионный набор, который запускается непрерывно для обнаружения любого дрейфа. Задачи, которые когда-то измеряли «Можем ли мы это вообще сделать?», начинают измерять «Можем ли мы по-прежнему делать это надёжно?»
Оценка кодовых агентов
Кодовые агенты пишут, тестируют и отлаживают код, навигируя по кодовым базам и выполняя команды подобно разработчику. Эффективные оценки для современных кодовых агентов обычно опираются на чётко сформулированные задачи, стабильные тестовые среды и тщательные тесты для сгенерированного кода.
Детерминистические грейдеры естественны для кодовых агентов, потому что программное обеспечение в целом легко оценить: запускается ли код и проходят ли тесты? Два широко используемых бенчмарка для кодовых агентов — SWE-bench Verified и Terminal-Bench — следуют этому подходу. SWE-bench Verified предоставляет агентам GitHub-issues из популярных Python-репозиториев и оценивает решения, запуская набор тестов; решение проходит, только если исправляет падающие тесты, не ломая существующие. LLM прогрессировали от 40% до >80% на этой оценке всего за один год. Terminal-Bench идёт другим путём: он тестирует сквозные технические задачи, такие как сборка ядра Linux из исходников или обучение ML-модели.
Когда у вас есть набор тестов «прошёл/не прошёл» для валидации ключевых исходов кодовой задачи, часто полезно также оценивать транскрипт. Например, эвристические правила качества кода могут оценивать сгенерированный код не только по прохождению тестов, а модельные грейдеры с чёткими рубриками — оценивать поведение агента: как он вызывает инструменты или взаимодействует с пользователем.
Пример: теоретическая оценка для кодового агента
Рассмотрим кодовую задачу, в которой агент должен исправить уязвимость обхода аутентификации. Как показано в иллюстративном YAML-файле ниже, такого агента можно оценить с помощью как грейдеров, так и метрик.
task: id: "fix-auth-bypass_1" desc: "Fix authentication bypass when password field is empty and ..." graders: - type: deterministic_tests required: [test_empty_pw_rejected.py, test_null_pw_rejected.py] - type: llm_rubric rubric: prompts/code_quality.md - type: static_analysis commands: [ruff, mypy, bandit] - type: state_check expect: security_logs: {event_type: "auth_blocked"} - type: tool_calls required: - {tool: read_file, params: {path: "src/auth/*"}} - {tool: edit_file} - {tool: run_tests} tracked_metrics: - type: transcript metrics: - n_turns - n_toolcalls - n_total_tokens - type: latency metrics: - time_to_first_token - output_tokens_per_sec - time_to_last_token
Обратите внимание, что этот пример демонстрирует полный спектр доступных грейдеров для наглядности. На практике оценки кода обычно опираются на юнит-тесты для проверки корректности и LLM-рубрику для оценки общего качества кода, а дополнительные грейдеры и метрики добавляются по мере необходимости.
Оценка разговорных агентов
Разговорные агенты взаимодействуют с пользователями в таких областях, как поддержка, продажи или коучинг. В отличие от традиционных чат-ботов, они поддерживают состояние, используют инструменты и выполняют действия в ходе разговора. Хотя кодовые и исследовательские агенты тоже могут включать множество шагов взаимодействия с пользователем, разговорные агенты ставят особую задачу: качество самого взаимодействия — часть того, что вы оцениваете. Эффективные оценки для разговорных агентов обычно опираются на проверяемые конечные состояния и рубрики, которые охватывают как выполнение задачи, так и качество взаимодействия. В отличие от большинства других оценок, они часто требуют второй LLM для имитации пользователя. Мы используем этот подход в наших агентах аудита выравнивания для стресс-тестирования моделей через длительные состязательные диалоги.
Успех разговорных агентов может быть многомерным: решён ли тикет (проверка состояния), завершился ли диалог менее чем за 10 шагов (ограничение транскрипта) и был ли тон уместным (LLM-рубрика)? Два бенчмарка, учитывающих многомерность — 𝜏-Bench и его преемник τ2-Bench. Они моделируют многошаговые взаимодействия в таких областях, как розничная поддержка и бронирование авиабилетов, где одна модель играет роль пользователя, а агент решает реалистичные сценарии.
Пример: теоретическая оценка для разговорного агента
Рассмотрим задачу поддержки, в которой агент должен обработать возврат средств для расстроенного клиента.
graders: - type: llm_rubric rubric: prompts/support_quality.md assertions: - "Agent showed empathy for customer's frustration" - "Resolution was clearly explained" - "Agent's response grounded in fetch_policy tool results" - type: state_check expect: tickets: {status: resolved} refunds: {status: processed} - type: tool_calls required: - {tool: verify_identity} - {tool: process_refund, params: {amount: "<=100"}} - {tool: send_confirmation} - type: transcript max_turns: 10 tracked_metrics: - type: transcript metrics: - n_turns - n_toolcalls - n_total_tokens - type: latency metrics: - time_to_first_token - output_tokens_per_sec - time_to_last_token
Как и в нашем примере с кодовым агентом, эта задача демонстрирует несколько типов грейдеров для наглядности. На практике оценки разговорных агентов обычно используют модельные грейдеры для оценки как качества коммуникации, так и достижения цели, поскольку многие задачи — например, ответ на вопрос — могут иметь несколько «правильных» решений.
Оценка исследовательских агентов
Исследовательские агенты собирают, синтезируют и анализируют информацию, а затем создают результат — ответ или отчёт. В отличие от кодовых агентов, где юнит-тесты дают бинарный сигнал «прошёл/не прошёл», качество исследования можно оценить только относительно задачи. Что считать «исчерпывающим», «хорошо подкреплённым источниками» или даже «правильным» — зависит от контекста: обзор рынка, due diligence при поглощении и научный отчёт требуют разных стандартов.
Оценки исследований сталкиваются с уникальными вызовами: эксперты могут расходиться во мнениях о том, является ли синтез исчерпывающим; эталонные данные меняются, поскольку справочный контент постоянно обновляется; а более длинные и открытые результаты создают больше возможностей для ошибок. Бенчмарк вроде BrowseComp, например, проверяет, могут ли AI-агенты находить иголки в стогах сена по всему открытому вебу — вопросы, которые легко проверить, но трудно решить.
Одна из стратегий построения оценок исследовательских агентов — комбинирование типов грейдеров. Проверки обоснованности удостоверяют, что утверждения подкреплены найденными источниками; проверки покрытия определяют ключевые факты, которые должен содержать хороший ответ; проверки качества источников подтверждают, что использованные источники авторитетны, а не просто первые найденные. Для задач с объективно правильными ответами («Какова была выручка компании X за Q3?») работает точное совпадение. LLM может отмечать необоснованные утверждения и пробелы в покрытии, а также проверять открытый синтез на связность и полноту.
Учитывая субъективный характер качества исследований, LLM-рубрики следует регулярно калибровать по экспертным человеческим суждениям, чтобы эффективно оценивать таких агентов.
Агенты компьютерного управления
Агенты компьютерного управления взаимодействуют с программным обеспечением через тот же интерфейс, что и люди — скриншоты, клики мышью, ввод с клавиатуры и прокрутку — а не через API или выполнение кода. Они могут использовать любое приложение с графическим интерфейсом (GUI), от инструментов дизайна до устаревшего корпоративного ПО. Оценка требует запуска агента в реальной или песочной среде, где он может использовать программные приложения, и проверки, достиг ли он намеченного результата. Например, WebArena тестирует задачи в браузере, используя проверки URL и состояния страницы для подтверждения корректной навигации, а также проверку состояния бэкенда для задач, изменяющих данные (подтверждая, что заказ действительно размещён, а не просто отображена страница подтверждения). OSWorld расширяет это до полного управления операционной системой, с оценочными скриптами, которые проверяют разнообразные артефакты после выполнения задачи: состояние файловой системы, конфигурации приложений, содержимое баз данных и свойства элементов UI.
Агенты для работы в браузере требуют баланса между эффективностью использования токенов и задержкой. Взаимодействие на основе DOM выполняется быстро, но потребляет много токенов, тогда как взаимодействие на основе скриншотов медленнее, но эффективнее по токенам. Например, когда вы просите Claude обобщить Wikipedia, эффективнее извлечь текст из DOM. Когда нужно найти новый чехол для ноутбука на Amazon, эффективнее делать скриншоты (поскольку извлечение всего DOM требует много токенов). В нашем продукте Claude for Chrome мы разработали оценки для проверки, что агент выбирает правильный инструмент для каждого контекста. Это позволило нам выполнять браузерные задачи быстрее и точнее.
Как рассматривать недетерминированность в оценках агентов
Независимо от типа агента, его поведение варьируется между запусками, что делает результаты оценки сложнее для интерпретации, чем кажется на первый взгляд. У каждой задачи своя доля успеха — возможно, 90% для одной задачи и 50% для другой — и задача, которая прошла на одном запуске оценки, может провалиться на следующем. Иногда нас интересует, как часто (в какой доле проб) агент успешно справляется с задачей.
Две метрики помогают уловить этот нюанс:
pass@k измеряет вероятность того, что агент получит хотя бы одно правильное решение за k попыток. С увеличением k показатель pass@k растёт: больше «ударов по воротам» означает больше шансов на хотя бы 1 успех. Показатель 50% pass@1 означает, что модель справляется с половиной задач в оценке с первой попытки. В кодировании нас чаще всего интересует, найдёт ли агент решение с первой попытки — pass@1. В других случаях допустимо предложить много решений, если хотя бы одно сработает.
pass^k измеряет вероятность того, что все k проб будут успешными. С увеличением k показатель pass^k падает, поскольку требование стабильности на большем числе проб — более высокая планка. Если ваш агент имеет 75% успеха за пробу и вы проводите 3 пробы, вероятность прохождения всех трёх составляет (0.75)³ ≈ 42%. Эта метрика особенно важна для клиентских агентов, где пользователи ожидают надёжного поведения каждый раз.
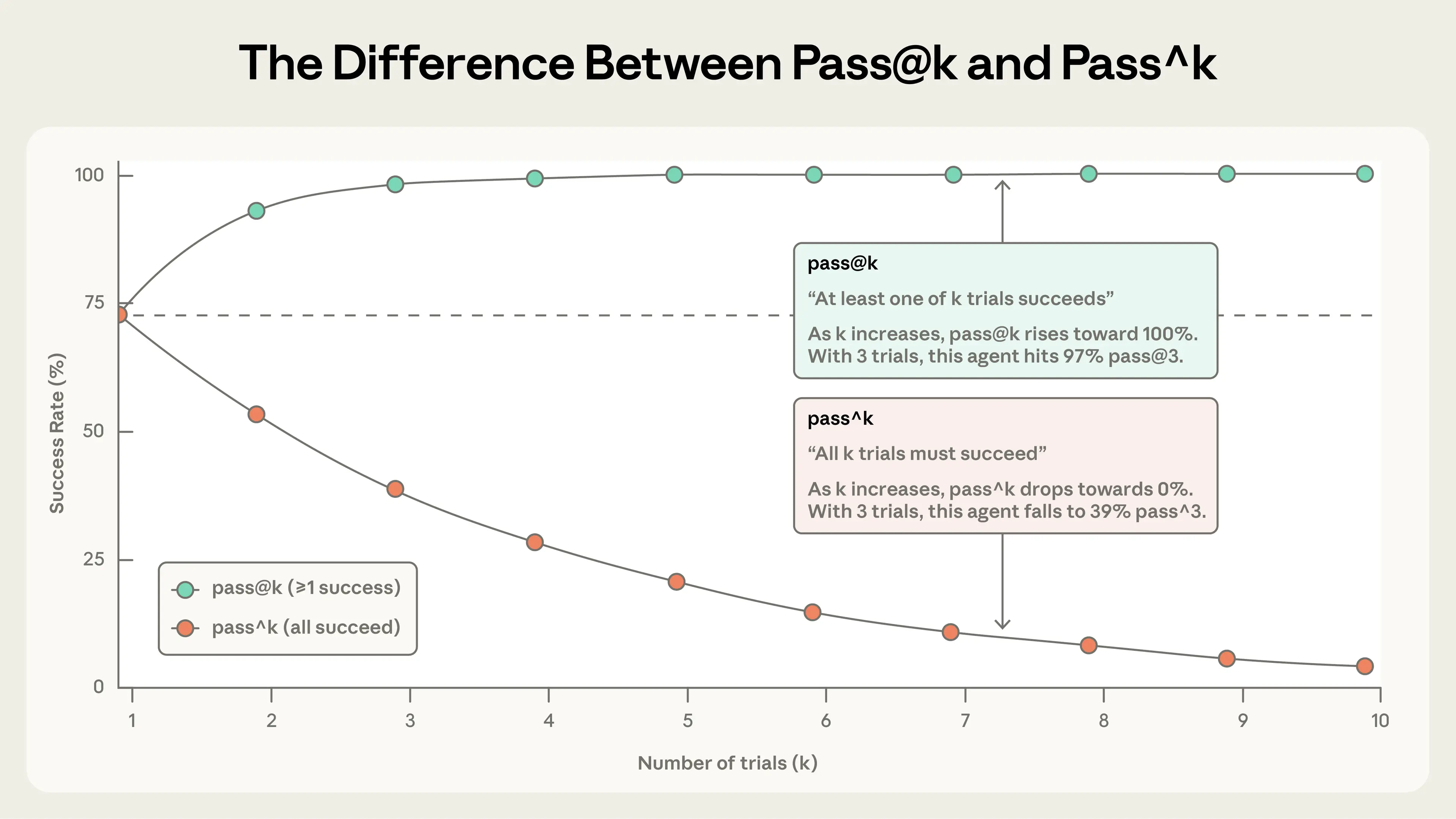
Обе метрики полезны, и выбор зависит от требований продукта: pass@k для инструментов, где важен один успех, pass^k для агентов, где критична стабильность.
От нуля к единице: дорожная карта к отличным оценкам агентов
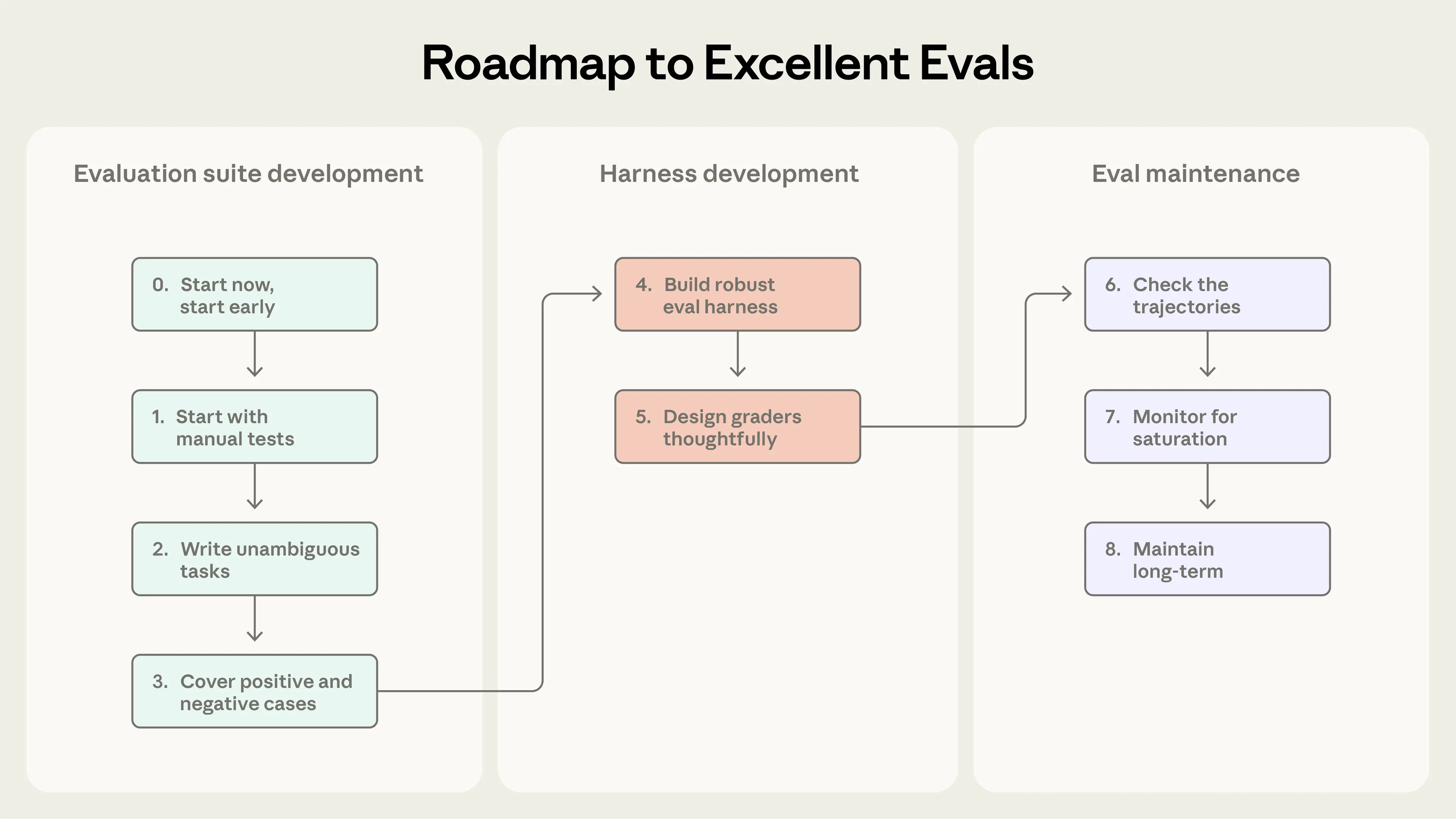
Этот раздел излагает наши практические, проверенные на деле рекомендации по переходу от полного отсутствия оценок к оценкам, которым можно доверять. Считайте это дорожной картой разработки агентов на основе оценок: определяйте успех заранее, измеряйте его чётко и итерируйте непрерывно.
Соберите задачи для начального набора оценок
Шаг 0. Начните рано
Мы видим, как команды откладывают создание оценок, полагая, что им нужны сотни задач. На самом деле 20–50 простых задач, составленных из реальных сбоев — отличное начало. В конце концов, на ранних стадиях разработки агента каждое изменение системы часто оказывает заметное влияние, и этот большой размер эффекта означает, что малых выборок достаточно. Более зрелым агентам могут потребоваться более крупные и сложные оценки для обнаружения мелких эффектов, но в начале лучше применять принцип 80/20. Оценки становится сложнее строить, чем дольше вы ждёте. На ранних этапах требования к продукту естественным образом превращаются в тестовые случаи. Ждёте слишком долго — и вам придётся обратным инжинирингом извлекать критерии успеха из работающей системы.
Шаг 1. Начните с того, что вы уже тестируете вручную
Начните с тех ручных проверок, которые вы выполняете при разработке — поведений, которые вы верифицируете перед каждым релизом, и типовых задач, которые пробуют конечные пользователи. Если вы уже в продакшене, загляните в баг-трекер и очередь обращений в поддержку. Преобразование пользовательских отчётов об ошибках в тестовые случаи гарантирует, что ваш набор отражает реальное использование; приоритизация по влиянию на пользователей помогает вкладывать усилия туда, где они наиболее ценны.
Шаг 2: Пишите однозначные задачи с эталонными решениями
Добиться правильного качества задач сложнее, чем кажется. Хорошая задача — это задача, для которой два эксперта в предметной области независимо пришли бы к одному и тому же вердикту «прошёл/не прошёл». Смогли бы они сами пройти эту задачу? Если нет, задачу нужно доработать. Двусмысленность в спецификациях задач превращается в шум в метриках. То же касается критериев для модельных грейдеров: размытые рубрики дают непоследовательные оценки.
Каждая задача должна быть решаемой агентом, который корректно следует инструкциям. Это может быть неочевидно. Например, аудит Terminal-Bench показал, что если задача просит агента написать скрипт, но не указывает путь к файлу, а тесты предполагают конкретный путь, агент может провалиться не по своей вине. Всё, что проверяет грейдер, должно быть ясно из описания задачи; агенты не должны проваливаться из-за двусмысленных спецификаций. При работе с передовыми моделями 0% прохождений на множестве проб (т. е. 0% pass@100) чаще всего сигнализирует о сломанной задаче, а не о неспособном агенте, и является поводом перепроверить спецификацию задачи и грейдеры. Для каждой задачи полезно создать эталонное решение: заведомо рабочий результат, проходящий все грейдеры. Это доказывает, что задача решаема, и подтверждает корректность настройки грейдеров.
Шаг 3: Создавайте сбалансированные наборы задач
Тестируйте как случаи, когда поведение должно проявиться, так и когда оно не должно. Односторонние оценки ведут к односторонней оптимизации. Например, если вы тестируете только, ищет ли агент когда нужно, вы можете получить агента, который ищет почти по любому поводу. Старайтесь избегать несбалансированных по классам оценок. Мы усвоили это на собственном опыте при создании оценок для веб-поиска в Claude.ai. Задача заключалась в том, чтобы не дать модели искать, когда не нужно, при этом сохранив её способность проводить обширное исследование, когда это уместно. Команда создала оценки в обоих направлениях: запросы, по которым модель должна искать (например, узнать погоду), и запросы, на которые она должна ответить из имеющихся знаний (например, «кто основал Apple?»). Найти правильный баланс между недостаточным срабатыванием (не ищет, когда нужно) и избыточным срабатыванием (ищет, когда не нужно) было непросто, и потребовалось много итераций как промптов, так и самой оценки. По мере появления новых примеров мы продолжаем пополнять оценки для улучшения покрытия.
Спроектируйте среду оценки и грейдеры
Шаг 4: Создайте надёжную среду оценки со стабильным окружением
Крайне важно, чтобы агент в оценке функционировал примерно так же, как агент в продакшене, и чтобы само окружение не вносило дополнительный шум. Каждая проба должна быть «изолирована», начинаясь с чистого окружения. Ненужное общее состояние между запусками (оставшиеся файлы, кешированные данные, исчерпание ресурсов) может вызывать коррелированные сбои из-за нестабильности инфраструктуры, а не производительности агента. Общее состояние может также искусственно завышать результаты. Например, в некоторых внутренних оценках мы заметили, что Claude получал нечестное преимущество на отдельных задачах, изучая историю git от предыдущих проб. Если несколько разных проб проваливаются из-за одного и того же ограничения среды (например, недостаточного объёма оперативной памяти), эти пробы не являются независимыми, поскольку на них влияет один и тот же фактор, и результаты оценки становятся ненадёжными для измерения производительности агента.
Шаг 5: Проектируйте грейдеры вдумчиво
Как обсуждалось выше, хороший дизайн оценки предполагает выбор лучших грейдеров для агента и задач. Мы рекомендуем использовать детерминистические грейдеры, где это возможно, LLM-грейдеры, где это необходимо или для дополнительной гибкости, и человеческих оценщиков — с умом для дополнительной валидации.
Существует распространённый инстинкт проверять, что агент следовал строго определённым шагам, например, последовательности вызовов инструментов в правильном порядке. Мы обнаружили, что этот подход слишком жёсткий и приводит к чрезмерно хрупким тестам, поскольку агенты регулярно находят допустимые подходы, которых проектировщики оценки не предвидели. Чтобы не наказывать за креативность, зачастую лучше оценивать то, что агент произвёл, а не путь, которым он шёл.
Для задач с несколькими компонентами предусмотрите частичный зачёт. Агент поддержки, который верно определил проблему и верифицировал клиента, но не обработал возврат, значительно лучше того, который провалился сразу. Важно отражать этот континуум успеха в результатах.
Оценивание моделью часто требует тщательной итерации для подтверждения точности. LLM-судей следует тщательно калибровать с человеческими экспертами, чтобы убедиться в малом расхождении между человеческой и модельной оценкой. Чтобы избежать галлюцинаций, дайте LLM возможность отступить, например, инструкцию возвращать «Неизвестно», когда информации недостаточно. Также помогает создавать чёткие, структурированные рубрики для оценки каждого измерения задачи и оценивать каждое измерение отдельным LLM-судьёй, а не одним для всех измерений. Когда система надёжна, достаточно прибегать к человеческой рецензии лишь изредка.
Некоторые оценки имеют тонкие режимы отказа, приводящие к низким баллам даже при хорошей работе агента, поскольку агент не решает задачи из-за ошибок в оценивании, ограничений среды агента или двусмысленности. Даже опытные команды могут упустить эти проблемы. Например, Opus 4.5 изначально набрал 42% на CORE-Bench, пока исследователь Anthropic не обнаружил множество проблем: жёсткое оценивание, штрафующее «96.12» при ожидании «96.124991…», двусмысленные спецификации задач и стохастические задачи, которые невозможно было точно воспроизвести. После исправления ошибок и использования менее ограничивающей среды результат Opus 4.5 подскочил до 95%. Аналогично, METR обнаружили несколько неправильно настроенных задач в их бенчмарке временного горизонта, которые просили агентов оптимизировать до заявленного порога баллов, но оценивание требовало превышения этого порога. Это штрафовало модели вроде Claude за следование инструкциям, тогда как модели, игнорирующие заявленную цель, получали лучшие оценки. Тщательная перепроверка задач и грейдеров помогает избежать этих проблем.
Сделайте ваши грейдеры устойчивыми к обходам и хакам. Агент не должен иметь возможность легко «обмануть» оценку. Задачи и грейдеры должны быть спроектированы так, чтобы прохождение действительно требовало решения проблемы, а не эксплуатации непредусмотренных лазеек.
Поддерживайте и используйте оценку в долгосрочной перспективе
Шаг 6: Проверяйте транскрипты
Вы не узнаете, хорошо ли работают ваши грейдеры, пока не прочитаете транскрипты и оценки множества проб. В Anthropic мы инвестировали в инструменты для просмотра транскриптов оценок и регулярно уделяем время их чтению. Когда задача проваливается, транскрипт показывает, допустил ли агент реальную ошибку или ваши грейдеры отклонили допустимое решение. Он также часто выявляет важные детали о поведении агента и оценки.
Провалы должны выглядеть справедливыми: ясно, что именно агент сделал неправильно и почему. Когда показатели не растут, нужна уверенность, что причина в производительности агента, а не в самой оценке. Чтение транскриптов — это способ убедиться, что ваша оценка измеряет то, что действительно важно, и это критически важный навык для разработки агентов.
Шаг 7: Отслеживайте насыщение оценок возможностей
Оценка со 100% прохождением отслеживает регрессии, но не даёт сигнала для улучшений. Насыщение оценки происходит, когда агент проходит все решаемые задачи, не оставляя пространства для роста. Например, результаты SWE-Bench Verified начинались с 30% в этом году, а передовые модели сейчас приближаются к насыщению на уровне >80%. По мере приближения к насыщению прогресс также замедляется, так как остаются только самые сложные задачи. Это может делать результаты обманчивыми, поскольку большие улучшения возможностей выглядят как малые приросты в баллах. Например, стартап по ревью кода Qodo изначально не был впечатлён Opus 4.5, потому что их одношаговые кодовые оценки не фиксировали прирост на более длинных и сложных задачах. В ответ они разработали новый агентный фреймворк оценки, который дал гораздо более ясную картину прогресса.
Как правило, мы не принимаем результаты оценок за чистую монету, пока кто-то не разберётся в деталях оценки и не прочитает часть транскриптов. Если оценивание несправедливо, задачи двусмысленны, допустимые решения штрафуются или среда ограничивает модель — оценку следует пересмотреть.
Шаг 8: Поддерживайте здоровье наборов оценок в долгосрочной перспективе через открытый вклад и сопровождение
Набор оценок — это живой артефакт, который требует постоянного внимания и чёткого владения, чтобы оставаться полезным.
В Anthropic мы экспериментировали с различными подходами к сопровождению оценок. Наиболее эффективным оказалось создание выделенных команд по оценкам для владения базовой инфраструктурой, тогда как доменные эксперты и продуктовые команды вносят большинство задач оценки и сами запускают оценки.
Для продуктовых команд, работающих с ИИ, владение и итерация оценок должны быть столь же привычными, как сопровождение юнит-тестов. Команды могут потратить недели на AI-функции, которые «работают» при раннем тестировании, но не соответствуют невысказанным ожиданиям, которые хорошо спроектированная оценка выявила бы рано. Определение задач для оценки — один из лучших способов проверить, достаточно ли конкретны требования к продукту, чтобы начинать разработку.
Мы рекомендуем практиковать разработку на основе оценок: создавайте оценки для определения планируемых возможностей до того, как агент сможет их реализовать, а затем итерируйте, пока агент не покажет хорошие результаты. Внутри компании мы часто создаём функции, которые «достаточно хорошо» работают сегодня, но являются ставками на то, что модели смогут делать через несколько месяцев. Оценки возможностей, начинающиеся с низкой доли прохождения, делают это видимым. Когда выходит новая модель, запуск набора быстро показывает, какие ставки оправдались.
Люди, наиболее близкие к требованиям продукта и пользователям, лучше всего подготовлены для определения успеха. С текущими возможностями моделей продакт-менеджеры, менеджеры по успеху клиентов или менеджеры по продажам могут использовать Claude Code для внесения задачи оценки в виде PR — позвольте им это делать! Или, ещё лучше, активно содействуйте этому.
Как оценки вписываются в другие методы для целостного понимания агентов
Автоматические оценки можно запускать на тысячах задач без развёртывания в продакшен и без влияния на реальных пользователей. Но это лишь один из множества способов понять производительность агента. Полная картина включает мониторинг в продакшене, обратную связь от пользователей, A/B-тестирование, ручной просмотр транскриптов и систематическую человеческую оценку.
Обзор подходов к пониманию производительности AI-агентов
Более быстрая итерацияПолная воспроизводимостьНет влияния на пользователейМожно запускать при каждом коммитеТестирует сценарии в масштабе без необходимости развёртывания в продакшене
Требует значительных начальных инвестиций в созданиеТребует постоянного сопровождения по мере эволюции продукта и модели во избежание дрейфаМожет создавать ложную уверенность, если не совпадает с реальными паттернами использования
Выявляет реальное поведение пользователей в масштабеОбнаруживает проблемы, которые пропускают синтетические оценкиПредоставляет ground truth о фактической производительности агентов
Реактивный подход; проблемы доходят до пользователей до того, как вы о них узнаётеСигналы могут быть зашумлённымиТребует инвестиций в инструментированиеОтсутствует ground truth для оценивания
Измеряет реальные пользовательские результаты (удержание, завершение задач)Контролирует смешивающие факторыМасштабируемо и систематично
Медленно; дни или недели для достижения статистической значимости, требует достаточного трафикаТестирует только те изменения, которые вы развернулиМеньше сигнала об основных причинах изменения метрик без возможности тщательно изучить транскрипты
Выявляет проблемы, которые вы не предвиделиСопровождается реальными примерами от реальных пользователейОбратная связь часто коррелирует с целями продукта
Разреженная и смещённая в сторону самостоятельно обратившихсяСклоняется к серьёзным проблемамПользователи редко объясняют, почему что-то не сработалоНе автоматизированаОсновная опора на пользователей для обнаружения проблем может негативно влиять на пользовательский опыт
Развивает интуицию в отношении режимов отказаВыявляет тонкие проблемы качества, которые пропускают автоматические проверкиПомогает калибровать, как выглядит «хорошо», и вникать в детали
ТрудоёмкоНе масштабируетсяПокрытие непоследовательноУсталость рецензентов или разные рецензенты могут влиять на качество сигналаОбычно даёт только качественный сигнал, а не чёткую количественную оценку
Эталонные суждения о качестве от нескольких человеческих оценщиковПодходит для субъективных или двусмысленных задачДаёт сигнал для улучшения модельных грейдеров
Относительно дорого и медленноСложно проводить частоРасхождения между оценщиками требуют согласованияСложные области (юриспруденция, финансы, здравоохранение) требуют привлечения человеческих экспертов для проведения исследований
Эти методы соответствуют различным стадиям разработки агента. Автоматические оценки особенно полезны до запуска и в CI/CD — они запускаются при каждом изменении агента и обновлении модели как первая линия защиты от проблем с качеством. Мониторинг в продакшене включается после запуска для обнаружения дрейфа распределения и непредвиденных сбоев в реальных условиях. A/B-тестирование валидирует значительные изменения при наличии достаточного трафика. Обратная связь от пользователей и просмотр транскриптов — это непрерывные практики для заполнения пробелов: постоянно разбирайте обратную связь, еженедельно читайте выборку транскриптов и углубляйтесь по мере необходимости. Систематические человеческие исследования оставляйте для калибровки LLM-грейдеров или оценки субъективных результатов, где консенсус людей служит эталонным стандартом.
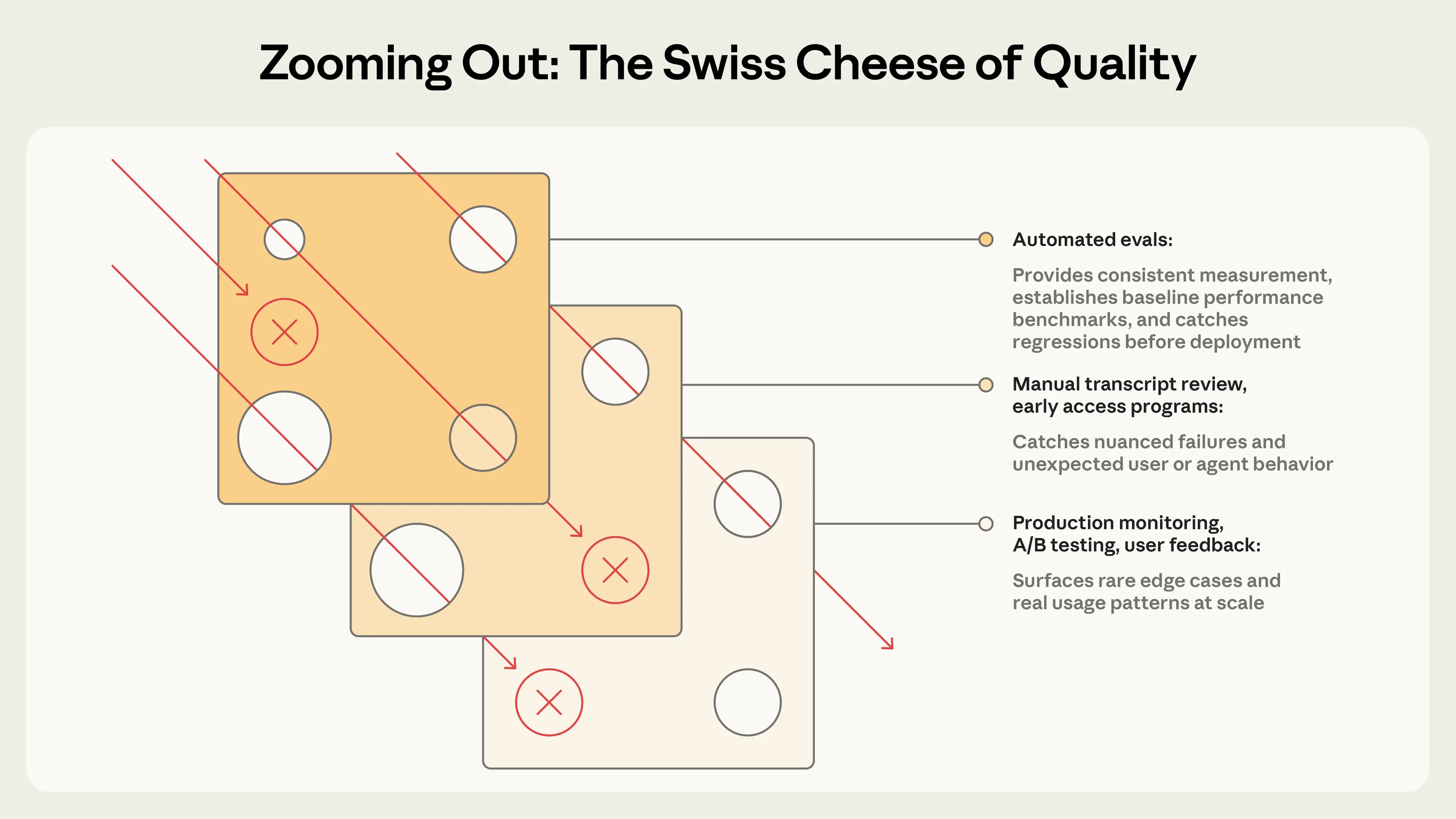
Наиболее эффективные команды сочетают эти методы: автоматические оценки для быстрой итерации, мониторинг в продакшене для ground truth и периодический человеческий обзор для калибровки.
Заключение
Команды без оценок увязают в реактивных циклах — исправляют один сбой, создают другой, не в силах отличить реальные регрессии от шума. Команды, которые инвестируют рано, обнаруживают обратное: разработка ускоряется, поскольку сбои превращаются в тестовые случаи, тестовые случаи предотвращают регрессии, а метрики заменяют догадки. Оценки дают всей команде ясную цель для улучшения, превращая «агент стал хуже» в нечто действенное. Ценность накапливается, но только если вы относитесь к оценкам как к ключевому компоненту, а не запоздалой мысли.
Паттерны различаются в зависимости от типа агента, но описанные здесь основы неизменны. Начинайте рано и не ждите идеального набора. Берите реалистичные задачи из наблюдаемых сбоев. Определяйте однозначные, надёжные критерии успеха. Продумывайте грейдеры и сочетайте несколько типов. Убедитесь, что задачи достаточно сложны для модели. Итерируйте над оценками, чтобы улучшить соотношение сигнал-шум. Читайте транскрипты!
Оценка AI-агентов — это всё ещё зарождающаяся, быстро развивающаяся область. По мере того как агенты берутся за более длительные задачи, сотрудничают в мультиагентных системах и выполняют всё более субъективную работу, нам нужно будет адаптировать наши методы. Мы продолжим делиться лучшими практиками по мере накопления опыта.
Благодарности
Авторы: Mikaela Grace, Jeremy Hadfield, Rodrigo Olivares и Jiri De Jonghe. Мы также благодарны David Hershey, Gian Segato, Mike Merrill, Alex Shaw, Nicholas Carlini, Ethan Dixon, Pedram Navid, Jake Eaton, Alyssa Baum, Lina Tawfik, Karen Zhou, Alexander Bricken, Sam Kennedy, Robert Ying и другим за их вклад. Особая благодарность клиентам и партнёрам, у которых мы учились в ходе совместной работы над оценками, включая iGent, Cognition, Bolt, Sierra, Vals.ai, Macroscope, PromptLayer, Stripe, Shopify, команду Terminal Bench и других. Эта работа отражает коллективные усилия нескольких команд, которые помогли развить практику оценок в Anthropic.
Приложение: фреймворки для оценок
Несколько open-source и коммерческих фреймворков помогут командам реализовать оценки агентов без создания инфраструктуры с нуля. Правильный выбор зависит от типа вашего агента, существующего стека и того, нужна ли вам офлайн-оценка, наблюдаемость в продакшене или и то, и другое.Harbor предназначен для запуска агентов в контейнеризованных средах, с инфраструктурой для проведения проб в масштабе у различных облачных провайдеров и стандартизированным форматом для определения задач и грейдеров. Популярные бенчмарки, такие как Terminal-Bench 2.0, распространяются через реестр Harbor, что упрощает запуск как устоявшихся бенчмарков, так и пользовательских наборов оценок.Braintrust — это платформа, сочетающая офлайн-оценку с наблюдаемостью в продакшене и отслеживанием экспериментов, полезная для команд, которым нужно итерировать в процессе разработки и мониторить качество в продакшене. Его библиотека `autoevals` включает готовые скореры для фактологичности, релевантности и других распространённых измерений. LangSmith предлагает трассировку, офлайн- и онлайн-оценки и управление датасетами с тесной интеграцией в экосистему LangChain. Langfuse предоставляет аналогичные возможности в виде self-hosted open-source альтернативы для команд с требованиями к размещению данных.
Arize предлагает Phoenix — open-source платформу для трассировки, отладки и офлайн- или онлайн-оценки LLM, а также AX — SaaS-решение, расширяющее Phoenix для масштабирования, оптимизации и мониторинга. Многие команды комбинируют несколько инструментов, создают собственный фреймворк оценки или просто используют простые скрипты оценки как отправную точку. Мы считаем, что хотя фреймворки могут быть ценным способом ускорить прогресс и стандартизировать процесс, они хороши лишь настолько, насколько хороши задачи оценки, которые вы через них прогоняете. Зачастую лучше быстро выбрать фреймворк, подходящий вашему рабочему процессу, а затем вложить энергию в сами оценки, итерируя над высококачественными тестовыми случаями и грейдерами.