
A new generation of AIs: Claude 3.7 and Grok 3
Итан Моллик описывает впечатления от нового поколения ИИ-моделей — Claude 3.7 и Grok 3 — отмечая резкий скачок в сложных задачах, математике и программировании. Автор объясняет два закона масштабирования: рост вычислительных мощностей при обучении (Gen3-модели используют свыше 10^26 FLOPS, в 10 раз больше GPT-4) и масштабирование во время инференса через Reasoners. Grok 3 от xAI стал первой публичной Gen3-моделью благодаря крупнейшему кластеру, Claude 3.7 пока не Gen3, но показывает заметный прогресс, а нераскрытая o3 от OpenAI также относится к новому поколению. Способности ИИ растут, а стоимость падает: Gemini 1.5 Flash стоит около 12 центов за миллион токенов против ~50 долларов у изначального GPT-4. Моллик призывает руководителей отказаться от «мышления автоматизации» и рассматривать ИИ как интеллектуального партнёра для задач уровня PhD. В завершение он советует экспериментировать самостоятельно с Claude 3.7 и Grok 3, отмечая разницу в приватности и подходах компаний.
Новое поколение ИИ: Claude 3.7 и Grok 3
Да, ИИ снова внезапно стал лучше... опять
Примечание: после публикации этой статьи со мной связались представители Anthropic и сообщили, что Sonnet 3.7 не считается моделью на 10^26 FLOP и его обучение стоило несколько десятков миллионов долларов, хотя будущие модели будут значительно крупнее. Я обновил пост с учётом этой информации. Единственное существенное изменение — Claude 3 теперь называется продвинутой моделью, но не моделью Gen3.
Последние несколько дней я экспериментирую с первыми моделями нового поколения ИИ — Claude 3.7 и Grok 3. Grok 3 — первая известная нам модель, обученная с использованием на порядок большей вычислительной мощности, чем GPT-4, а Claude получил новые возможности в кодировании и рассуждениях, так что они интересны не только сами по себе, но и говорят нам нечто важное о том, куда движется ИИ.
Прежде чем мы дойдём до этого, краткий обзор: новое поколение ИИ умнее, и скачок в возможностях впечатляет, особенно в том, как эти модели справляются со сложными задачами, математикой и кодом. Эти модели часто вызывают у меня то же ощущение, что и при первом использовании ChatGPT-4, когда я одновременно впечатлён и немного обеспокоен тем, что он умеет. Возьмём, например, нативную способность Claude к программированию: теперь я могу получать рабочие программы через обычный разговор или документы, без каких-либо навыков программирования.
Например, отдав Claude предложение нового ИИ-инструмента для образования и попросив его «отобразить предложенную архитектуру системы в 3D, сделать её интерактивной», я получил интерактивную визуализацию ключевого дизайна из нашей статьи, без единой ошибки. Вы можете попробовать её сами здесь и редактировать или менять, попросив ИИ. Графика, хоть и аккуратная, — не самое впечатляющее. Главное — что Claude решил превратить это в пошаговую демонстрацию для объяснения концепций, о чём его не просили. Такое предвосхищение потребностей и рассмотрение новых углов подхода — нечто новое в ИИ.
Или, для более игрового примера, я сказал Claude: «сделай мне интерактивный артефакт «машина времени», позволь мне путешествовать в прошлое, чтобы происходили интересные события. выбери необычные моменты, в которые я могу вернуться…» и «добавь больше графики». Всего после двух промптов получился полностью функциональный интерактивный опыт, дополненный грубой, но обаятельной пиксельной графикой (которая на самом деле удивительно впечатляет — ИИ приходится «рисовать» её чистым кодом, не видя, что он создаёт, как художник, рисующий с завязанными глазами, но всё равно правильно передающий картину).
Чтобы было ясно: эти системы далеки от совершенства и делают ошибки, но они становятся намного лучше, и быстро. Чтобы понять, где мы сейчас и куда движемся,
Два закона масштабирования
Хотя они могут так не выглядеть, это, возможно, два самых важных графика в ИИ. Опубликованные OpenAI, они показывают два «закона масштабирования», которые говорят, как повысить способность ИИ отвечать на сложные вопросы — в данном случае получать более высокие баллы на знаменитой своей сложностью American Invitational Mathematics Examination (AIME).

Левый график — это закон масштабирования при обучении. Он показывает, что более крупные модели обладают большими возможностями. Обучение таких более крупных моделей требует увеличения вычислительной мощности, объёма данных и энергии, причём в огромных масштабах. Как правило, нужно увеличить вычислительную мощность в 10 раз, чтобы получить линейный прирост производительности. Вычислительная мощность измеряется в FLOP (Floating Point Operations) — количестве базовых математических операций, таких как сложение или умножение, выполняемых компьютером, что даёт нам способ количественно оценить вычислительную работу при обучении ИИ.
Сейчас мы видим первые модели нового поколения ИИ, обученные более чем с 10-кратной вычислительной мощностью по сравнению с GPT-4 и его многочисленными конкурентами. Эти модели используют более 10^26 FLOPS вычислительной мощности при обучении. Это ошеломляющий объём вычислительной мощности, эквивалентный работе современного смартфона в течение 634 000 лет или Apollo Guidance Computer, который доставил людей на Луну, — в течение 79 триллионов лет. Назвать 10^26 неловко — это сто септиллионов FLOPS, или, если немного вольно обращаться со стандартными названиями единиц, HectoyottaFLOP. Поэтому вы понимаете, почему я просто называю их моделями Gen3 — первым набором ИИ, обученным с использованием на порядок большей вычислительной мощности, чем GPT-4 (Gen2).
xAI, ИИ-компания Илона Маска, сделала первый публичный шаг на территорию Gen3 с Grok 3, что неудивительно, учитывая их стратегию. xAI делает большую ставку на идею, что больше (намного больше) — значит лучше. xAI построила крупнейший в мире вычислительный кластер в рекордные сроки, и это означало, что Grok 3 стал первой ИИ-моделью, которая показала нам, выдержит ли закон масштабирования новое поколение ИИ. Похоже, что выдержал — у Grok 3 были самые высокие баллы в бенчмарках, которые мы когда-либо видели у базовой модели. Сегодня вышел Claude 3.7, и хотя это пока не модель Gen3, он также демонстрирует существенные улучшения в производительности по сравнению с предыдущими ИИ. Хотя по бенчмаркам он схож с Grok 3, лично я нахожу его более умным для моих сценариев использования, но у вас может быть иначе. Ещё не выпущенная o3 от OpenAI, по-видимому, также является моделью Gen3 с отличной производительностью. Вероятно, это только начало — больше компаний готовятся запустить собственные модели такого масштаба, включая Anthropic.
Вы могли заметить, что я ещё не упомянул второй график, тот, что справа. Если первый закон масштабирования — это направление огромных вычислительных мощностей на обучение (по сути, создание более умного ИИ с самого начала), то второй раскрывает нечто удивительное: можно заставить ИИ работать лучше, просто дав ему больше времени на размышление. OpenAI обнаружила, что если позволить модели потратить больше вычислительной мощности на проработку проблемы (то, что они называют test-time или inference-time compute), она получит лучшие результаты — что-то вроде того, как дать умному человеку несколько дополнительных минут для решения головоломки. Этот второй закон масштабирования привёл к созданию Reasoners, о которых я писал в прошлом посте. Новое поколение моделей Gen3 будут работать как Reasoners по мере необходимости, так что у них есть два преимущества: больший масштаб при обучении и возможность масштабироваться при фактическом решении задачи.
Вместе эти два тренда суперзаряжают возможности ИИ, а также добавляют другие. Если у вас есть большая, умная модель ИИ, её можно использовать для создания меньших, более быстрых и дешёвых моделей, которые всё ещё довольно умны, хоть и не настолько, как их «родитель». А если добавить возможности Reasoner даже к маленьким моделям, они становятся ещё умнее. Это значит, что возможности ИИ растут одновременно со снижением стоимости. Этот график показывает, насколько быстро развивался этот тренд: способность ИИ — по оси Y, а логарифмически снижающаяся стоимость — по оси X. Когда вышел GPT-4, он стоил около $50 за миллион токенов (примерно за слово), а теперь использование Gemini 1.5 Flash, ещё более способной модели, чем исходный GPT-4, стоит около 12 центов за миллион токенов.
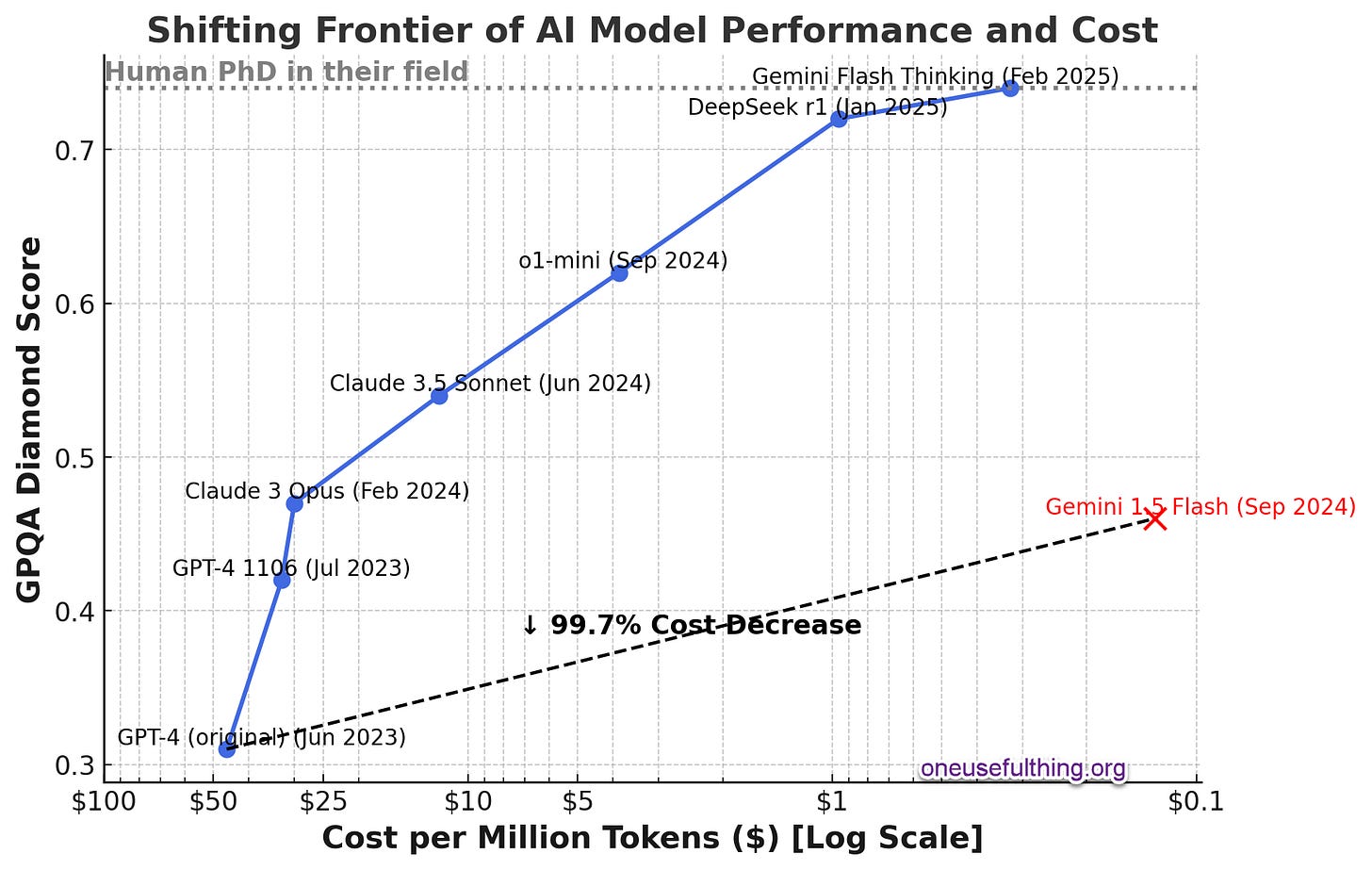
Видно, что интеллект моделей растёт, а их стоимость со временем снижается. У этого есть довольно серьёзные последствия для всех нас.
Воспринимать масштаб всерьёз
Большая часть фокуса на использовании ИИ, особенно в корпоративном мире, застряла в том, что я называю «мышлением автоматизации», — представлении об ИИ прежде всего как об инструменте ускорения существующих рабочих процессов вроде обработки почты и расшифровки встреч. Эта перспектива имела смысл для более ранних моделей ИИ, но это всё равно что оценивать смартфон исключительно по его способности совершать телефонные звонки. Поколение Gen3 даёт возможность фундаментально переосмыслить, что вообще возможно.
По мере того как модели становятся лучше и применяют больше приёмов вроде рассуждений и доступа в интернет, они меньше галлюцинируют (хотя всё ещё делают ошибки) и способны на «мышление» более высокого порядка. Например, в одном случае мы дали Claude 24-страничную академическую статью, описывающую новый способ создания обучающих игр с ИИ, вместе с не связанными с ней инструкциями для других игр. Мы попросили ИИ использовать эти примеры и написать удобное для пользователя руководство для игры на основе нашей академической статьи. Результаты оказались чрезвычайно качественными. Чтобы это сделать, ИИ должен был и абстрагировать идеи из статьи, и паттерны и подходы из других руководств, и построить нечто совершенно новое. Это была бы неделя работы уровня PhD, выполненная за несколько секунд. А справа вы также можете видеть отрывок из другой задачи уровня PhD — чтения сложной академической статьи и проверки математики и логики, а также практических импликаций.

Менеджерам и руководителям нужно будет обновить свои представления о том, что может делать ИИ и насколько хорошо он это делает, учитывая эти новые модели ИИ. Вместо того чтобы предполагать, что они способны только на низкоуровневую работу, нам придётся рассматривать, как ИИ может служить настоящим интеллектуальным партнёром. Эти модели теперь способны браться за сложные аналитические задачи, творческую работу и даже исследовательские проблемы с удивительной изощрённостью. Примеры, которыми я поделился — от создания интерактивных 3D-визуализаций академических концепций до выполнения анализа уровня PhD — демонстрируют, что мы выходим за рамки простой автоматизации в область интеллектуальной работы, основанной на ИИ. Эти системы всё ещё далеки от безупречности и не превосходят последовательно человеческих экспертов в широком спектре задач, но они очень впечатляют.
Этот сдвиг имеет глубокие последствия для того, как организациям следует подходить к интеграции ИИ. Во-первых, фокус нужно сместить с автоматизации задач на расширение возможностей. Вместо вопроса «какие задачи мы можем автоматизировать?» лидерам следует спрашивать: «какие новые возможности мы можем открыть?» И им нужно будет построить в собственных организациях компетенции, которые помогут исследовать и развивать эти изменения.
Во-вторых, быстрое улучшение как возможностей, так и эффективности затрат означает, что любая статичная стратегия внедрения ИИ быстро устареет. Организациям необходимо разрабатывать динамические подходы, которые могут эволюционировать по мере дальнейшего развития этих моделей. Сделать ставку всё на одну модель сегодня — плохой план в мире, где действуют оба закона масштабирования.
Наконец, и, возможно, самое важное: нам нужно переосмыслить, как мы измеряем и оцениваем вклад ИИ. Традиционные метрики сэкономленного времени или сокращённых затрат могут упустить более трансформационные эффекты этих систем — их способность генерировать новые инсайты, синтезировать сложную информацию и открывать новые формы решения проблем. Слишком быстрый переход к конкретным KPI и отказ от исследования ослепит компании в отношении того, что возможно. Хуже того, это побуждает компании думать об ИИ как о замене человеческого труда, а не исследовать способы, как человеческую работу можно усилить с помощью ИИ.
Исследование на собственном опыте
С этим серьёзным предупреждением в стороне, я хочу оставить вам совет. Эти новые модели умны, но они также дружелюбны и более увлекательны в использовании. Они склонны задавать вам вопросы или подталкивать ваше мышление в новых направлениях и хорошо ведут двусторонний разговор. Лучший способ понять их возможности — исследовать их самостоятельно. Claude 3.7 доступен платным пользователям и имеет интересную функцию: он может запускать код, который пишет для вас, как вы видели на протяжении этого поста. Он не обучается на ваших загруженных данных. Grok 3 бесплатный и имеет более широкий набор функций, включая хорошую опцию Deep Research, но любителям сложнее использовать его для программирования. Он не так хорош, как Claude 3.7, для задач, которые я пробовал, но приверженность xAI масштабированию означает, что он будет быстро улучшаться. Также стоит отметить, что Grok обучается на ваших данных, но это можно отключить для платных пользователей.
Независимо от того, какую модель вы выберете, экспериментируйте. Попросите модель закодить что-то для вас, просто запросив это (я попросил Claude сделать видеоигру с уникальной механикой по мотивам рассказа Германа Мелвилла «Bartleby the Scrivener» — и он сделал это по одному промпту), скормите ей документ и попросите инфографическое резюме, или попросите её прокомментировать загруженное вами изображение. Если это слишком игриво, следуйте совету из моей книги и просто используйте её для рабочих задач, учитывая упомянутую выше оговорку о приватности. Используйте её, чтобы провести мозговой штурм новых идей, спросите, как новостная статья или отчёт аналитика могут повлиять на ваш бизнес, или попросите создать финансовый дашборд для новой продуктовой или стартап-концепции. Вы, вероятно, найдёте случаи, которые вас поразят, и другие, где новые модели пока недостаточно хороши, чтобы быть полезными.
Ограничения этих моделей остаются вполне реальными, но факт того, что Gen3 ИИ лучше, чем Gen2, благодаря и первому, и второму закону масштабирования показывает нам нечто важное. Эти законы не являются фундаментальными константами Вселенной — это наблюдения за тем, что происходит, когда вы направляете огромные ресурсы на разработку ИИ. Вычислительная мощность продолжает расти, возможности продолжают улучшаться, и этот цикл ускоряется с каждым поколением. Пока они продолжают действовать, ИИ будет становиться всё лучше. Теперь мы знаем, что следующее поколение ИИ продолжит предлагать быстрые улучшения, что говорит о хороших шансах, что возможности ИИ могут продолжить расти в будущем.
