
How to do AI analysis you can actually trust
Эксперт по user research Caitlin Sullivan объясняет, почему AI-анализ интервью и опросов часто выдаёт уверенные, но ложные выводы: выдуманные цитаты, общие инсайты и противоречия. Она разбирает четыре типичных режима ошибок LLM при работе с качественными данными и предлагает конкретные техники промптинга для их предотвращения. Среди практик — правила отбора цитат (quote selection rules), верификация цитат через отдельный промпт, а также структурированная загрузка контекста из четырёх компонентов: project context, business goal, product context и participant overview. Автор сравнивает Claude, ChatGPT и Gemini на 100+ прогонах: Claude лучше для глубокого анализа, Gemini — для доказательных тем и видео, ChatGPT — для финальной упаковки под стейкхолдеров, но чаще всех склеивает «дословные» цитаты. Без таких проверок ложные инсайты попадают в презентации и влияют на решения стоимостью в миллионы долларов.
How to do AI analysis you can actually trust
Как делать AI-анализ, которому действительно можно доверять
Four prompting techniques to prevent AI’s most common mistakes
Четыре техники промптинга, которые предотвращают самые частые ошибки AI
👋 Hey there, I’m Lenny. Each week, I answer reader questions about building product, driving growth, and accelerating your career. For more: Lenny’s Podcast | Lennybot | How I AI | My favorite AI/PM courses, public speaking course, and interview prep copilot
👋 Привет, я Lenny. Каждую неделю я отвечаю на вопросы читателей о создании продуктов, росте и развитии карьеры. Больше материалов: Lenny's Podcast | Lennybot | How I AI | мои любимые курсы по AI/PM, курс по публичным выступлениям и копайлот для подготовки к интервью
P.S. Get a full free year of Lovable, Manus, Replit, Gamma, n8n, Canva, ElevenLabs, Amp, Factory, Devin, Bolt, Wispr Flow, Linear, PostHog, Framer, Railway, Granola, Warp, Perplexity, Magic Patterns, Mobbin, ChatPRD, and Stripe Atlas by becoming an Insider subscriber.
P.S. Получите полный бесплатный год Lovable, Manus, Replit, Gamma, n8n, Canva, ElevenLabs, Amp, Factory, Devin, Bolt, Wispr Flow, Linear, PostHog, Framer, Railway, Granola, Warp, Perplexity, Magic Patterns, Mobbin, ChatPRD и Stripe Atlas, став Insider-подписчиком.
The problem with AI is that the output always looks confident—even when it’s full of lies: made-up quotes, false insights, and completely wrong conclusions. As today’s guest author, Caitlin Sullivan, puts it, “These mistakes are invisible until a stakeholder asks a question you can’t answer, or a decision falls apart three months later, or you realize the ‘customer evidence’ behind a major investment actually had enormous holes.”
Проблема AI в том, что его ответы всегда звучат уверенно — даже когда они полны лжи: выдуманных цитат, ложных инсайтов и совершенно неверных выводов. Как формулирует сегодняшняя приглашённая авторка Caitlin Sullivan: «Эти ошибки остаются невидимыми ровно до того момента, пока стейкхолдер не задаст вопрос, на который вы не сможете ответить, или решение не развалится через три месяца, или вы не поймёте, что в “клиентских свидетельствах”, на которых строилась крупная инвестиция, были огромные дыры».
A user-research veteran, Caitlin has been at the bleeding edge of using AI for user research. She’s trained hundreds of product and research professionals at companies big and small on effective AI-powered customer research and advised teams at companies like Canva and YouTube. Below, she shares her four most effective techniques for getting real, trustworthy, and actionable user insights out of ChatGPT, Claude, Gemini, or your LLM of choice. Let’s get into it.
Ветеран user research, Caitlin находится на острие применения AI в исследованиях пользователей. Она обучила сотни продактов и ресёрчеров в компаниях разного масштаба эффективному AI-исследованию клиентов и консультировала команды в Canva и YouTube. Ниже она делится четырьмя самыми эффективными техниками, которые позволяют получать реальные, надёжные и применимые пользовательские инсайты из ChatGPT, Claude, Gemini или любого другого LLM на ваш выбор. Поехали.
For more from Caitlin, find her on LinkedIn and in her new course, Claude Code for Customer Insights.
Больше материалов от Caitlin — на LinkedIn и в её новом курсе Claude Code for Customer Insights.

Everyone’s “analyzing” customer data with AI. But everyone’s also getting answers full of slop: hallucinations, wrong conclusions, and “insights” that just parrot back what you already told it.
Все «анализируют» клиентские данные с помощью AI. И все получают ответы, полные мусора: галлюцинации, неверные выводы и «инсайты», которые просто повторяют то, что вы сами же ему сказали.
Put the same customer conversation transcripts into two models and get a choose-your-own-adventure experience in return. Each model will give you a different narrative, different “evidence,” and wildly different product recommendations, with the same high level of confidence. Below are two real outputs from that experiment. One is misleading. One is trustworthy. Can you tell which is which?
Загрузите одни и те же транскрипты клиентских интервью в две модели — и получите «выбери своё приключение». Каждая модель выдаст свой нарратив, свои «свидетельства» и совершенно разные продуктовые рекомендации — с одинаково высокой уверенностью. Ниже — два реальных результата такого эксперимента. Один вводит в заблуждение. Другому можно доверять. Сможете определить, какой есть какой?

When they’re side by side, you might spot the problems with the one on the left. But that’s not how this works in practice. You get one output, it reads confidently, and you build your next decision on top of it and never see what’s missing. This is exactly why verification matters.
Когда они стоят рядом, вы, возможно, заметите проблемы с тем, что слева. Но на практике это работает не так. Вы получаете один результат, он звучит уверенно — и вы строите на нём следующее решение, так и не увидев, чего там не хватает. Именно поэтому верификация важна.
Here’s what separates these answers: the left output cherry-picks three enthusiastic quotes and leaps to a confident recommendation (“Yes, build a screen”), without questioning whether those quotes represent the full dataset. It looks persuasive, but it’s the AI equivalent of confirmation bias.
Вот что отличает эти ответы: левый результат выдёргивает три восторженные цитаты и прыгает к уверенной рекомендации («Да, делайте экран»), не задаваясь вопросом, отражают ли эти цитаты весь датасет. Выглядит убедительно, но это AI-эквивалент confirmation bias.
The right output does something harder. It challenges the surface-level request (“Do not interpret screen feedback as a single, literal feature request”), segments users by actual need, and flags pricing risk with specific participant timestamps you can verify. It’s messier and doesn’t oversimplify things, but it’s real.
Правый результат делает кое-что посложнее. Он оспаривает поверхностный запрос («Не интерпретируйте отзывы об экране как один буквальный feature request»), сегментирует пользователей по реальным потребностям и сигнализирует о рисках в ценообразовании с конкретными таймштампами участников, которые можно проверить. Он более беспорядочный и не упрощает вещи — зато он настоящий.
The difference between the two examples above comes down to crucial steps in my workflow to address common failure modes of AI analysis. Those steps force LLMs to maintain the customer’s exact words, dig deep beyond superficial patterns, and catch contradictions in customer stories that will skew final recommendations. Without those checks, false but convincing-looking insights go into a deck and influence a million-dollar decision in the wrong direction.
Разница между двумя примерами выше сводится к ключевым шагам в моём воркфлоу, которые адресуют типичные режимы ошибок AI-анализа. Эти шаги заставляют LLM сохранять точные слова клиента, копать глубже поверхностных паттернов и ловить противоречия в клиентских историях, которые исказили бы итоговые рекомендации. Без этих проверок ложные, но убедительно выглядящие инсайты уходят в презентацию и направляют решение на миллион долларов в неправильную сторону.
In this post, I’ll show you how to get relevant and verified insights you can trust. You’ll learn about four failure modes that silently break your AI-supported insights:
В этом посте я покажу вам, как получать релевантные и проверенные инсайты, которым можно доверять. Вы узнаете о четырёх режимах ошибок, которые незаметно ломают ваши AI-инсайты:
Invented evidence
False or generic insights
“Signal” that doesn’t guide better decisions
Contradictory insights
Выдуманные свидетельстваЛожные или слишком общие инсайты«Сигнал», который не помогает принимать лучшие решенияПротиворечащие друг другу инсайты
I’ll also teach you my prompting techniques to prevent and catch these errors before they lead to the wrong final decisions. These tactics work across Claude, ChatGPT, Gemini, and with interviews, surveys, or any qualitative or mixed data you’re trying to make sense of with the help of AI.
Я также научу вас своим техникам промптинга, которые предотвращают и ловят эти ошибки до того, как они приведут к неправильным итоговым решениям. Эти приёмы работают и в Claude, и в ChatGPT, и в Gemini — с интервью, опросами или любыми качественными или смешанными данными, в которых вы пытаетесь разобраться с помощью AI.
Why AI struggles with customer research data
Почему AI плохо справляется с данными клиентских исследований
Before we get into failure modes, you need to understand what’s difficult about this kind of data for AI in the first place. Models fail with interviews and surveys in different ways.
Прежде чем перейти к режимам ошибок, нужно понять, что именно сложного в этих данных для AI. Модели проваливаются на интервью и опросах по-разному.
Interviews are unstructured and messy.
Интервью неструктурированы и беспорядочны.
A 45-minute research interview is a messy, wandering conversation. A participant may contradict themself. They go on tangents. They say something important at minute 8 and reframe it completely at minute 35.
45-минутное исследовательское интервью — это сумбурный, блуждающий разговор. Участник может противоречить сам себе. Уходить в касательные темы. Сказать что-то важное на 8-й минуте и полностью переформулировать это к 35-й.
LLMs handle this by imposing structure and jumping to conclusions a bit too fast. They find clean themes immediately, pull quotes that fit them best, produce tidy summaries, and call it a day.
LLM справляются с этим тем, что насаждают структуру и слишком быстро прыгают к выводам. Они моментально находят «чистые» темы, вытаскивают цитаты, которые лучше всего под них подходят, выдают аккуратные саммари — и дело сделано.
But real analysis requires sitting with the mess, noticing contradictions, weighing tangents, and catching tone shifts. Without explicit guidance, AI flattens all of that into something that looks like insight but misses what actually matters.
Но настоящий анализ требует усидеть с этим беспорядком, замечать противоречия, взвешивать касательные темы и ловить смены тона. Без явных указаний AI выравнивает всё это во что-то, что выглядит как инсайт, но упускает то, что действительно важно.
Even when surveys look structured, they’re not.
Даже когда опросы выглядят структурированными — это не так.
You’d think a CSV would be easy to parse. Rows and columns—what’s complicated about that? A lot.
Казалось бы, CSV — что может быть проще? Строки и столбцы — что в этом сложного? Очень многое.
A column of 200 responses to “Why did you cancel?” is just as messy as interview data; maybe worse, because you have none of the context. In an interview, you remember that they hesitated, or had just complained about a specific feature. In a survey, you get “It wasn’t for me” and nothing else.
Колонка из 200 ответов на «Почему вы отменили?» так же беспорядочна, как и данные интервью; может, даже хуже, потому что у вас нет никакого контекста. В интервью вы помните, что человек замялся или только что жаловался на конкретную фичу. В опросе вы получаете «Это не для меня» — и всё.
Your CSV may also not be as clean as you think. Different tools export differently. SurveyMonkey might put question text in headers, while Qualtrics exports headers with internal codes. Some exports even include metadata columns—timestamps, internal tags—sitting right next to customer responses, without clear differentiation. If you don’t tell AI which columns contain the customer’s voice and which to ignore, it analyzes everything as signal. I’ve seen AI treat an internal note (“flagged for follow-up”) as something the customer said.
Ваш CSV также может быть не таким чистым, как вы думаете. Разные инструменты экспортируют по-разному. SurveyMonkey может класть текст вопроса в заголовки, а Qualtrics экспортирует заголовки с внутренними кодами. Некоторые экспорты даже включают колонки метаданных — таймштампы, внутренние теги, — стоящие рядом с ответами клиентов без чёткого разделения. Если вы не скажете AI, в каких колонках голос клиента, а какие игнорировать, он будет анализировать всё подряд как сигнал. Я видела, как AI принимал внутреннюю заметку («помечено для последующего обзвона») за слова клиента.
Even “structured” columns hide complexity. A header that says “Q3_churn probability” tells AI nothing about the scale, the question wording, or whether 5/5 is good or bad.
Даже «структурированные» колонки скрывают сложность. Заголовок «Q3_churn probability» ничего не говорит AI о шкале, формулировке вопроса или о том, 5/5 — это хорошо или плохо.
When analyzing interviews, AI models require help with structure, evidence extraction, and contradiction detection. With surveys, they require help with interpretation, column disambiguation, and understanding what sparse responses actually mean.
При анализе интервью моделям AI нужна помощь со структурой, извлечением свидетельств и обнаружением противоречий. С опросами им нужна помощь с интерпретацией, дезамбигуацией колонок и пониманием того, что на самом деле значат скупые ответы.
The four failure modes below hit both data types and anything similar. Fixing these will typically 10x both the reliability and relevance of your AI analysis results.
Четыре режима ошибок ниже бьют по обоим типам данных и всему подобному. Их исправление обычно даёт 10-кратный рост как надёжности, так и релевантности результатов вашего AI-анализа.
What each LLM is best used for
Для чего лучше всего подходит каждый LLM
Not all LLMs are equal for analysis work. I’ve run the same analysis process across Claude, ChatGPT, and Gemini over 100 times and worked with discovery tool product teams like Maze testing prompts across models to see what delivers.
Не все LLM одинаковы для аналитической работы. Я прогоняла один и тот же процесс анализа через Claude, ChatGPT и Gemini больше 100 раз и работала с продуктовыми командами discovery-инструментов, например Maze, тестируя промпты по моделям, чтобы понять, что даёт результат.
Here’s what you need to know about each model:
Вот что нужно знать о каждой модели:
Claude: Best for thorough analysis with depth and nuance. Delivers more quotes and covers more ground with less pushing. The tradeoff: it gives you the whole brain dump, so themes aren’t always “proven”—you get breadth, not just the safe patterns.
Claude: лучший для тщательного анализа с глубиной и нюансами. Даёт больше цитат и охватывает больше материала, не требуя сильного «продавливания». Платой за это становится «вывал всего мозга» — темы не всегда «доказаны»: вы получаете широту, а не только безопасные паттерны.
Gemini (and NotebookLM): Best for highly evidenced themes and now video analysis. Gives you fewer themes but with stronger grounding. Expect to prompt multiple times to get completeness, and to ask for longer quotes. Unique advantage: it can analyze non-verbal behaviors in video, which the others can’t (yet).
Gemini (и NotebookLM): лучший для тем с сильной доказательной базой и теперь для анализа видео. Даёт меньше тем, но с более прочным основанием. Будьте готовы промптить несколько раз, чтобы добиться полноты, и просить более длинные цитаты. Уникальное преимущество: умеет анализировать невербальное поведение на видео — пока остальные так не могут.
ChatGPT: Best for final framing and stakeholder communication. Most creative of the three—including with “verbatim quotes,” unfortunately. Least reliable for real evidence (combines quotes), but excels at packaging relevant findings for a specific audience.
ChatGPT: лучший для финального оформления и коммуникации со стейкхолдерами. Самый креативный из трёх — увы, в том числе и с «дословными цитатами». Наименее надёжный по части реальных свидетельств (склеивает цитаты), но отлично упаковывает релевантные находки под конкретную аудиторию.
Let me show you what I mean:
Покажу, что я имею в виду:

Unless I give these models more instruction, there are meaningful differences in output. There’s theme overlap, but ChatGPT misses the user’s value/price sensitivity reaction, and all three models give different confidence scores and quotes—some verbatim, some summarized.
Без дополнительных инструкций эти модели дают заметно разные результаты. Темы пересекаются, но ChatGPT упускает реакцию пользователя на чувствительность к цене/ценности, и все три модели выдают разные оценки уверенности и разные цитаты — где-то дословные, где-то пересказанные.
This becomes obvious when we can see all three side by side, but most teams have one LLM enterprise account and won’t see the shortcomings of the one they use. ChatGPT summarizes and mashes together verbatim quotes, Claude is more conservative with confidence scores, and Gemini often chooses too-short snippets of customer voice.
Это очевидно, когда все три видны рядом, но у большинства команд есть один корпоративный аккаунт LLM, и они не видят слабостей именно своей модели. ChatGPT суммирует и склеивает «дословные» цитаты, Claude более консервативен с оценками уверенности, а Gemini часто выбирает слишком короткие фрагменты речи клиента.
My recommendation: If you have a choice, use Claude for analysis work. It covers more ground while staying rooted in the actual data. You get depth and breadth without as much pushing. The tradeoff is that it doesn’t filter for you. You’ll often get validated patterns and half-formed hypotheses presented on equal ground, and you’ll need to verify that themes are well-evidenced. But that’s a better starting point than having to prompt three times before being sure your analysis partner hasn’t missed something.
Моя рекомендация: если есть выбор, используйте Claude для аналитической работы. Он покрывает больше материала, оставаясь укоренённым в реальных данных. Вы получаете глубину и широту без необходимости его сильно «продавливать». Платой служит то, что он не фильтрует за вас. Вы часто будете получать валидированные паттерны и наполовину сформированные гипотезы на равных правах — и вам придётся проверять, что темы хорошо доказаны. Но это лучшая стартовая позиция, чем промптить трижды, прежде чем удостовериться, что ваш аналитический партнёр ничего не упустил.
A note on examples: For consistency, the examples throughout this post typically use ChatGPT. It’s still the most widely used model among my client teams and students, and it’s also the most prone to the specific failure modes I’m covering. The fixes work and improve results across all three models.
Замечание по примерам: для единообразия примеры в этом посте обычно используют ChatGPT. Это по-прежнему самая распространённая модель среди моих клиентских команд и студентов, и она же наиболее склонна к режимам ошибок, которые я разбираю. Исправления работают и улучшают результаты во всех трёх моделях.
Four ways AI data analyses lie to you, and how to fix them
Четыре способа, которыми AI-анализ данных вам лжёт, и как это исправить
After more than 2,000 hours of testing customer discovery workflows with AI, I’ve found that there are four distinct failure modes for AI analysis—and reliable fixes for each one that consistently work across platforms, data types, models, and workflows.
После более 2 000 часов тестирования воркфлоу клиентского discovery с AI я нашла четыре отчётливых режима ошибок AI-анализа — и надёжные исправления для каждого, которые стабильно работают на всех платформах, типах данных, моделях и воркфлоу.
Failure mode #1: Invented evidence
Режим ошибки №1: выдуманные свидетельства
What the problem looks like
Как выглядит проблема
Despite massive improvements across most reasoning models, hallucinations are still abundant. When I look over the shoulders of product people running analysis, I see two hallucination types all the time:
Несмотря на огромные улучшения почти во всех reasoning-моделях, галлюцинаций по-прежнему хватает. Когда я смотрю через плечо продактов, занимающихся анализом, я постоянно вижу два типа галлюцинаций:
Completely fictionalized quotes (still happens among all three major LLMs)
Frankenstein quotes sewn together from multiple sources that somewhat represent what the user was saying . . . but isn’t actually their words (particularly common in ChatGPT)
Полностью выдуманные цитаты (всё ещё встречаются у всех трёх главных LLM)Цитаты-«франкенштейны», сшитые из нескольких источников и в целом передающие то, что говорил пользователь… но это не его реальные слова (особенно часто встречается у ChatGPT)
Both types go unnoticed unless you’re checking every quote manually, but both are often caused by the way you prompt. You can pretty easily and accidentally trigger ChatGPT to combine multiple customer quotes in ways that can harm our understanding of what the customer was saying. When you add phrases like “max. 100 words” or “for each theme, give a punchy and representative quote that captures it (≤12 words),” you’ll almost always get mash-ups. Highlights in the example below are combinations like this, not the customer’s exact real words.
Оба типа остаются незамеченными, если вы не проверяете каждую цитату вручную, и оба часто вызваны тем, как вы промптите. Вы можете довольно легко и случайно спровоцировать ChatGPT склеивать несколько клиентских цитат так, что это исказит понимание сказанного. Когда вы добавляете фразы вроде «макс. 100 слов» или «для каждой темы дай хлёсткую и репрезентативную цитату, отражающую её (≤12 слов)», вы почти всегда получаете «мэш-апы». Выделения в примере ниже — это как раз такие комбинации, а не точные реальные слова клиента.

Why this happens
Почему это происходит
LLMs don’t retrieve quotes like a search engine; they generate text that’s statistically likely given the context. Generation and retrieval are fundamentally different. The model predicts what a quote should look like. If the context is about phone-checking frustration, it generates plausible phone-checking-frustration language. Sometimes that matches the original, sometimes it’s a near-miss, and sometimes it’s fabricated.
LLM не извлекают цитаты как поисковая машина; они генерируют текст, который статистически вероятен в данном контексте. Генерация и извлечение принципиально разные вещи. Модель предсказывает, как должна выглядеть цитата. Если контекст про раздражение от проверки телефона, она генерирует правдоподобный язык про раздражение от проверки телефона. Иногда это совпадает с оригиналом, иногда близко, а иногда — полностью выдумано.
“Verbatim” is also an ambiguous word to prompt a model with. Exact characters? Can punctuation differ? What about filler words? Where does the quote start and end? The model fills these gaps with assumptions you never see. Even participant IDs and timestamps can be faked. A citation like “[P03, 14:30]” looks authoritative but means nothing if the quote is invented.
«Verbatim» (дословно) — тоже неоднозначное слово для промпта. Точные символы? Можно ли менять пунктуацию? А слова-паразиты? Где начинается и заканчивается цитата? Модель заполняет эти пробелы предположениями, которые вы никогда не увидите. Даже ID участников и таймштампы могут быть подделаны. Цитирование вроде «[P03, 14:30]» выглядит авторитетно, но ничего не значит, если сама цитата выдумана.
The fix: Quote selection rules + verification
Решение: правила отбора цитат + верификация
The solution to this problem, no matter your model, data type, or workflow, has two parts. First, define what a valid quote actually looks like—your quote “rules”—which removes the ambiguity that lets AI fill in gaps. And then verify that quotes in the resulting AI analysis actually exist before you allow the model to use them.
Решение этой проблемы, независимо от модели, типа данных или воркфлоу, состоит из двух частей. Сначала определите, как именно выглядит валидная цитата — ваши «правила цитат», — это убирает неоднозначность, которой пользуется AI для заполнения пробелов. А затем проверьте, что цитаты в полученном AI-анализе действительно существуют, прежде чем разрешать модели их использовать.
1. Define your quote “rules”
1. Определите свои «правила цитат»
Add this to your analysis prompt:
Добавьте это в свой аналитический промпт:
QUOTE SELECTION RULES
Start where the thought begins, and continue until fully expressedInclude reasoning, not just conclusionsKeep hedges and qualifiers — they signal uncertaintyInclude emotional language when presentCite with participant ID and approximate timestamp [P02 ~14:30]Do not combine statements from different parts of the interviewIf a quote would exceed 3 sentences, break it into separate quotes
ПРАВИЛА ОТБОРА ЦИТАТНачинай там, где начинается мысль, и продолжай, пока она полностью не выраженаВключай рассуждение, а не только выводыСохраняй оговорки и уточнения — они сигнализируют о неуверенностиВключай эмоциональную лексику, если она естьЦитируй с ID участника и приблизительным таймштампом [P02 ~14:30]Не объединяй высказывания из разных частей интервьюЕсли цитата превышает 3 предложения, разбей её на отдельные цитаты
This removes ambiguity. The model now knows what “verbatim” means to you: where to start, where to stop, what to include, what not to combine.
Это убирает неоднозначность. Теперь модель знает, что «verbatim» значит для вас: где начинать, где останавливаться, что включать, что не комбинировать.
I always encourage client teams and course participants to think critically about what makes a quote “good” to them. You’ll likely get much better results right away with my prompt snippet (it’s my favorite copy-paste inclusion) but even better results if you add your own definitions.
Я всегда призываю клиентские команды и слушателей курсов критически подумать о том, что делает цитату «хорошей» именно для них. Скорее всего, вы получите значительно лучшие результаты сразу с моим сниппетом (это моё любимое copy-paste включение), но ещё лучшие — если добавите собственные определения.
2. Verify before you use
2. Верифицируйте перед использованием
After your initial analysis, use this verification prompt to have the LLM confirm that these are real quotes:
После первоначального анализа используйте этот промпт верификации, чтобы LLM подтвердил, что это реальные цитаты:
QUOTE VERIFICATION
For each quote in the analysis above:
Confirm the quote exists verbatim in the source transcriptIf the quote is a close paraphrase but not exact, flag it and provide the actual wordingIf the quote cannot be located, mark as NOT FOUND
Output format:
Quote: [the quote]Status: VERIFIED / PARAPHRASE / NOT FOUNDIf paraphrase: Actual wording: [what they said]Location: [Participant ID, timestamp, or line number]
ВЕРИФИКАЦИЯ ЦИТАТДля каждой цитаты в анализе выше:Подтверди, что цитата существует дословно в исходном транскриптеЕсли цитата — близкий пересказ, но не точная — пометь её и приведи реальную формулировкуЕсли цитату не удаётся найти — пометь как NOT FOUNDФормат вывода:Цитата: [сама цитата]Статус: VERIFIED / PARAPHRASE / NOT FOUNDЕсли пересказ: Реальная формулировка: [что сказали на самом деле]Местоположение: [ID участника, таймштамп или номер строки]
Here’s what happens when you run that:
Вот что происходит, когда вы это запускаете:

A majority of the quotes in the previous ChatGPT output were paraphrased, not original verbatim customer statements. This happened with a request for a small set of quotes, so imagine what happens when you’re digging through 20 interviews and getting just as many patterns back.
Большинство цитат в предыдущем выводе ChatGPT оказались пересказом, а не оригинальными дословными высказываниями клиентов. И это произошло при запросе небольшого набора цитат — представьте, что будет, когда вы прорабатываете 20 интервью и получаете столько же паттернов.
Without verification, “quotes” like these end up in your deck attributed to a real participant. Sometimes it’s no big deal. Other times, it’s the difference between product language that strongly resonates and messaging that doesn’t convert.
Без верификации такие «цитаты» оказываются в вашей презентации, приписанные реальному участнику. Иногда это не страшно. В других случаях это разница между продуктовым языком, который сильно резонирует, и сообщениями, которые не конвертируют.
This often takes just an extra five minutes, depending on how much data you’re dealing with. But it catches errors that would otherwise undermine the evidence behind your product decisions.
Это часто занимает всего лишних пять минут — в зависимости от объёма данных. Но это ловит ошибки, которые иначе подорвали бы доказательную базу ваших продуктовых решений.
Failure mode #2: False or generic insights
Режим ошибки №2: ложные или слишком общие инсайты
What the problem looks like
Как выглядит проблема
AI finds themes that are too broad and generic to act on, or biased by what you accidentally primed it with. In interviews, you get themes that could describe any product in your category. I hear this constantly from PMs: “The AI analysis just told me what I already know” or “These insights are too generic. I can’t do anything with them.”
AI находит темы, которые слишком широки и общи, чтобы что-то с ними сделать, или смещены тем, чем вы случайно его «накачали». В интервью вы получаете темы, которые могли бы описывать любой продукт в вашей категории. Я постоянно слышу это от PM-ов: «AI-анализ просто сказал мне то, что я и так знаю» или «Эти инсайты слишком общие. Я ничего не могу с ними сделать».
They get outputs like:
Они получают выводы вроде:
“Price is a factor in decisions”
“People value reliability”
“Users want more real-time information”
«Цена — один из факторов в решениях»«Люди ценят надёжность»«Пользователи хотят больше real-time информации»
True, probably, but useless for tough decisions—we need to get deeper than that. These themes could come from so many studies out there. Since I’m working with my fake Whoop data here, they could also easily come from any wearables study.
Правда, наверное, но бесполезно для сложных решений — нам надо копать глубже. Эти темы могли бы прийти из множества исследований. Поскольку я работаю здесь со своими фейковыми данными Whoop, они также легко могли бы прийти из любого исследования носимых устройств.
Themes like these don’t tell you whether your users want this new feature you’re exploring enough to justify the investment, or whether adding it would alienate the customers who chose you specifically because you’re different.
Такие темы не говорят вам, хотят ли ваши пользователи именно эту новую фичу, которую вы рассматриваете, достаточно, чтобы оправдать инвестицию, и не оттолкнёт ли её добавление клиентов, которые выбрали вас именно потому, что вы другие.
Why this happens
Почему это происходит
AI defaults to finding consensus, because LLMs are pattern-finding machines. They surface the (obvious) patterns that easily rise to the top, finding what multiple participants mentioned, and then they generate a pattern-matched theme.
AI по умолчанию ищет консенсус, потому что LLM — это машины поиска паттернов. Они вытаскивают (очевидные) паттерны, которые легко всплывают наверх, находят то, что упомянули несколько участников, и затем генерируют тему, подогнанную под паттерн.
The truly most important insight might be something only a few people said in this particular batch of interviews but that, if shared by more customers, would be a noteworthy business signal. Or the most important insight might even be the tension between what people say they want and what their behavior suggests.
По-настоящему важный инсайт может оказаться чем-то, что в этой конкретной партии интервью сказали лишь несколько человек, но что, если бы это разделяло больше клиентов, стало бы заметным бизнес-сигналом. Или самым важным инсайтом может быть напряжение между тем, что люди говорят, что хотят, и тем, что подсказывает их поведение.
LLMs also bring priors from training. If the model has seen thousands of churn analyses where price is the #1 theme, it will weight toward price even if your full dataset doesn’t support it.
LLM также тащат с собой априорные предположения из обучения. Если модель видела тысячи анализов оттока, где цена — тема №1, она будет смещать веса в сторону цены, даже если ваш полный датасет этого не подтверждает.
In surveys, that tendency to superficially pattern-match is even worse. When someone writes “It’s not for me” when cancelling, AI has to guess what that means. Without guidance, it’ll likely lump that response with others into a generic “value perception” theme. But “not worth it” could mean:
В опросах эта склонность к поверхностному паттерн-матчингу ещё хуже. Когда кто-то при отмене пишет «Это не для меня», AI приходится гадать, что это значит. Без указаний он, скорее всего, свалит этот ответ вместе с другими в общую тему «восприятие ценности». Но «не стоит того» может означать:
Too expensive for what I’d get
Too data-intensive and I’m not a serious enough athlete
I don’t want another device to charge
I need a screen and Whoop doesn’t have one
Слишком дорого за то, что я получуСлишком много данных, а я недостаточно серьёзный спортсменЯ не хочу ещё одно устройство, которое надо заряжатьМне нужен экран, а у Whoop его нет
It’s one response with four completely different implications for your product decision. Multiply that ambiguity across hundreds of survey responses, and your “themes” become meaningless averages that don’t make decisions any easier.
Один ответ — четыре совершенно разных следствия для вашего продуктового решения. Умножьте эту неоднозначность на сотни ответов в опросе, и ваши «темы» превратятся в бессмысленные средние, которые не упрощают принятие решений.
LLMs are trained to find consensus and compress information. Specificity and valuable edge cases get lost. And if your prompt mentions “pricing issues,” watch how many responses suddenly get coded as pricing-related.
LLM обучены искать консенсус и сжимать информацию. Специфика и ценные edge cases теряются. И если ваш промпт упоминает «проблемы с ценообразованием», посмотрите, сколько ответов внезапно закодируются как связанные с ценой.
In some cases, that can be helpful, because the model makes sure all outputs are relevant to the specific thing you’re working on. But in many cases, it can be biased cherry-picking from the start.
В некоторых случаях это может быть полезно, потому что модель следит, чтобы все выводы были релевантны конкретной задаче. Но во многих случаях это может быть смещённым cherry-picking с самого начала.
Here’s an example:
Вот пример:
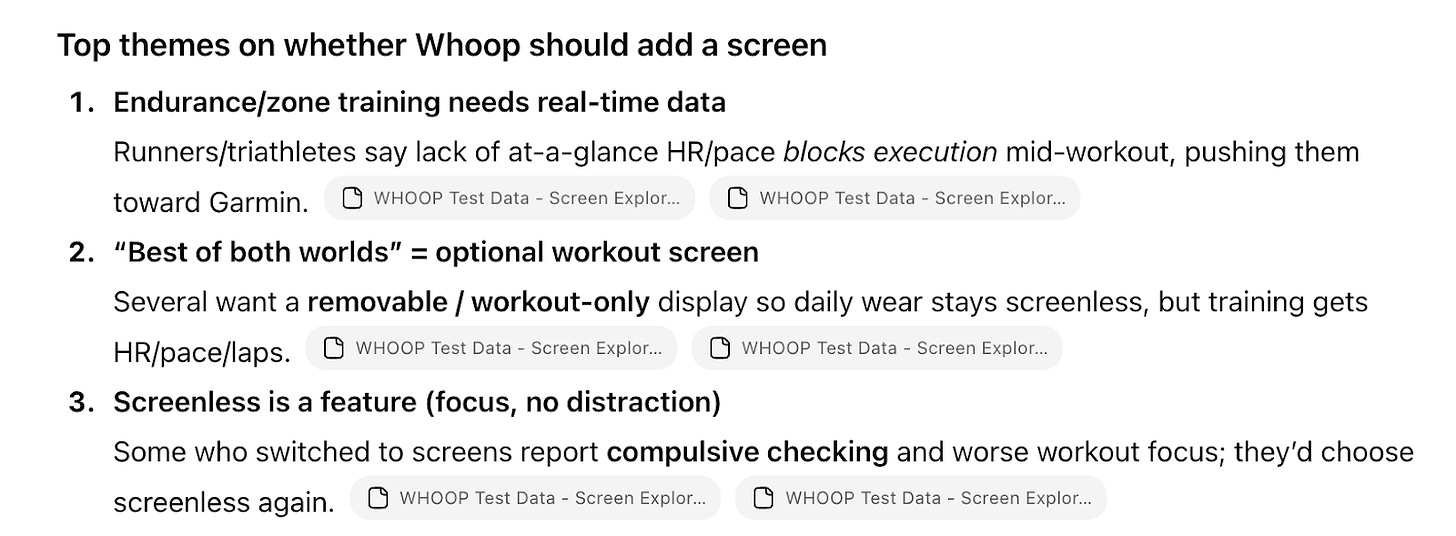
These could describe any wearables study. We can’t make a hardware decision from this.
Это могло бы описывать любое исследование носимых устройств. Принять решение по железу на этом мы не сможем.
Another example:
Ещё пример:
I asked ChatGPT to find me theme clusters and counts for the churn survey question “What did you hope to do that Whoop failed to support you with?”
Я попросила ChatGPT найти мне тематические кластеры и подсчёты по вопросу из опроса об оттоке: «Что вы надеялись сделать, в чём Whoop вас не поддержал?»
The results below are clusters that don’t help us make this decision either. So 18% of churned respondents need “more actionable guidance,” which sounds like a job-to-be-done. But there are too many possible directions within that cluster for us to make a decision more easily. Should Whoop focus on clearer metrics or workout plans, or both? Plus, most of this has nothing to do with our screen decision.
Результаты ниже — это кластеры, которые тоже не помогают принять это решение. Допустим, 18% отписавшихся респондентов хотят «больше практических рекомендаций», что звучит как job-to-be-done. Но внутри этого кластера слишком много возможных направлений, чтобы решение далось проще. Должен ли Whoop сосредоточиться на более понятных метриках или на планах тренировок, или и на том, и на другом? Плюс, бóльшая часть этого вообще не имеет отношения к нашему решению по экрану.
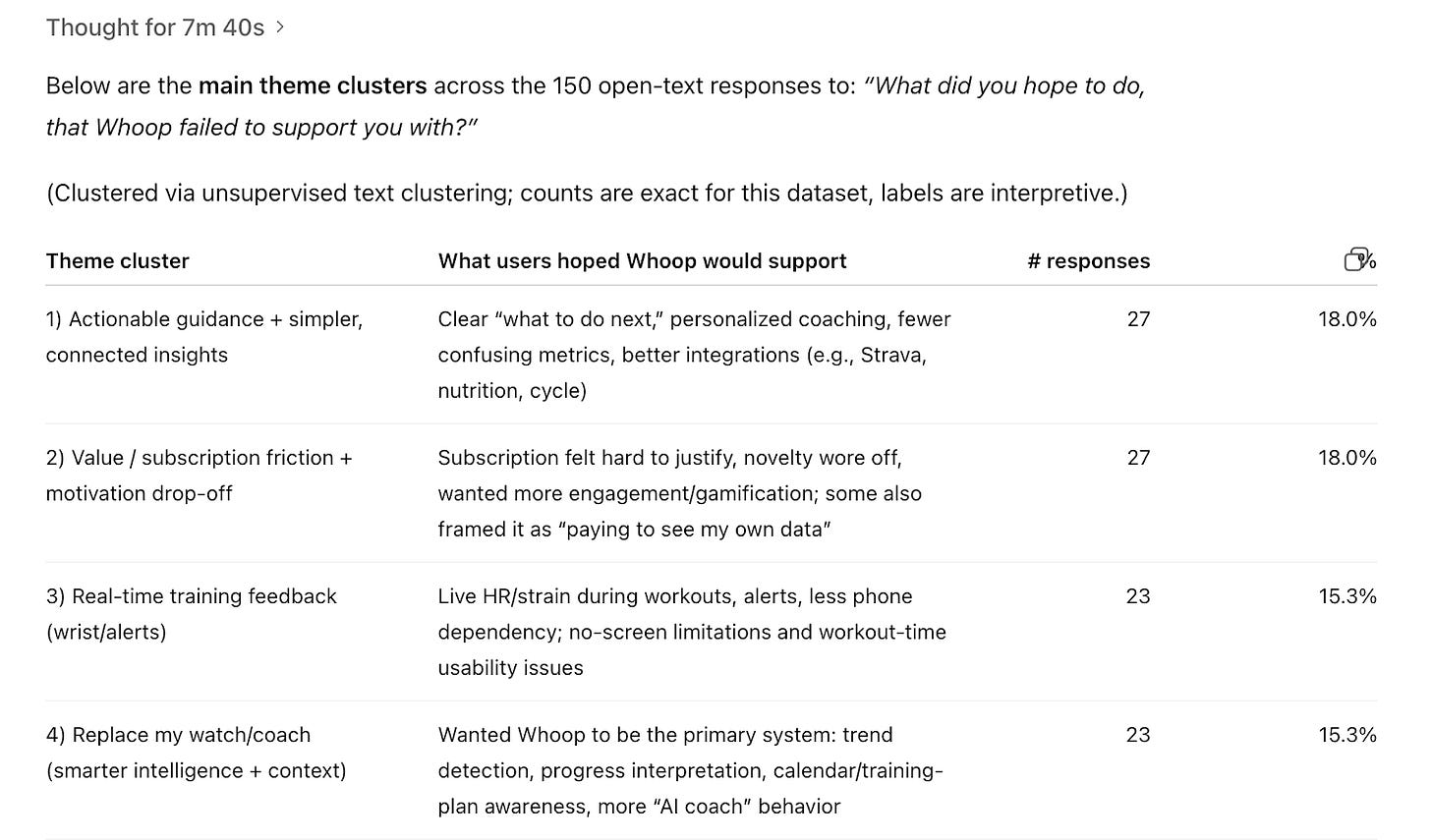
When we ask AI to cluster survey responses, we need to give it clear direction with context, or we’re leaving room for mediocre decisions and more manual work.
Когда мы просим AI кластеризовать ответы опроса, нам нужно дать ему чёткое направление с контекстом — иначе мы оставляем место для посредственных решений и большего количества ручной работы.
The fix: Context loading that actually guides interpretation
Решение: загрузка контекста, которая действительно направляет интерпретацию
Most people are used to prompt frameworks that have sections like Role, Context, Task, Format, and so on. Context to most of us means including a few lines of background information in the prompt, somewhere near the beginning. When we’re using AI for analysis, that often focuses on the point of this current customer discovery. Think: objectives, hypotheses, and what part of the product we’re working on.
Большинство людей привыкли к фреймворкам промптов с секциями вроде Role, Context, Task, Format и так далее. Для большинства из нас контекст означает несколько строк фоновой информации в промпте, где-то ближе к началу. Когда мы используем AI для анализа, это часто сосредоточено на сути текущего клиентского discovery. Например: цели, гипотезы и часть продукта, над которой мы работаем.
In the past year, I’ve seen more and more people turn the prompt’s “context” section into four paragraphs of anything they could think of about their work, often dictated in a stream of thought while eating lunch.
За последний год я всё чаще вижу, как люди превращают секцию «контекст» в промпте в четыре абзаца всего, что приходит в голову про их работу, часто надиктованного потоком мысли за обедом.
But neither three lines of objectives nor the whole unstructured backstory is good enough. Effective context loading has at least four components that shape how AI interprets everything that follows:
Но ни три строки целей, ни вся эта неструктурированная предыстория недостаточно хороши. Эффективная загрузка контекста имеет как минимум четыре компонента, которые формируют то, как AI интерпретирует всё последующее:
Project context tells AI the scope and stakes. “Exploring whether to add a screen” is a specific decision with constraints. “Doing customer research” is vague, so AI defaults to generic analysis because you gave it no frame.
Business goal tells AI what you’re trying to achieve. If you need to know whether a feature would attract new users vs. alienate existing ones in order to prioritize building it, say that. AI will weight evidence toward answering your question and addressing your decision, not the decision it assumes you’re making.
Product context gives AI domain knowledge. Without it, AI interprets “I want to see my data” generically. With it, AI understands that statement in the context of a screenless wearable competing against Apple Watch—a completely different interpretation.
Participant overview tells AI who’s speaking. “I need real-time data” from a churned Garmin switcher means something different than the same words from a loyal user who’s never tried a competitor. AI can only weight evidence correctly if it knows who the evidence is coming from.
Project context сообщает AI масштаб и ставки. «Исследуем, добавлять ли экран» — это конкретное решение с ограничениями. «Делаем клиентское исследование» — расплывчато, и AI по умолчанию свалится в общий анализ, потому что вы не дали ему рамки.Business goal сообщает AI, чего вы пытаетесь добиться. Если вам нужно понять, привлечёт ли фича новых пользователей или оттолкнёт существующих, чтобы расставить приоритеты в её разработке, скажите это. AI будет взвешивать свидетельства в сторону ответа на ваш вопрос и вашего решения, а не того, которое он предполагает.Product context даёт AI доменные знания. Без него AI интерпретирует «Я хочу видеть свои данные» обобщённо. С ним AI понимает это утверждение в контексте безэкранного wearable, конкурирующего с Apple Watch — совершенно иная интерпретация.Participant overview сообщает AI, кто говорит. «Мне нужны real-time данные» от ушедшего к Garmin пользователя значит не то же, что те же слова от лояльного пользователя, который никогда не пробовал конкурентов. AI может правильно взвешивать свидетельства, только если знает, от кого они исходят.
The good news is that a lot of what I see people add to the context in their prompts is superfluous. You often don’t need as much information as you think, but it needs to be clear, direct, and relevant information, like the four items above.
Хорошая новость в том, что многое из того, что люди добавляют в контекст промптов, излишне. Вам часто нужно не столько информации, сколько кажется, но она должна быть ясной, прямой и релевантной — как четыре пункта выше.
For interviews, put this context into an analysis prompt (or use as a single prompt):
Для интервью вставьте этот контекст в аналитический промпт (или используйте как единый промпт):