
How to do AI analysis you can actually trust
Эксперт по user research Caitlin Sullivan объясняет, почему AI-анализ интервью и опросов часто выдаёт уверенные, но ложные выводы: выдуманные цитаты, общие инсайты и противоречия. Она разбирает четыре типичных режима ошибок LLM при работе с качественными данными и предлагает конкретные техники промптинга для их предотвращения. Среди практик — правила отбора цитат (quote selection rules), верификация цитат через отдельный промпт, а также структурированная загрузка контекста из четырёх компонентов: project context, business goal, product context и participant overview. Автор сравнивает Claude, ChatGPT и Gemini на 100+ прогонах: Claude лучше для глубокого анализа, Gemini — для доказательных тем и видео, ChatGPT — для финальной упаковки под стейкхолдеров, но чаще всех склеивает «дословные» цитаты. Без таких проверок ложные инсайты попадают в презентации и влияют на решения стоимостью в миллионы долларов.
Как делать AI-анализ, которому действительно можно доверять
Четыре техники промптинга, которые предотвращают самые частые ошибки AI
👋 Привет, я Lenny. Каждую неделю я отвечаю на вопросы читателей о создании продуктов, росте и развитии карьеры. Больше материалов: Lenny's Podcast | Lennybot | How I AI | мои любимые курсы по AI/PM, курс по публичным выступлениям и копайлот для подготовки к интервью
P.S. Получите полный бесплатный год Lovable, Manus, Replit, Gamma, n8n, Canva, ElevenLabs, Amp, Factory, Devin, Bolt, Wispr Flow, Linear, PostHog, Framer, Railway, Granola, Warp, Perplexity, Magic Patterns, Mobbin, ChatPRD и Stripe Atlas, став Insider-подписчиком.
Проблема AI в том, что его ответы всегда звучат уверенно — даже когда они полны лжи: выдуманных цитат, ложных инсайтов и совершенно неверных выводов. Как формулирует сегодняшняя приглашённая авторка Caitlin Sullivan: «Эти ошибки остаются невидимыми ровно до того момента, пока стейкхолдер не задаст вопрос, на который вы не сможете ответить, или решение не развалится через три месяца, или вы не поймёте, что в “клиентских свидетельствах”, на которых строилась крупная инвестиция, были огромные дыры».
Ветеран user research, Caitlin находится на острие применения AI в исследованиях пользователей. Она обучила сотни продактов и ресёрчеров в компаниях разного масштаба эффективному AI-исследованию клиентов и консультировала команды в Canva и YouTube. Ниже она делится четырьмя самыми эффективными техниками, которые позволяют получать реальные, надёжные и применимые пользовательские инсайты из ChatGPT, Claude, Gemini или любого другого LLM на ваш выбор. Поехали.
Больше материалов от Caitlin — на LinkedIn и в её новом курсе Claude Code for Customer Insights.

Все «анализируют» клиентские данные с помощью AI. И все получают ответы, полные мусора: галлюцинации, неверные выводы и «инсайты», которые просто повторяют то, что вы сами же ему сказали.
Загрузите одни и те же транскрипты клиентских интервью в две модели — и получите «выбери своё приключение». Каждая модель выдаст свой нарратив, свои «свидетельства» и совершенно разные продуктовые рекомендации — с одинаково высокой уверенностью. Ниже — два реальных результата такого эксперимента. Один вводит в заблуждение. Другому можно доверять. Сможете определить, какой есть какой?

Когда они стоят рядом, вы, возможно, заметите проблемы с тем, что слева. Но на практике это работает не так. Вы получаете один результат, он звучит уверенно — и вы строите на нём следующее решение, так и не увидев, чего там не хватает. Именно поэтому верификация важна.
Вот что отличает эти ответы: левый результат выдёргивает три восторженные цитаты и прыгает к уверенной рекомендации («Да, делайте экран»), не задаваясь вопросом, отражают ли эти цитаты весь датасет. Выглядит убедительно, но это AI-эквивалент confirmation bias.
Правый результат делает кое-что посложнее. Он оспаривает поверхностный запрос («Не интерпретируйте отзывы об экране как один буквальный feature request»), сегментирует пользователей по реальным потребностям и сигнализирует о рисках в ценообразовании с конкретными таймштампами участников, которые можно проверить. Он более беспорядочный и не упрощает вещи — зато он настоящий.
Разница между двумя примерами выше сводится к ключевым шагам в моём воркфлоу, которые адресуют типичные режимы ошибок AI-анализа. Эти шаги заставляют LLM сохранять точные слова клиента, копать глубже поверхностных паттернов и ловить противоречия в клиентских историях, которые исказили бы итоговые рекомендации. Без этих проверок ложные, но убедительно выглядящие инсайты уходят в презентацию и направляют решение на миллион долларов в неправильную сторону.
В этом посте я покажу вам, как получать релевантные и проверенные инсайты, которым можно доверять. Вы узнаете о четырёх режимах ошибок, которые незаметно ломают ваши AI-инсайты:
Выдуманные свидетельстваЛожные или слишком общие инсайты«Сигнал», который не помогает принимать лучшие решенияПротиворечащие друг другу инсайты
Я также научу вас своим техникам промптинга, которые предотвращают и ловят эти ошибки до того, как они приведут к неправильным итоговым решениям. Эти приёмы работают и в Claude, и в ChatGPT, и в Gemini — с интервью, опросами или любыми качественными или смешанными данными, в которых вы пытаетесь разобраться с помощью AI.
Почему AI плохо справляется с данными клиентских исследований
Прежде чем перейти к режимам ошибок, нужно понять, что именно сложного в этих данных для AI. Модели проваливаются на интервью и опросах по-разному.
Интервью неструктурированы и беспорядочны.
45-минутное исследовательское интервью — это сумбурный, блуждающий разговор. Участник может противоречить сам себе. Уходить в касательные темы. Сказать что-то важное на 8-й минуте и полностью переформулировать это к 35-й.
LLM справляются с этим тем, что насаждают структуру и слишком быстро прыгают к выводам. Они моментально находят «чистые» темы, вытаскивают цитаты, которые лучше всего под них подходят, выдают аккуратные саммари — и дело сделано.
Но настоящий анализ требует усидеть с этим беспорядком, замечать противоречия, взвешивать касательные темы и ловить смены тона. Без явных указаний AI выравнивает всё это во что-то, что выглядит как инсайт, но упускает то, что действительно важно.
Даже когда опросы выглядят структурированными — это не так.
Казалось бы, CSV — что может быть проще? Строки и столбцы — что в этом сложного? Очень многое.
Колонка из 200 ответов на «Почему вы отменили?» так же беспорядочна, как и данные интервью; может, даже хуже, потому что у вас нет никакого контекста. В интервью вы помните, что человек замялся или только что жаловался на конкретную фичу. В опросе вы получаете «Это не для меня» — и всё.
Ваш CSV также может быть не таким чистым, как вы думаете. Разные инструменты экспортируют по-разному. SurveyMonkey может класть текст вопроса в заголовки, а Qualtrics экспортирует заголовки с внутренними кодами. Некоторые экспорты даже включают колонки метаданных — таймштампы, внутренние теги, — стоящие рядом с ответами клиентов без чёткого разделения. Если вы не скажете AI, в каких колонках голос клиента, а какие игнорировать, он будет анализировать всё подряд как сигнал. Я видела, как AI принимал внутреннюю заметку («помечено для последующего обзвона») за слова клиента.
Даже «структурированные» колонки скрывают сложность. Заголовок «Q3_churn probability» ничего не говорит AI о шкале, формулировке вопроса или о том, 5/5 — это хорошо или плохо.
При анализе интервью моделям AI нужна помощь со структурой, извлечением свидетельств и обнаружением противоречий. С опросами им нужна помощь с интерпретацией, дезамбигуацией колонок и пониманием того, что на самом деле значат скупые ответы.
Четыре режима ошибок ниже бьют по обоим типам данных и всему подобному. Их исправление обычно даёт 10-кратный рост как надёжности, так и релевантности результатов вашего AI-анализа.
Для чего лучше всего подходит каждый LLM
Не все LLM одинаковы для аналитической работы. Я прогоняла один и тот же процесс анализа через Claude, ChatGPT и Gemini больше 100 раз и работала с продуктовыми командами discovery-инструментов, например Maze, тестируя промпты по моделям, чтобы понять, что даёт результат.
Вот что нужно знать о каждой модели:
Claude: лучший для тщательного анализа с глубиной и нюансами. Даёт больше цитат и охватывает больше материала, не требуя сильного «продавливания». Платой за это становится «вывал всего мозга» — темы не всегда «доказаны»: вы получаете широту, а не только безопасные паттерны.
Gemini (и NotebookLM): лучший для тем с сильной доказательной базой и теперь для анализа видео. Даёт меньше тем, но с более прочным основанием. Будьте готовы промптить несколько раз, чтобы добиться полноты, и просить более длинные цитаты. Уникальное преимущество: умеет анализировать невербальное поведение на видео — пока остальные так не могут.
ChatGPT: лучший для финального оформления и коммуникации со стейкхолдерами. Самый креативный из трёх — увы, в том числе и с «дословными цитатами». Наименее надёжный по части реальных свидетельств (склеивает цитаты), но отлично упаковывает релевантные находки под конкретную аудиторию.
Покажу, что я имею в виду:

Без дополнительных инструкций эти модели дают заметно разные результаты. Темы пересекаются, но ChatGPT упускает реакцию пользователя на чувствительность к цене/ценности, и все три модели выдают разные оценки уверенности и разные цитаты — где-то дословные, где-то пересказанные.
Это очевидно, когда все три видны рядом, но у большинства команд есть один корпоративный аккаунт LLM, и они не видят слабостей именно своей модели. ChatGPT суммирует и склеивает «дословные» цитаты, Claude более консервативен с оценками уверенности, а Gemini часто выбирает слишком короткие фрагменты речи клиента.
Моя рекомендация: если есть выбор, используйте Claude для аналитической работы. Он покрывает больше материала, оставаясь укоренённым в реальных данных. Вы получаете глубину и широту без необходимости его сильно «продавливать». Платой служит то, что он не фильтрует за вас. Вы часто будете получать валидированные паттерны и наполовину сформированные гипотезы на равных правах — и вам придётся проверять, что темы хорошо доказаны. Но это лучшая стартовая позиция, чем промптить трижды, прежде чем удостовериться, что ваш аналитический партнёр ничего не упустил.
Замечание по примерам: для единообразия примеры в этом посте обычно используют ChatGPT. Это по-прежнему самая распространённая модель среди моих клиентских команд и студентов, и она же наиболее склонна к режимам ошибок, которые я разбираю. Исправления работают и улучшают результаты во всех трёх моделях.
Четыре способа, которыми AI-анализ данных вам лжёт, и как это исправить
После более 2 000 часов тестирования воркфлоу клиентского discovery с AI я нашла четыре отчётливых режима ошибок AI-анализа — и надёжные исправления для каждого, которые стабильно работают на всех платформах, типах данных, моделях и воркфлоу.
Режим ошибки №1: выдуманные свидетельства
Как выглядит проблема
Несмотря на огромные улучшения почти во всех reasoning-моделях, галлюцинаций по-прежнему хватает. Когда я смотрю через плечо продактов, занимающихся анализом, я постоянно вижу два типа галлюцинаций:
Полностью выдуманные цитаты (всё ещё встречаются у всех трёх главных LLM)Цитаты-«франкенштейны», сшитые из нескольких источников и в целом передающие то, что говорил пользователь… но это не его реальные слова (особенно часто встречается у ChatGPT)
Оба типа остаются незамеченными, если вы не проверяете каждую цитату вручную, и оба часто вызваны тем, как вы промптите. Вы можете довольно легко и случайно спровоцировать ChatGPT склеивать несколько клиентских цитат так, что это исказит понимание сказанного. Когда вы добавляете фразы вроде «макс. 100 слов» или «для каждой темы дай хлёсткую и репрезентативную цитату, отражающую её (≤12 слов)», вы почти всегда получаете «мэш-апы». Выделения в примере ниже — это как раз такие комбинации, а не точные реальные слова клиента.

Почему это происходит
LLM не извлекают цитаты как поисковая машина; они генерируют текст, который статистически вероятен в данном контексте. Генерация и извлечение принципиально разные вещи. Модель предсказывает, как должна выглядеть цитата. Если контекст про раздражение от проверки телефона, она генерирует правдоподобный язык про раздражение от проверки телефона. Иногда это совпадает с оригиналом, иногда близко, а иногда — полностью выдумано.
«Verbatim» (дословно) — тоже неоднозначное слово для промпта. Точные символы? Можно ли менять пунктуацию? А слова-паразиты? Где начинается и заканчивается цитата? Модель заполняет эти пробелы предположениями, которые вы никогда не увидите. Даже ID участников и таймштампы могут быть подделаны. Цитирование вроде «[P03, 14:30]» выглядит авторитетно, но ничего не значит, если сама цитата выдумана.
Решение: правила отбора цитат + верификация
Решение этой проблемы, независимо от модели, типа данных или воркфлоу, состоит из двух частей. Сначала определите, как именно выглядит валидная цитата — ваши «правила цитат», — это убирает неоднозначность, которой пользуется AI для заполнения пробелов. А затем проверьте, что цитаты в полученном AI-анализе действительно существуют, прежде чем разрешать модели их использовать.
1. Определите свои «правила цитат»
Добавьте это в свой аналитический промпт:
ПРАВИЛА ОТБОРА ЦИТАТНачинай там, где начинается мысль, и продолжай, пока она полностью не выраженаВключай рассуждение, а не только выводыСохраняй оговорки и уточнения — они сигнализируют о неуверенностиВключай эмоциональную лексику, если она естьЦитируй с ID участника и приблизительным таймштампом [P02 ~14:30]Не объединяй высказывания из разных частей интервьюЕсли цитата превышает 3 предложения, разбей её на отдельные цитаты
Это убирает неоднозначность. Теперь модель знает, что «verbatim» значит для вас: где начинать, где останавливаться, что включать, что не комбинировать.
Я всегда призываю клиентские команды и слушателей курсов критически подумать о том, что делает цитату «хорошей» именно для них. Скорее всего, вы получите значительно лучшие результаты сразу с моим сниппетом (это моё любимое copy-paste включение), но ещё лучшие — если добавите собственные определения.
2. Верифицируйте перед использованием
После первоначального анализа используйте этот промпт верификации, чтобы LLM подтвердил, что это реальные цитаты:
ВЕРИФИКАЦИЯ ЦИТАТДля каждой цитаты в анализе выше:Подтверди, что цитата существует дословно в исходном транскриптеЕсли цитата — близкий пересказ, но не точная — пометь её и приведи реальную формулировкуЕсли цитату не удаётся найти — пометь как NOT FOUNDФормат вывода:Цитата: [сама цитата]Статус: VERIFIED / PARAPHRASE / NOT FOUNDЕсли пересказ: Реальная формулировка: [что сказали на самом деле]Местоположение: [ID участника, таймштамп или номер строки]
Вот что происходит, когда вы это запускаете:

Большинство цитат в предыдущем выводе ChatGPT оказались пересказом, а не оригинальными дословными высказываниями клиентов. И это произошло при запросе небольшого набора цитат — представьте, что будет, когда вы прорабатываете 20 интервью и получаете столько же паттернов.
Без верификации такие «цитаты» оказываются в вашей презентации, приписанные реальному участнику. Иногда это не страшно. В других случаях это разница между продуктовым языком, который сильно резонирует, и сообщениями, которые не конвертируют.
Это часто занимает всего лишних пять минут — в зависимости от объёма данных. Но это ловит ошибки, которые иначе подорвали бы доказательную базу ваших продуктовых решений.
Режим ошибки №2: ложные или слишком общие инсайты
Как выглядит проблема
AI находит темы, которые слишком широки и общи, чтобы что-то с ними сделать, или смещены тем, чем вы случайно его «накачали». В интервью вы получаете темы, которые могли бы описывать любой продукт в вашей категории. Я постоянно слышу это от PM-ов: «AI-анализ просто сказал мне то, что я и так знаю» или «Эти инсайты слишком общие. Я ничего не могу с ними сделать».
Они получают выводы вроде:
«Цена — один из факторов в решениях»«Люди ценят надёжность»«Пользователи хотят больше real-time информации»
Правда, наверное, но бесполезно для сложных решений — нам надо копать глубже. Эти темы могли бы прийти из множества исследований. Поскольку я работаю здесь со своими фейковыми данными Whoop, они также легко могли бы прийти из любого исследования носимых устройств.
Такие темы не говорят вам, хотят ли ваши пользователи именно эту новую фичу, которую вы рассматриваете, достаточно, чтобы оправдать инвестицию, и не оттолкнёт ли её добавление клиентов, которые выбрали вас именно потому, что вы другие.
Почему это происходит
AI по умолчанию ищет консенсус, потому что LLM — это машины поиска паттернов. Они вытаскивают (очевидные) паттерны, которые легко всплывают наверх, находят то, что упомянули несколько участников, и затем генерируют тему, подогнанную под паттерн.
По-настоящему важный инсайт может оказаться чем-то, что в этой конкретной партии интервью сказали лишь несколько человек, но что, если бы это разделяло больше клиентов, стало бы заметным бизнес-сигналом. Или самым важным инсайтом может быть напряжение между тем, что люди говорят, что хотят, и тем, что подсказывает их поведение.
LLM также тащат с собой априорные предположения из обучения. Если модель видела тысячи анализов оттока, где цена — тема №1, она будет смещать веса в сторону цены, даже если ваш полный датасет этого не подтверждает.
В опросах эта склонность к поверхностному паттерн-матчингу ещё хуже. Когда кто-то при отмене пишет «Это не для меня», AI приходится гадать, что это значит. Без указаний он, скорее всего, свалит этот ответ вместе с другими в общую тему «восприятие ценности». Но «не стоит того» может означать:
Слишком дорого за то, что я получуСлишком много данных, а я недостаточно серьёзный спортсменЯ не хочу ещё одно устройство, которое надо заряжатьМне нужен экран, а у Whoop его нет
Один ответ — четыре совершенно разных следствия для вашего продуктового решения. Умножьте эту неоднозначность на сотни ответов в опросе, и ваши «темы» превратятся в бессмысленные средние, которые не упрощают принятие решений.
LLM обучены искать консенсус и сжимать информацию. Специфика и ценные edge cases теряются. И если ваш промпт упоминает «проблемы с ценообразованием», посмотрите, сколько ответов внезапно закодируются как связанные с ценой.
В некоторых случаях это может быть полезно, потому что модель следит, чтобы все выводы были релевантны конкретной задаче. Но во многих случаях это может быть смещённым cherry-picking с самого начала.
Вот пример:
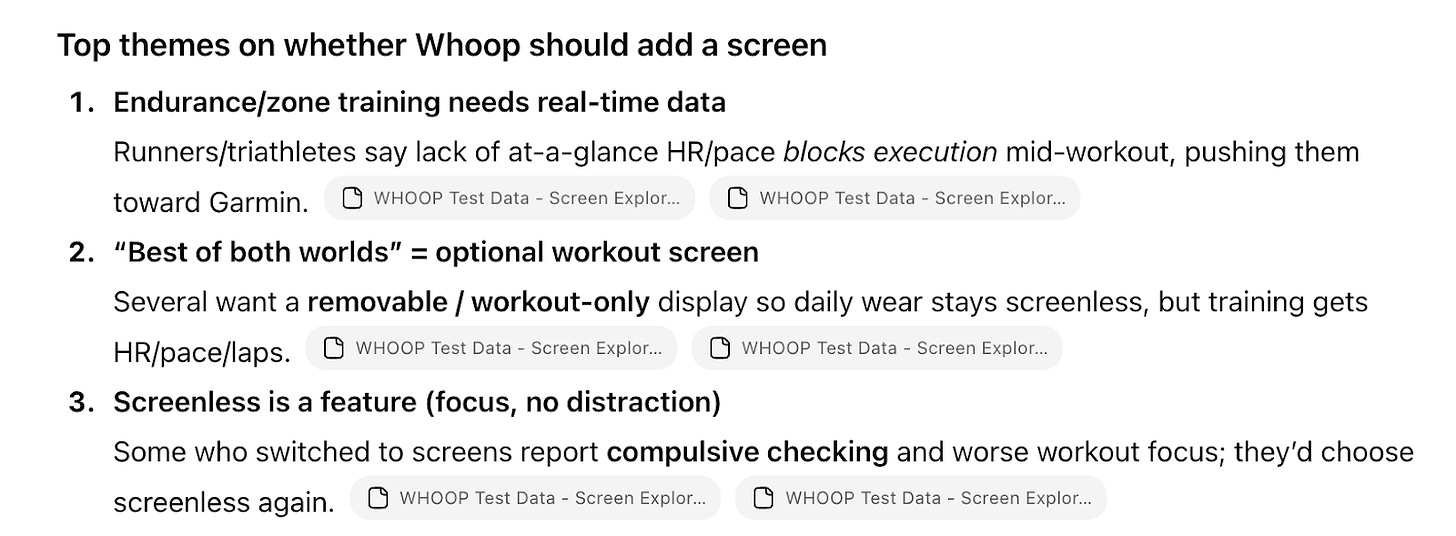
Это могло бы описывать любое исследование носимых устройств. Принять решение по железу на этом мы не сможем.
Ещё пример:
Я попросила ChatGPT найти мне тематические кластеры и подсчёты по вопросу из опроса об оттоке: «Что вы надеялись сделать, в чём Whoop вас не поддержал?»
Результаты ниже — это кластеры, которые тоже не помогают принять это решение. Допустим, 18% отписавшихся респондентов хотят «больше практических рекомендаций», что звучит как job-to-be-done. Но внутри этого кластера слишком много возможных направлений, чтобы решение далось проще. Должен ли Whoop сосредоточиться на более понятных метриках или на планах тренировок, или и на том, и на другом? Плюс, бóльшая часть этого вообще не имеет отношения к нашему решению по экрану.
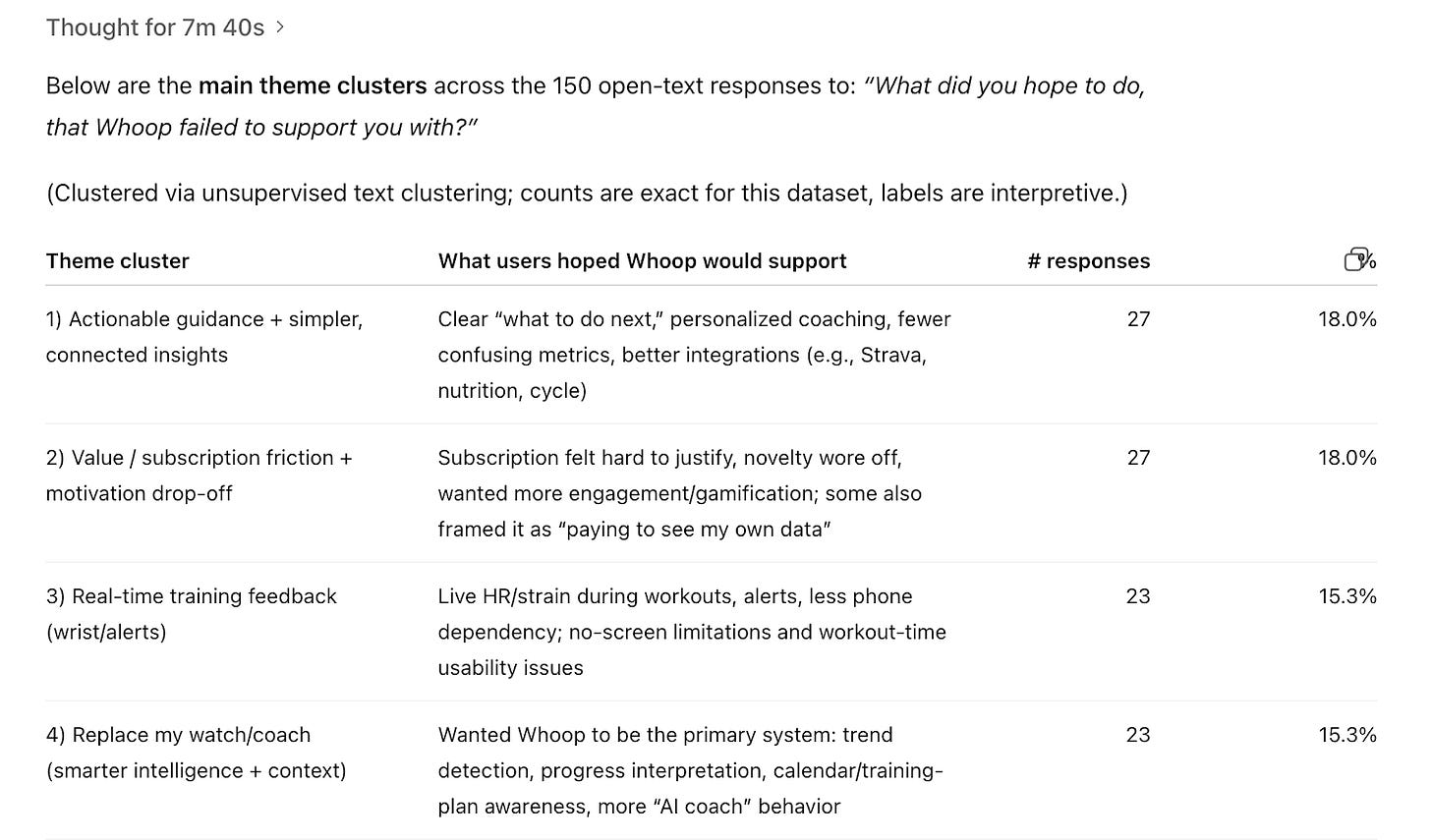
Когда мы просим AI кластеризовать ответы опроса, нам нужно дать ему чёткое направление с контекстом — иначе мы оставляем место для посредственных решений и большего количества ручной работы.
Решение: загрузка контекста, которая действительно направляет интерпретацию
Большинство людей привыкли к фреймворкам промптов с секциями вроде Role, Context, Task, Format и так далее. Для большинства из нас контекст означает несколько строк фоновой информации в промпте, где-то ближе к началу. Когда мы используем AI для анализа, это часто сосредоточено на сути текущего клиентского discovery. Например: цели, гипотезы и часть продукта, над которой мы работаем.
За последний год я всё чаще вижу, как люди превращают секцию «контекст» в промпте в четыре абзаца всего, что приходит в голову про их работу, часто надиктованного потоком мысли за обедом.
Но ни три строки целей, ни вся эта неструктурированная предыстория недостаточно хороши. Эффективная загрузка контекста имеет как минимум четыре компонента, которые формируют то, как AI интерпретирует всё последующее:
Project context сообщает AI масштаб и ставки. «Исследуем, добавлять ли экран» — это конкретное решение с ограничениями. «Делаем клиентское исследование» — расплывчато, и AI по умолчанию свалится в общий анализ, потому что вы не дали ему рамки.Business goal сообщает AI, чего вы пытаетесь добиться. Если вам нужно понять, привлечёт ли фича новых пользователей или оттолкнёт существующих, чтобы расставить приоритеты в её разработке, скажите это. AI будет взвешивать свидетельства в сторону ответа на ваш вопрос и вашего решения, а не того, которое он предполагает.Product context даёт AI доменные знания. Без него AI интерпретирует «Я хочу видеть свои данные» обобщённо. С ним AI понимает это утверждение в контексте безэкранного wearable, конкурирующего с Apple Watch — совершенно иная интерпретация.Participant overview сообщает AI, кто говорит. «Мне нужны real-time данные» от ушедшего к Garmin пользователя значит не то же, что те же слова от лояльного пользователя, который никогда не пробовал конкурентов. AI может правильно взвешивать свидетельства, только если знает, от кого они исходят.
Хорошая новость в том, что многое из того, что люди добавляют в контекст промптов, излишне. Вам часто нужно не столько информации, сколько кажется, но она должна быть ясной, прямой и релевантной — как четыре пункта выше.
Для интервью вставьте этот контекст в аналитический промпт (или используйте как единый промпт):