
P7: You Don’t Need a Graph DB (Probably) – Hamel’s Blog - Hamel Husain
Очередная статья из серии Hamel Husain о RAG, основанная на докладе Jo Kristian Bergum — ветерана поиска с 25-летним опытом (Yahoo, Vespa). Главный тезис: серебряной пули не существует, и графовая БД редко нужна, прежде чем исчерпаны более простые варианты. Если документов мало (например, всего 300), а запросов немного, проще загнать всё в контекстное окно — современные модели вроде Gemini держат до 1 млн токенов (около 3 МБ текста). Граф знаний — это набор триплетов (source_entity, relationship, target_entity), который можно хранить в CSV, JSON или Postgres; ранний Facebook держал свой соцграф на MySQL. Перед внедрением любого метода вроде GraphRAG нужно построить «золотой датасет» и измерять результаты метриками MRR, precision и recall. Кроме того, современный векторный поиск через алгоритм HNSW уже основан на графах, так что графоподобные стратегии извлечения можно реализовать без новой инфраструктуры.
Every so often, a technology captures the industry’s attention. Graph databases are having their turn, fueled by a desire to have a powerful way to augment LLMs with your data. The logic seems simple: if your data is connected, you need a graph.
Время от времени какая-нибудь технология захватывает внимание индустрии. Сейчас черёд графовых баз данных — их подпитывает желание получить мощный способ дополнять LLM собственными данными. Логика кажется простой: если ваши данные связаны, значит, вам нужен граф.
Throughout this series, we’ve argued that naive single-vector RAG is dead and shown more sophisticated approaches: better evals, reasoning, late interaction and multiple representations. But sophistication isn’t the same as complexity. There’s no better example of unnecessary complexity than reaching for a graph database before you’ve exhausted simpler options.
На протяжении всей этой серии мы доказывали, что наивный одновекторный RAG мёртв, и показывали более продвинутые подходы: более качественные оценки, рассуждение, позднее взаимодействие и множественные представления. Но продвинутость — это не то же самое, что сложность. Нет лучшего примера излишней сложности, чем хвататься за графовую базу данных, не исчерпав более простые варианты.
That’s why I hosted a talk with Jo Kristian Bergum. Jo is a 25-year veteran in search and retrieval, with experience at Yahoo and Vespa. He’s one of the few who publicly shares this skepticism.
Именно поэтому я провёл беседу с Jo Kristian Bergum. Jo — 25-летний ветеран в области поиска и извлечения данных, с опытом работы в Yahoo и Vespa. Он один из немногих, кто публично разделяет этот скептицизм.
Jo covers when graph databases are overkill and when they make sense.
Jo рассказывает, когда графовые базы данных — это перебор, а когда они имеют смысл.
Below is an annotated version of his presentation.
Ниже приведена аннотированная версия его презентации.
👉 These are the kinds of things we cover in our AI Evals course. You can learn more about the course here. 👈
👉 Именно такие вещи мы разбираем в нашем курсе AI Evals. Узнать больше о курсе можно здесь. 👈
 (
(The Hunt for a Silver Bullet
Охота за серебряной пулей
Interest in RAG has exploded since late 2022. More engineers than ever are tackling search problems. But this led to a frantic search for a silver bullet.
Интерес к RAG взрывообразно вырос с конца 2022 года. Над задачами поиска сейчас работает больше инженеров, чем когда-либо. Но это привело к лихорадочным поискам серебряной пули.
First, it was the specialized vector database. Now, with the popularity of a Microsoft paper on “GraphRAG,” the pendulum is swinging toward graph databases.
Сначала это была специализированная векторная база данных. Теперь, на волне популярности статьи Microsoft о «GraphRAG», маятник качнулся в сторону графовых баз данных.
Jo argues this is flawed thinking. There is no single tool that will solve all your problems. The desire to map a new technique (GraphRAG) to a technology (a graph DB) is a trap many engineers fall into.
Jo считает, что такое мышление ошибочно. Не существует единственного инструмента, который решит все ваши проблемы. Желание сопоставить новый приём (GraphRAG) с конкретной технологией (графовой БД) — это ловушка, в которую попадают многие инженеры.
 (
(Do You Even Need RAG?
А нужен ли вам вообще RAG?
Before we get to graphs: do you need a retrieval component?
Прежде чем перейти к графам: нужен ли вам компонент извлечения данных?
The “R” in RAG stands for retrieval. The classic information retrieval (IR) model involves a user with an information need, a query, a retrieval system, and a ranked list of documents.
Буква «R» в RAG означает retrieval (извлечение). Классическая модель информационного поиска (IR) включает пользователя с информационной потребностью, запрос, систему извлечения и ранжированный список документов.
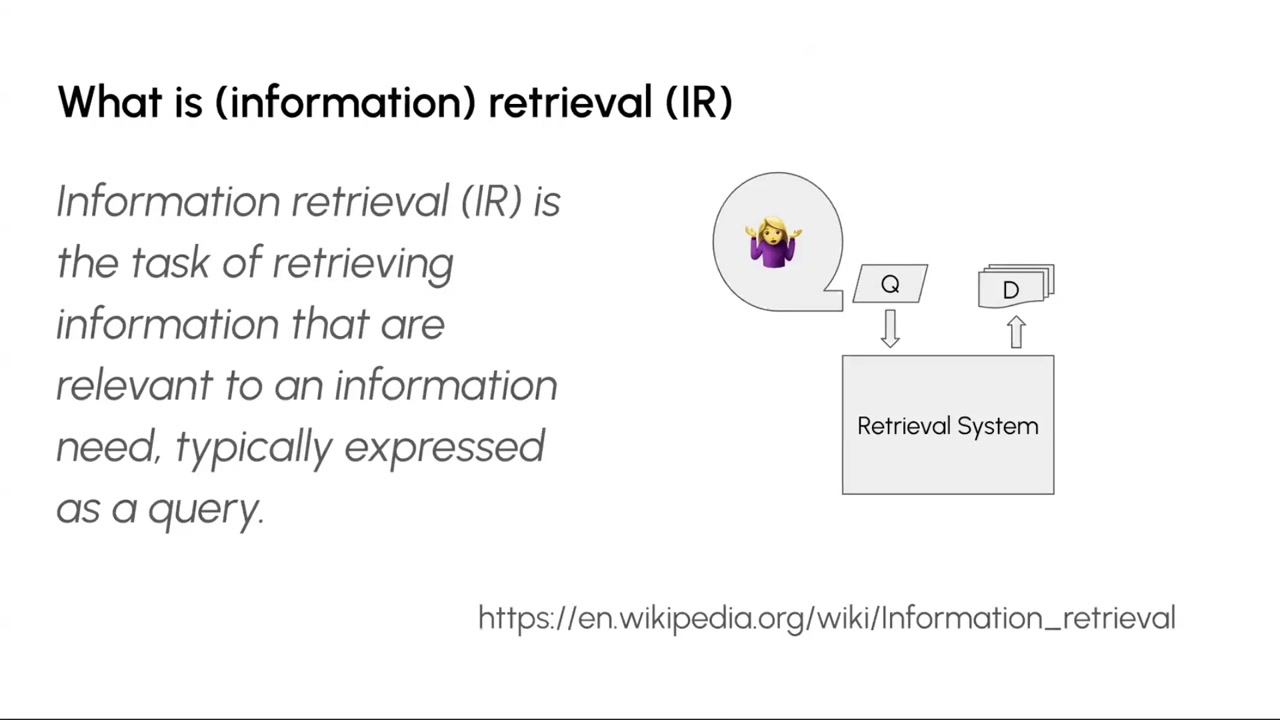 (
(When LLMs had tiny 8k context windows, retrieval was a necessity. But now, models like Gemini can handle 1 million tokens. That’s about 3 megabytes of raw text, the equivalent of an old floppy disk.
Когда у LLM были крошечные контекстные окна в 8k, извлечение было необходимостью. Но теперь модели вроде Gemini справляются с 1 миллионом токенов. Это около 3 мегабайт сырого текста — эквивалент старой дискеты.
 (
(Jo shared an anecdote about a company struggling with a complex RAG pipeline. When he asked how many documents they had, the answer was 300. For that scale, he advised them to feed all the documents into the LLM’s context window. It was simpler, cheaper, and more effective than over-engineering a retrieval stack.
Jo поделился историей о компании, которая мучилась со сложным RAG-пайплайном. Когда он спросил, сколько у них документов, ответ был — 300. Для такого масштаба он посоветовал им просто загрузить все документы в контекстное окно LLM. Это было проще, дешевле и эффективнее, чем переусложнять стек извлечения.
If your document set is small enough and your query volume is low, stuffing the context window is a valid strategy.
Если набор ваших документов достаточно мал, а объём запросов невелик, заполнение контекстного окна — вполне рабочая стратегия.
This connects to Kelly Hong’s research on context rot (Part 6). Her experiments showed that LLM performance degrades with distractors (documents that are similar but contain different information). When your documents cover distinct topics with little overlap, you sidestep this problem. Few distractors means less context rot.
Это перекликается с исследованием Kelly Hong о «гниении контекста» (context rot) (Часть 6). Её эксперименты показали, что производительность LLM ухудшается при наличии отвлекающих факторов (документов, которые похожи, но содержат другую информацию). Когда ваши документы охватывают разные темы с малым пересечением, вы обходите эту проблему стороной. Меньше отвлекающих факторов — меньше гниения контекста.
But most real-world corpora don’t look like this. They have overlapping content, similar documents, and scale beyond what fits in context. That’s when retrieval becomes essential.
Но большинство реальных корпусов выглядят иначе. В них есть пересекающийся контент, похожие документы, и они масштабируются за пределы того, что помещается в контекст. Вот тогда извлечение становится необходимым.
Deconstructing GraphRAG
Разбираем GraphRAG по косточкам
So what is this “GraphRAG” that’s causing all the fuss? The technique, as described in the Microsoft paper, involves a few steps:
Так что же такое этот «GraphRAG», вокруг которого столько шума? Этот приём, как описано в статье Microsoft, состоит из нескольких шагов:
Обработка корпуса: используйте LLM, чтобы прочитать всю вашу коллекцию документов. Это дорогостоящий офлайн-процесс. Построение графа знаний: попросите LLM извлечь сущности (узлы) и связи между ними (рёбра). Запрос к графу: во время запроса обходите этот граф в поисках релевантной информации.
The challenge is building and maintaining the graph. A knowledge graph is a collection of triplets: (source_entity, relationship, target_entity). You can store this in a CSV file, a JSON object, or a standard relational database like Postgres.
Сложность заключается в построении и поддержании графа. Граф знаний — это набор триплетов: (source_entity, relationship, target_entity). Вы можете хранить это в CSV-файле, JSON-объекте или обычной реляционной базе данных вроде Postgres.
 (
(The hard part is keeping everything accurate. That means either spending tokens on LLM calls, or getting domain experts to help.
Самое трудное — поддерживать всё в точном состоянии. А это значит либо тратить токены на вызовы LLM, либо привлекать к помощи экспертов в предметной области.
Evaluation
Оценка
How do you know if adding a knowledge graph, or any new technique, is improving your results? You have to measure it.
Как понять, улучшает ли результаты добавление графа знаний или любого другого нового приёма? Это нужно измерять.
This is the step most teams skip. They jump from one new method to the next without a stable benchmark. As Nandan showed in Part 2, you need an evaluation framework before you can make good decisions about retrieval techniques. In retrieval, we use metrics like:
Именно этот шаг большинство команд пропускают. Они прыгают от одного нового метода к другому без стабильного эталона. Как Nandan показал в Части 2, вам нужна система оценки прежде, чем вы сможете принимать грамотные решения о приёмах извлечения. В извлечении мы используем такие метрики, как:
Mean Reciprocal Rank (MRR): измеряет, насколько высоко в списке появляется первый релевантный документ. Precision (точность): из возвращённых вами документов сколько было релевантными? Recall (полнота): из всех возможных релевантных документов сколько вы нашли?
To use these metrics, you need an evaluation dataset. This involves taking a sample of real user queries and manually labeling which documents are relevant for each query. This “golden dataset” is your ground truth. It allows you to compare retrieval methods and know if a change is an improvement.
Чтобы использовать эти метрики, нужен датасет для оценки. Для этого берётся выборка реальных пользовательских запросов и вручную размечается, какие документы релевантны для каждого запроса. Этот «золотой датасет» — ваша эталонная истина. Он позволяет сравнивать методы извлечения и понимать, является ли изменение улучшением.
 (
(When to Use a Graph Database
Когда стоит использовать графовую базу данных
Once you have an evaluation framework, you can start asking the right questions. A specialized graph database (like Neo4j) is optimized for fast traversal of graph structures, usually by keeping the graph in memory.
Когда у вас есть система оценки, вы можете начать задавать правильные вопросы. Специализированная графовая база данных (вроде Neo4j) оптимизирована под быстрый обход графовых структур, обычно за счёт хранения графа в памяти.
Before you add one to your stack, ask yourself:
Прежде чем добавлять её в свой стек, задайте себе вопросы:
Нужен ли мне быстрый, низколатентный обход графа? Настолько ли велик мой граф, что более простое решение (вроде Postgres или файла) работает слишком медленно? Требует ли мой сценарий использования сложных многошаговых запросов (например, поиска друзей друзей друзей)?
If the answer to these questions isn’t a clear “yes,” you probably don’t need a specialized graph DB. The operational complexity and cost of adding another database to your stack is high. As Jo pointed out, early Facebook ran its massive social graph on MySQL. You can get surprisingly far with general-purpose tools.
Если ответ на эти вопросы не однозначное «да», то вам, скорее всего, не нужна специализированная графовая БД. Операционная сложность и стоимость добавления ещё одной базы данных в стек высоки. Как отметил Jo, ранний Facebook гонял свой огромный социальный граф на MySQL. С инструментами общего назначения можно зайти на удивление далеко.
 (
(The Graph Hidden in Your Vector Search
Граф, скрытый в вашем векторном поиске
If you’re using modern vector search, you’re already using graphs.
Если вы используете современный векторный поиск, вы уже используете графы.
The most common algorithm for approximate nearest neighbor (ANN) search is HNSW (Hierarchical Navigable Small World). HNSW works by building a graph where the nodes are your vectors and the edges connect vectors that are close in the embedding space. Searching for nearest neighbors means traversing this graph.
Самый распространённый алгоритм для приближённого поиска ближайших соседей (ANN) — это HNSW (Hierarchical Navigable Small World). HNSW работает, строя граф, где узлы — это ваши векторы, а рёбра соединяют векторы, близкие в пространстве эмбеддингов. Поиск ближайших соседей означает обход этого графа.
Jo mentioned the “cluster hypothesis” in information retrieval: documents that are similar to a relevant document are also likely to be relevant.
Jo упомянул «кластерную гипотезу» в информационном поиске: документы, похожие на релевантный документ, тоже, скорее всего, релевантны.
You can use this with any vector DB:
Это можно применять с любой векторной БД:
Запустите стандартный векторный поиск по запросу пользователя. Используйте LLM или реранкер, чтобы выявить наиболее релевантные результаты из этого первоначального набора. Выполните второй векторный поиск, на этот раз ища документы, похожие на только что найденные релевантные документы.
This is a form of graph traversal (finding neighbors of your best results) that can improve recall. You don’t need a specialized graph database to do it.
Это форма обхода графа (поиск соседей ваших лучших результатов), которая может улучшить полноту (recall). И для этого не нужна специализированная графовая база данных.
Key Takeaways
Ключевые выводы
In this series, we’ve shown you how to move beyond naive RAG: better evals, reasoning, late interaction, multiple representations, context engineering. But the goal was never complexity for its own sake.
В этой серии мы показали вам, как выйти за рамки наивного RAG: более качественные оценки, рассуждение, позднее взаимодействие, множественные представления, инженерия контекста. Но цель никогда не была в сложности ради сложности.
Jo’s talk reinforces this. There is no silver bullet. Before you adopt a new method like GraphRAG, build a golden dataset to measure if it improves performance (Part 2). You don’t need special tools. A knowledge graph can live in a CSV file or Postgres. Early Facebook ran their social graph on MySQL. Vector search algorithms like HNSW are already graph-based, so you can implement graph-like retrieval strategies without adding new infrastructure.
Доклад Jo подтверждает это. Серебряной пули не существует. Прежде чем внедрять новый метод вроде GraphRAG, постройте золотой датасет, чтобы измерить, улучшает ли он производительность (Часть 2). Особые инструменты вам не нужны. Граф знаний может жить в CSV-файле или Postgres. Ранний Facebook гонял свой социальный граф на MySQL. Алгоритмы векторного поиска вроде HNSW уже основаны на графах, так что вы можете реализовать графоподобные стратегии извлечения, не добавляя новую инфраструктуру.
👉 These are the kinds of things we cover in our AI Evals course. You can learn more about the course here. 👈
👉 Именно такие вещи мы разбираем в нашем курсе AI Evals. Узнать больше о курсе можно здесь. 👈
Video
Видео
Here is the full video:
Вот полное видео: