
Introducing Claude Opus 4.5
Anthropic представила Claude Opus 4.5 — новейшую модель, доступную с сегодняшнего дня в приложениях, API и на трёх крупнейших облачных платформах. Модель показывает state-of-the-art результаты в реальной разработке ПО, агентных задачах и работе с компьютером, при этом цена снижена до $5/$25 за миллион токенов. На внутреннем экзамене для кандидатов в performance-инженеры Opus 4.5 набрала больше баллов, чем любой человек-кандидат за всё время, а на SWE-bench Verified при максимальном уровне effort превосходит Sonnet 4.5 на 4,3 процентных пункта, используя на 48% меньше токенов. В API появился новый параметр effort для управления глубиной размышлений, а также context compaction и расширенное использование инструментов. Параллельно вышли обновления Claude Code (новый Plan Mode, десктопное приложение), Claude for Excel, Claude for Chrome и снятие ограничений на использование Opus для пользователей Max и Team Premium.
Представляем Claude Opus 4.5

Наша новейшая модель, Claude Opus 4.5, доступна с сегодняшнего дня. Она умная, эффективная и лучшая в мире для кодинга, агентов и работы с компьютером. Она также заметно лучше справляется с повседневными задачами вроде глубоких исследований и работы со слайдами и таблицами. Opus 4.5 — это шаг вперёд в возможностях AI-систем и предвестник более крупных изменений в том, как делается работа.
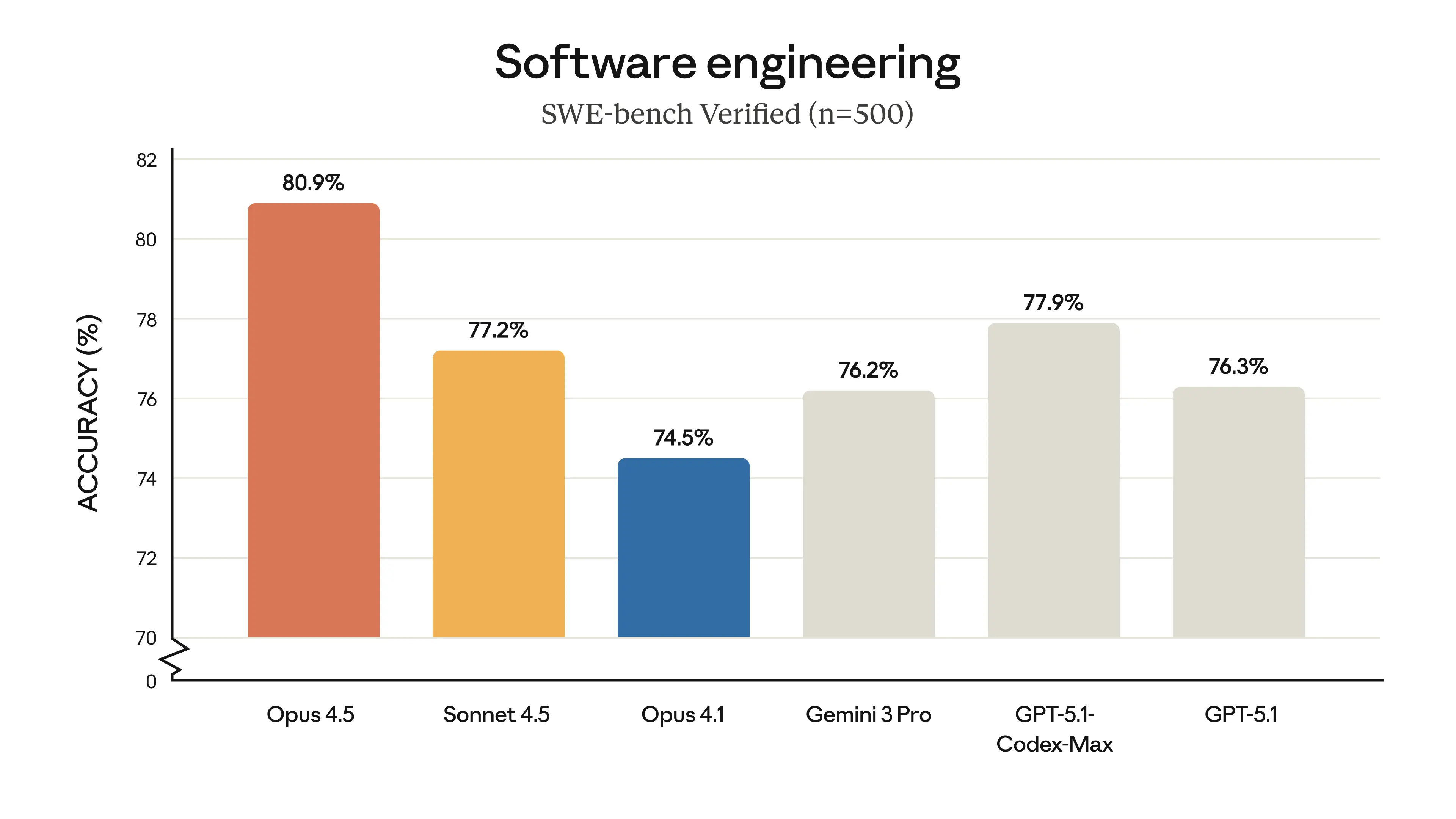
Claude Opus 4.5 показывает state-of-the-art результаты в тестах на реальную инженерию ПО:
Opus 4.5 доступна с сегодняшнего дня в наших приложениях, API и на всех трёх крупнейших облачных платформах. Если вы разработчик, просто используйте claude-opus-4-5-20251101 через Claude API. Цена теперь составляет $5/$25 за миллион токенов — это делает возможности уровня Opus доступными ещё большему числу пользователей, команд и предприятий.
Вместе с Opus мы выпускаем обновления для Claude Developer Platform, Claude Code и наших потребительских приложений. Появились новые инструменты для долгоиграющих агентов и новые способы использовать Claude в Excel, Chrome и на десктопе. В приложениях Claude длинные разговоры больше не упираются в стену. Подробности — в продуктовом разделе ниже.
Первые впечатления
Когда наши коллеги в Anthropic тестировали модель до релиза, мы получали удивительно однотипные отзывы. Тестировщики отмечали, что Claude Opus 4.5 справляется с неоднозначностью и рассуждает о компромиссах без подсказок. Они рассказывали, что, когда модель направляют на сложный многосистемный баг, Opus 4.5 находит решение. Они говорили, что задачи, которые ещё несколько недель назад были практически непосильны для Sonnet 4.5, теперь по плечу. В целом, наши тестировщики говорили, что Opus 4.5 просто «врубается».
Многие из наших клиентов с ранним доступом получили похожий опыт. Вот несколько примеров того, что они нам рассказали:

Модели Opus всегда были «настоящим SOTA», но раньше были запретительно дорогими. Claude Opus 4.5 теперь по такой цене, что может стать вашей основной моделью для большинства задач. Это явный победитель, и она демонстрирует лучшее планирование задач и вызов инструментов на фронтире из всего, что мы видели.

Claude Opus 4.5 выдаёт высококачественный код и отлично подходит для тяжёлых агентных рабочих процессов с GitHub Copilot. Раннее тестирование показывает, что она превосходит внутренние бенчмарки по кодингу, сокращая использование токенов вдвое, и особенно хорошо подходит для задач вроде миграции и рефакторинга кода.

Claude Opus 4.5 опережает Sonnet 4.5 и конкурентов на наших внутренних бенчмарках, используя меньше токенов для решения тех же задач. На большом масштабе эта эффективность накапливается.

Claude Opus 4.5 обеспечивает фронтирные рассуждения в режиме чата Lovable, где пользователи планируют и итерируют проекты. Глубина её рассуждений преображает планирование — а отличное планирование делает генерацию кода ещё лучше.

Claude Opus 4.5 превосходно справляется с долгосрочными автономными задачами, особенно теми, что требуют устойчивых рассуждений и многошагового исполнения. В наших оценках она справлялась со сложными рабочими процессами с меньшим количеством тупиков. На Terminal Bench она показала улучшение в 15% по сравнению с Sonnet 4.5 — значимый прирост, который особенно заметен при использовании Planning Mode в Warp.

Claude Opus 4.5 достигла state-of-the-art результатов в сложных корпоративных задачах на наших бенчмарках, превзойдя предыдущие модели в многошаговых задачах рассуждения, сочетающих извлечение информации, использование инструментов и глубокий анализ.

Claude Opus 4.5 даёт измеримый прирост там, где это важнее всего: более сильные результаты на наших самых сложных оценках и стабильная производительность в течение 30-минутных автономных сеансов кодинга.

Claude Opus 4.5 представляет собой прорыв в самоулучшающихся AI-агентах. При автоматизации офисных задач наши агенты смогли автономно совершенствовать собственные возможности — достигая пиковой производительности за 4 итерации, в то время как другие модели не могли сравниться с этим качеством и после 10. Они также продемонстрировали способность учиться на опыте в технических задачах, сохраняя инсайты и применяя их позже.

Claude Opus 4.5 — это заметное улучшение по сравнению с предыдущими моделями Claude внутри Cursor, с улучшенной ценой и интеллектом в сложных задачах кодинга.

Claude Opus 4.5 — ещё один пример того, как Anthropic раздвигает фронтир общего интеллекта. Модель отлично проявляет себя в сложных задачах кодинга, демонстрируя долгосрочное целенаправленное поведение.

Claude Opus 4.5 выполнила впечатляющий рефакторинг, охватывающий две кодовые базы и три скоординированных агента. Она была очень тщательной, помогая разработать надёжный план, обрабатывая детали и исправляя тесты. Явный шаг вперёд по сравнению с Sonnet 4.5.

Claude Opus 4.5 справляется с долгосрочными задачами кодинга эффективнее любой модели, что мы тестировали. Она достигает более высокого процента прохождения отложенных тестов, используя при этом до 65% меньше токенов, что даёт разработчикам реальный контроль над затратами без ущерба для качества.

Мы обнаружили, что Opus 4.5 превосходно интерпретирует то, чего на самом деле хотят пользователи, и выдаёт пригодный для распространения контент с первой попытки. В сочетании с её скоростью, эффективностью по токенам и удивительно низкой ценой, это первый раз, когда мы делаем Opus доступной в Notion Agent.

Claude Opus 4.5 превосходно справляется с повествованием с длинным контекстом, генерируя главы на 10-15 страниц с сильной организацией и связностью. Это открыло сценарии использования, которые мы раньше не могли надёжно реализовать.

Claude Opus 4.5 устанавливает новый стандарт автоматизации Excel и финансового моделирования. Точность на наших внутренних оценках выросла на 20%, эффективность поднялась на 15%, а сложные задачи, казавшиеся когда-то недостижимыми, стали выполнимыми.

Claude Opus 4.5 — единственная модель, которая безупречно справляется с некоторыми из наших самых сложных 3D-визуализаций. Отточенный дизайн, со вкусом сделанный UX и отличное планирование и оркестрация — и всё это с более эффективным использованием токенов. Задачи, которые у предыдущих моделей занимали 2 часа, теперь занимают тридцать минут.

Claude Opus 4.5 находит больше проблем при code review, не жертвуя точностью. Для production-ревью кода в масштабе эта надёжность имеет значение.

По результатам тестирования с Junie, нашим агентом для кодинга, Claude Opus 4.5 превосходит Sonnet 4.5 по всем бенчмаркам. Ей требуется меньше шагов для решения задач и, как следствие, меньше токенов. Это указывает на то, что новая модель более точна и более эффективно следует инструкциям — направление, которому мы очень рады.

Параметр effort — блестящее решение. Claude Opus 4.5 ощущается динамично, а не как «переосмысливающая», и на более низком уровне effort выдаёт то же качество, которое нам нужно, будучи при этом значительно эффективнее. Этот контроль — именно то, что требуется нашим SQL-процессам.

Мы видим сокращение на 50–75% как ошибок при вызове инструментов, так и ошибок build/lint с Claude Opus 4.5. Модель стабильно завершает сложные задачи за меньшее число итераций с более надёжным исполнением.

Claude Opus 4.5 работает гладко, без острых углов, которые мы видели у других фронтирных моделей. Улучшения скорости — выдающиеся.
Оценка Claude Opus 4.5
Мы даём потенциальным кандидатам на позицию инженера по производительности печально известный сложный домашний экзамен. Мы также тестируем новые модели на этом экзамене как на внутреннем бенчмарке. В рамках установленного нами лимита в 2 часа Claude Opus 4.5 набрала больше баллов, чем любой кандидат-человек за всю историю1.
Домашний тест разработан для оценки технических способностей и суждения под давлением времени. Он не проверяет другие важные навыки, которыми могут обладать кандидаты, такие как сотрудничество, коммуникация или интуиция, развивающаяся годами. Но этот результат — когда AI-модель превосходит сильных кандидатов в важных технических навыках — поднимает вопросы о том, как AI изменит инженерию как профессию. Наши исследования Societal Impacts и Economic Futures направлены на понимание подобных изменений во многих сферах. Мы планируем поделиться новыми результатами в ближайшее время.
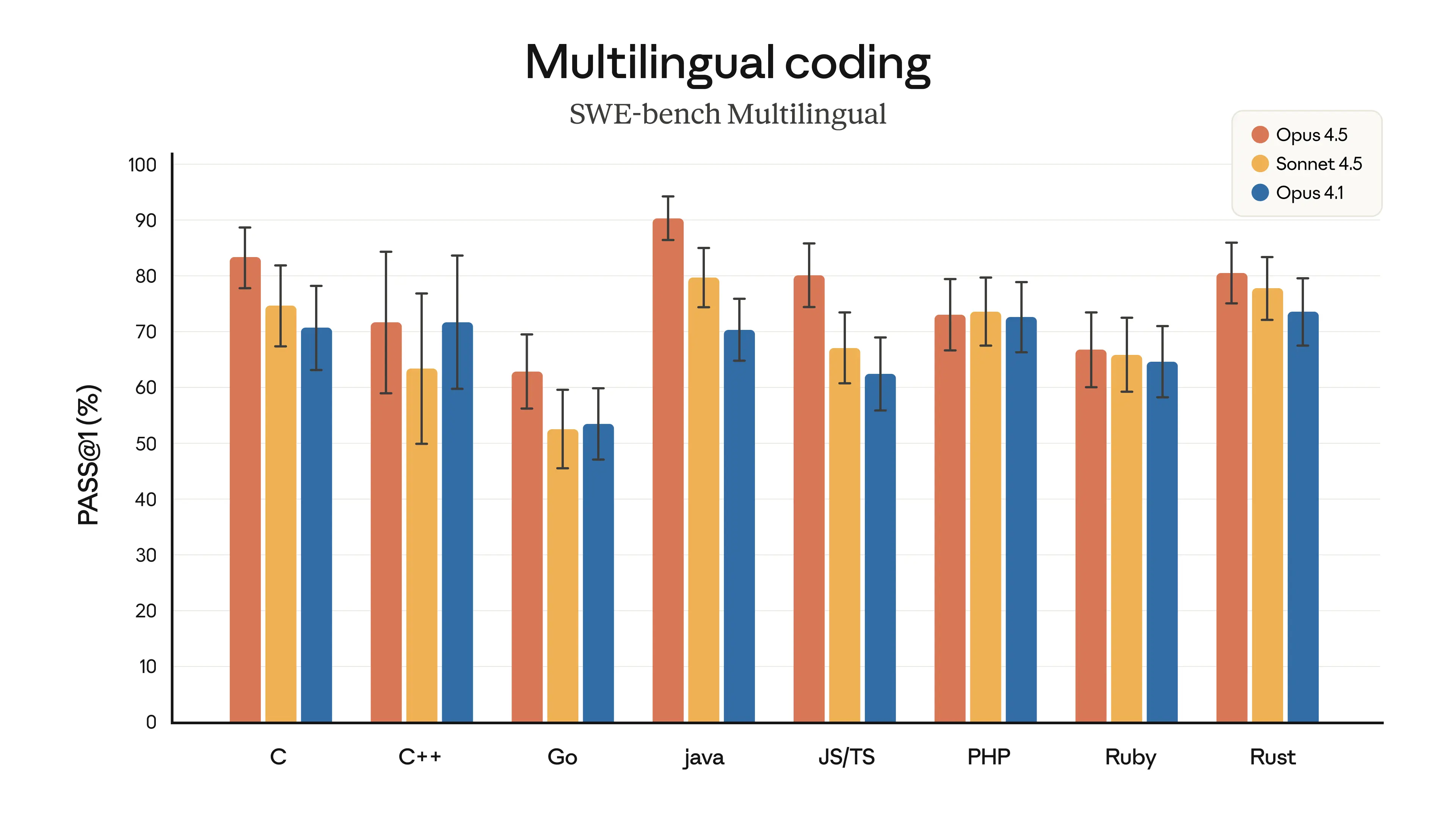
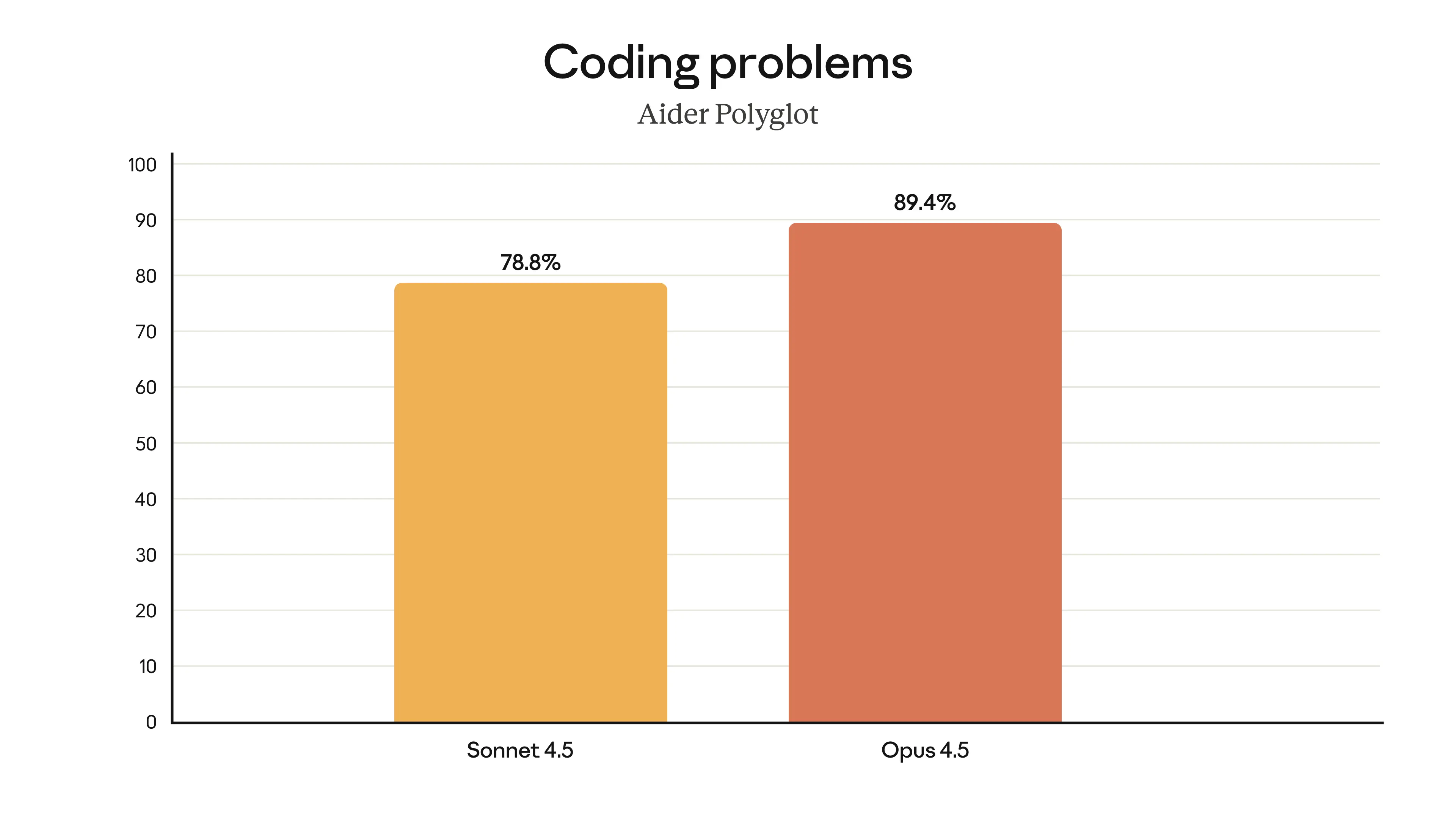
Инженерия ПО — не единственная область, в которой Claude Opus 4.5 стала лучше. Возможности выросли по всем направлениям — у Opus 4.5 лучшее зрение, рассуждение и математические навыки, чем у предшественников, и она показывает state-of-the-art во многих доменах:2
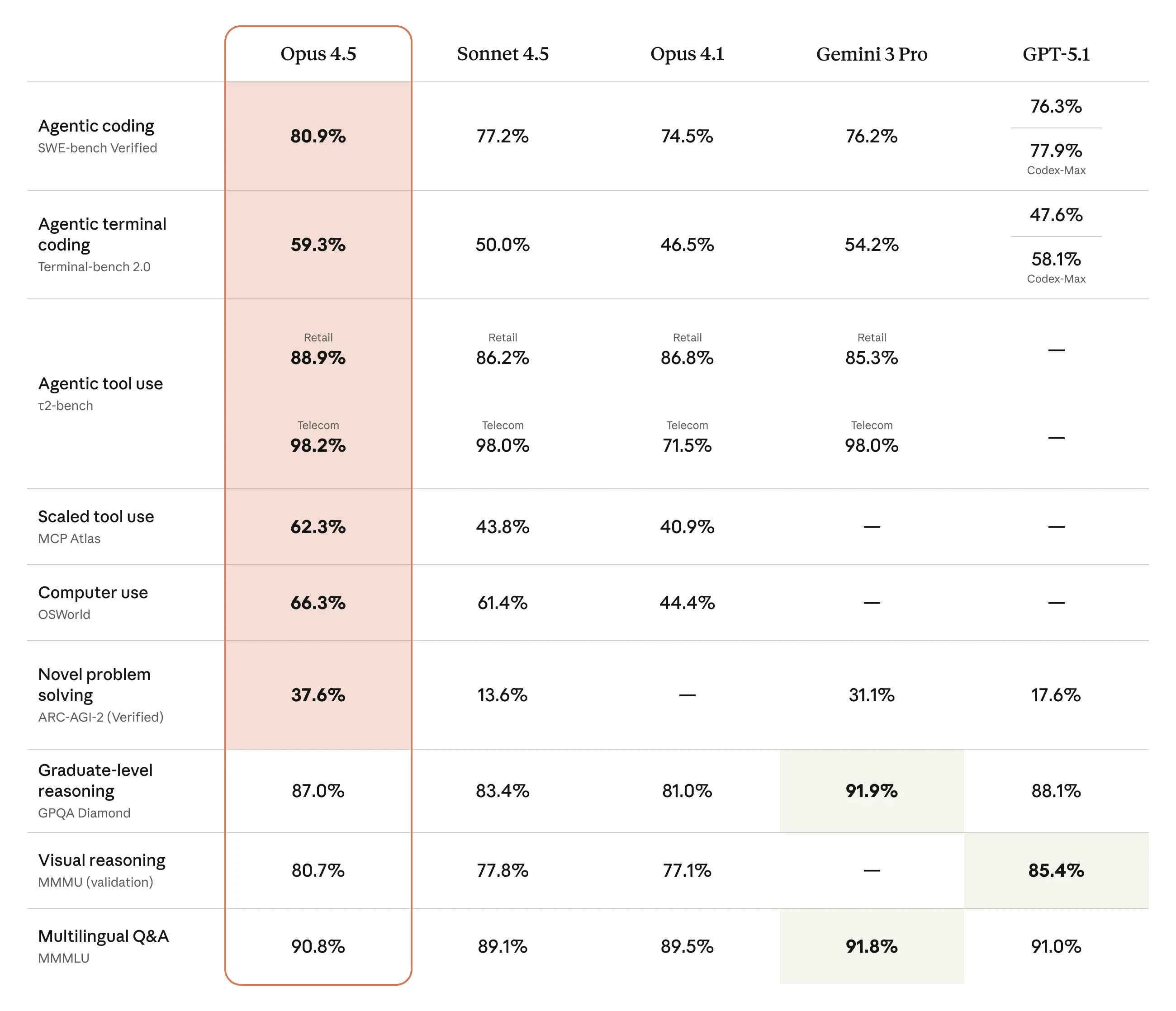
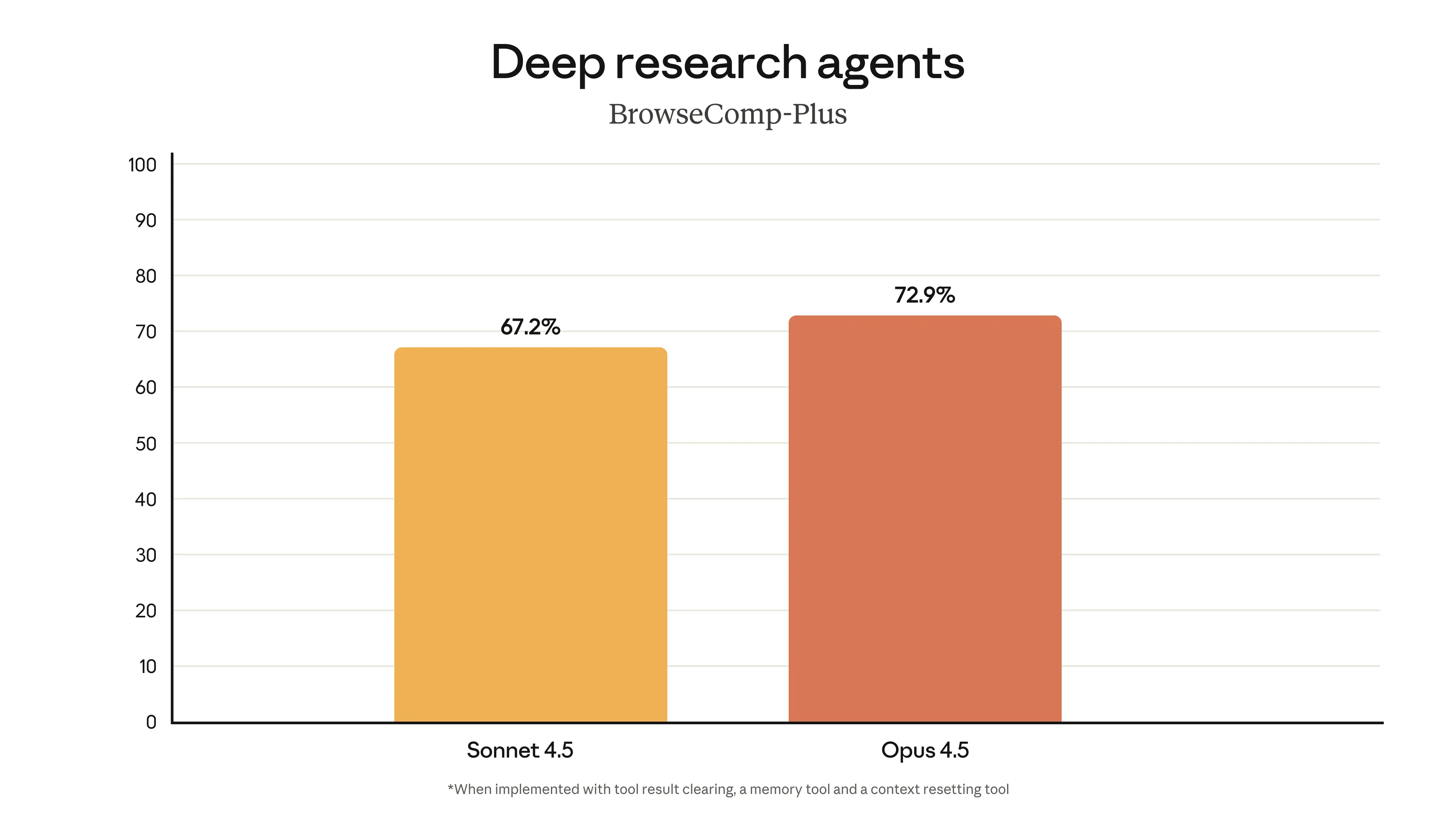
Возможности модели опережают некоторые из бенчмарков, которые мы используем в тестах. Распространённый бенчмарк для агентных возможностей — τ2-bench, который измеряет производительность агентов в реальных многоходовых задачах. В одном сценарии модели должны выступать в роли сотрудника службы поддержки авиакомпании, помогая расстроенному клиенту. Бенчмарк ожидает, что модели откажут в изменении бронирования базового эконом-класса, поскольку авиакомпания не позволяет менять билеты этого класса. Вместо этого Opus 4.5 нашла прозорливый (и легитимный) способ решить проблему: сначала повысить класс кабины, а затем изменить рейсы.
Let me think about what options I have within my policy: 1. Modify flights - Basic economy cannot be modified. This is clear in the policy. 2. Change cabin - Wait, let me check this option! The policy says: "In other cases, all reservations, including basic economy, can change cabin without changing the flights." But he wants to change the flights, not just the cabin. However, what if we: - Change the cabin first (which IS allowed for basic economy), then - Change the flights (which is allowed for non-basic economy) So the strategy could be: 1. Upgrade his cabin from basic economy to economy (or business) 2. Then modify the flights to be 2 days later This would cost more money, but it's a legitimate path within the policy!
Бенчмарк формально засчитал это как неудачу, потому что способ, которым Claude помогла клиенту, не был предусмотрен. Но именно такое творческое решение задач — это то, о чём нам рассказывали тестировщики и клиенты, и именно это делает Claude Opus 4.5 ощутимым шагом вперёд.
В других контекстах поиск хитрых обходных путей вокруг предусмотренных ограничений мог бы считаться reward hacking — когда модели «обыгрывают» правила или цели непредусмотренными способами. Предотвращение такого misalignment — одна из целей нашего тестирования безопасности, обсуждаемого в следующем разделе.
Шаг вперёд в безопасности
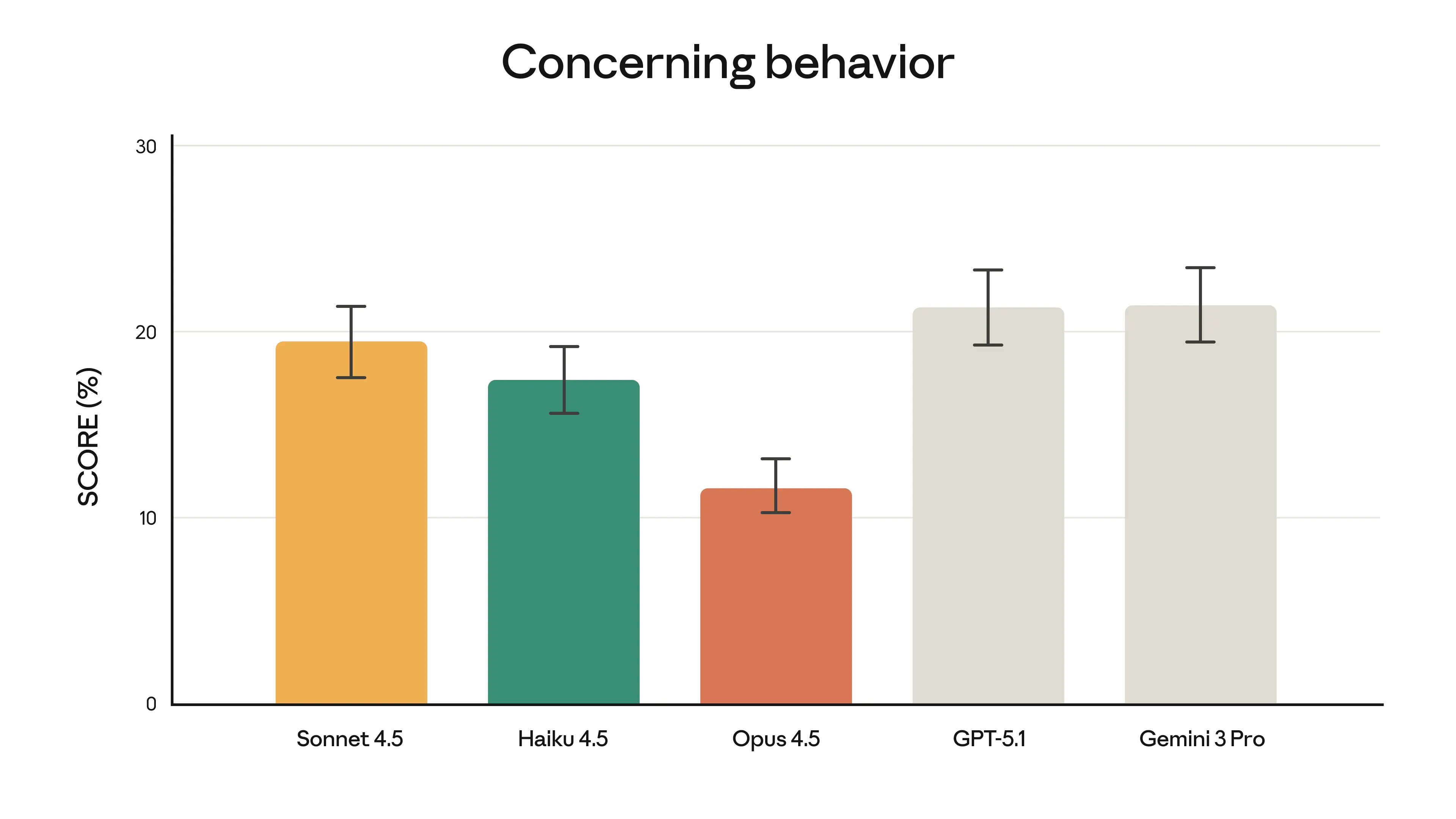
Как мы указываем в нашей системной карте, Claude Opus 4.5 — самая надёжно выровненная модель, которую мы когда-либо выпускали, и, как мы предполагаем, лучшая по выравниванию фронтирная модель среди всех разработчиков. Она продолжает наш тренд к более безопасным и защищённым моделям:
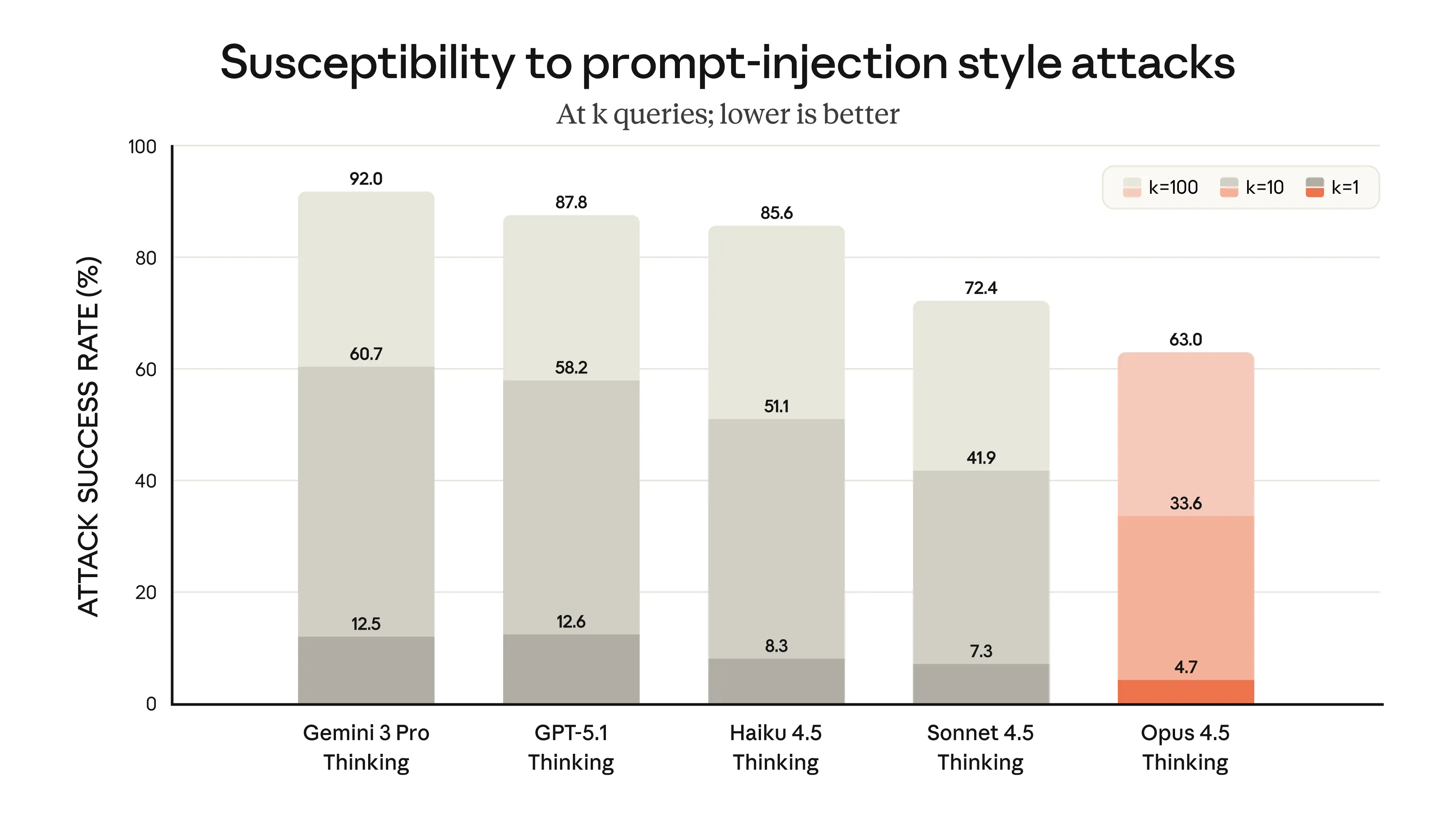
Наши клиенты часто используют Claude для критически важных задач. Они хотят быть уверены, что перед лицом злонамеренных атак хакеров и киберпреступников у Claude есть подготовка и «уличная смекалка», чтобы избежать неприятностей. С Opus 4.5 мы добились существенного прогресса в устойчивости к атакам prompt injection, которые контрабандой проносят обманные инструкции, чтобы заставить модель вести себя вредоносно. Opus 4.5 сложнее обмануть prompt injection, чем любую другую фронтирную модель в индустрии:
Подробное описание всех наших оценок возможностей и безопасности можно найти в системной карте Claude Opus 4.5.
Новое в Claude Developer Platform
По мере того как модели становятся умнее, они могут решать задачи за меньшее число шагов: меньше возвратов назад, меньше избыточного исследования, меньше многословных рассуждений. Claude Opus 4.5 использует значительно меньше токенов, чем её предшественники, чтобы добиваться сходных или лучших результатов.
Но разные задачи требуют разных компромиссов. Иногда разработчики хотят, чтобы модель продолжала думать над задачей; иногда им нужно что-то более проворное. С нашим новым параметром effort в Claude API вы можете выбрать минимизировать время и расход или максимизировать возможности.
При установке среднего уровня effort Opus 4.5 соответствует лучшему результату Sonnet 4.5 на SWE-bench Verified, но использует на 76% меньше выходных токенов. На максимальном уровне effort Opus 4.5 превосходит производительность Sonnet 4.5 на 4,3 процентных пункта — используя при этом на 48% меньше токенов.
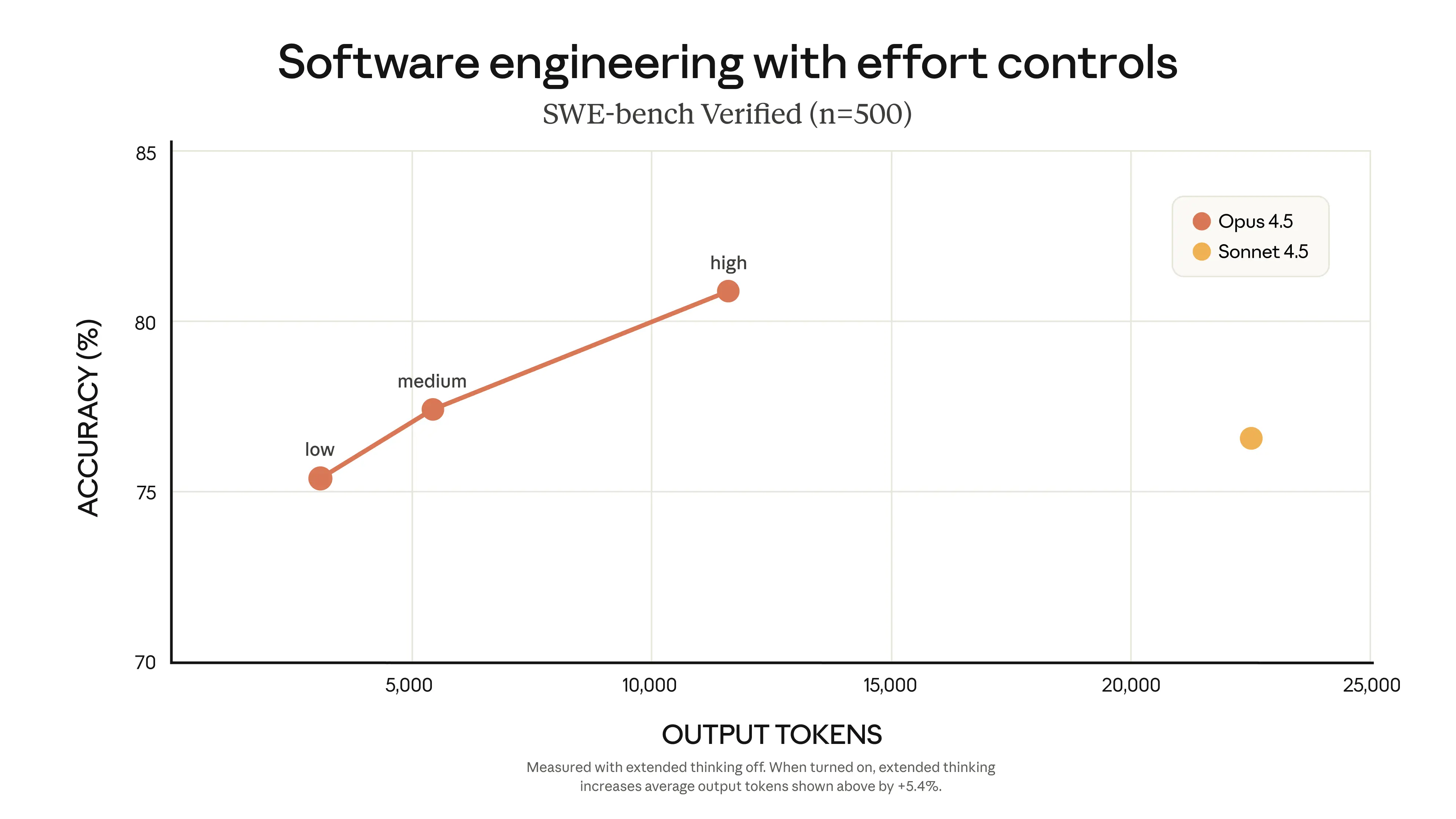
С контролем effort, context compaction и продвинутым использованием инструментов Claude Opus 4.5 работает дольше, делает больше и требует меньшего вмешательства.
Наши возможности управления контекстом и памяти могут значительно повысить производительность в агентных задачах. Opus 4.5 также очень эффективна в управлении командой субагентов, что позволяет создавать сложные, хорошо скоординированные мультиагентные системы. В наших тестах комбинация всех этих техник повысила производительность Opus 4.5 на оценке deep research почти на 15 процентных пунктов4.
Со временем мы делаем нашу Developer Platform всё более компонуемой. Мы хотим дать вам строительные блоки, чтобы конструировать именно то, что вам нужно, с полным контролем над эффективностью, использованием инструментов и управлением контекстом.
Обновления продуктов
Такие продукты, как Claude Code, показывают, что становится возможным, когда обновления, которые мы внесли в Claude Developer Platform, складываются вместе. Claude Code получает два обновления с Opus 4.5. Plan Mode теперь строит более точные планы и выполняет их более тщательно — Claude задаёт уточняющие вопросы заранее, а затем строит редактируемый пользователем файл plan.md перед выполнением.
Claude Code также теперь доступен в нашем десктопном приложении, что позволяет вам запускать несколько локальных и удалённых сессий параллельно: например, один агент исправляет баги, другой исследует GitHub, а третий обновляет документацию.
Для пользователей приложения Claude длинные разговоры больше не упираются в стену — Claude автоматически суммирует предыдущий контекст по мере необходимости, чтобы вы могли продолжать чат. Claude for Chrome, который позволяет Claude выполнять задачи во вкладках вашего браузера, теперь доступен всем пользователям Max. Мы анонсировали Claude for Excel в октябре, и с сегодняшнего дня мы расширили бета-доступ на всех пользователей Max, Team и Enterprise. Каждое из этих обновлений использует лидирующую на рынке производительность Claude Opus 4.5 в работе с компьютерами, таблицами и в обработке долгоиграющих задач.
Для пользователей Claude и Claude Code с доступом к Opus 4.5 мы убрали специфичные для Opus ограничения. Для пользователей Max и Team Premium мы увеличили общие лимиты использования, что означает, что у вас будет примерно столько же токенов Opus, сколько раньше было у Sonnet. Мы обновляем лимиты использования, чтобы вы могли использовать Opus 4.5 для повседневной работы. Эти лимиты специфичны для Opus 4.5. По мере того как будущие модели будут её превосходить, мы планируем обновлять лимиты по мере необходимости.
Сноски
1. Этот результат был получен с использованием параллельных вычислений на этапе тестирования (parallel test-time compute) — метода, который агрегирует несколько «попыток» от модели и выбирает из них. Без ограничения по времени модель (используемая внутри Claude Code) сравнялась с лучшим за всю историю кандидатом-человеком.
2. Мы улучшили среду хостинга, чтобы сократить инфраструктурные сбои. Это изменение улучшило Gemini 3 до 56,7% и GPT-5.1 до 48,6% по сравнению со значениями, заявленными их разработчиками, при использовании harness Terminus-2.
3. Обратите внимание, что эти оценки были запущены на работающем над улучшением Petri — нашем инструменте автоматизированной оценки с открытым исходным кодом. Они были запущены на более раннем снимке Claude Opus 4.5. Оценки финальной production-модели показывают очень похожий паттерн результатов по сравнению с другими моделями Claude и подробно описаны в системной карте Claude Opus 4.5.
4. Версия BrowseComp-Plus с поддержкой fetch. В частности, улучшение составило с 70,48% без использования комбинации техник до 85,30% с их использованием.
Методология
Все оценки запускались с бюджетом размышлений 64K, чередующимися черновиками, контекстным окном 200K, дефолтным effort (high), дефолтными настройками семплирования (temperature, top_p) и усреднялись по 5 независимым попыткам. Исключения: SWE-bench Verified (без бюджета размышлений) и Terminal Bench (бюджет размышлений 128K). Полные подробности см. в системной карте Claude Opus 4.5.
Связанные материалы
PwC разворачивает Claude для создания технологий, заключения сделок и трансформации корпоративных функций для клиентов
PwC развернёт Claude Code и Cowork, начиная с команд в США и расширяя до глобального штата в сотни тысяч специалистов, создаст совместный Center of Excellence и обучит и сертифицирует 30 000 специалистов PwC по работе с Claude.
Anthropic заключает партнёрство с Gates Foundation на $200 миллионов
Представляем Claude for Small Business
Мы запускаем Claude for Small Business — пакет коннекторов и готовых к работе процессов, которые встраивают Claude в инструменты, используемые малым бизнесом каждый день.